
Veri tabanı büyüdükçe, tek bir tablo üzerindeki veriyi fiziksel olarak bölümlere ayırmak (Partitioning), sorgu performansını artırmanın ve bakım süreçlerini kolaylaştırmanın en etkili yollarından biridir. Hash Partitioning, özellikle verinin belirli bir sütuna göre (genellikle Primary Key veya bir ID) rastgele ve dengeli bir şekilde dağıtılmasını sağlar. Bu yöntem, veriyi belirli aralıklara (Range) değil, bir hash algoritması sonucu çıkan değerlere göre böler.
| Avantajlar | Dezavantajlar |
| Veri farklı dosya gruplarına (Filegroups) dengeli dağılır, disk darboğazlarını önler. | Belirli bir aralıktaki verileri getir (Between/Range) sorguları ile tüm bölümleri tarayabilir (Partition Elimination gerçekleşmez). |
| Sorgular farklı partitionlar üzerinde aynı anda çalışarak hızlanır. | Çok sayıda partition, istatistik yönetimi ve index bakım süreçlerini karmaşıklaştırabilir. |
| Eski verileri partition bazlı silmek veya arşivlemek kolaydır. | Hash algoritması değiştirilirse verinin yeniden dağıtılması gerekir. |
Hash partitioning mantığını SQL Server’da kurmak için genellikle MOD operatörü ile bir Computed Column (hesaplanmış sütun) oluştururuz.
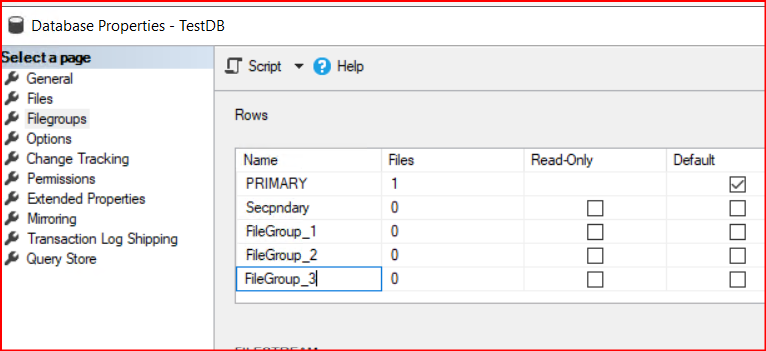
İlk olarak veritabanımız üzerinde filegroup oluşturuyoruz. İlgili değerleri belirli filegroup ve data file’a yazmak için.
USE [master]
GO
ALTER DATABASE [TestDB] ADD FILEGROUP [FileGroup_1]
GO
ALTER DATABASE [TestDB] ADD FILEGROUP [FileGroup_2]
GO
ALTER DATABASE [TestDB] ADD FILEGROUP [FileGroup_3]
GO
ALTER DATABASE [TestDB] ADD FILEGROUP [Secpndary]
GO
İlgili filegroupları script ile oluşturduk.
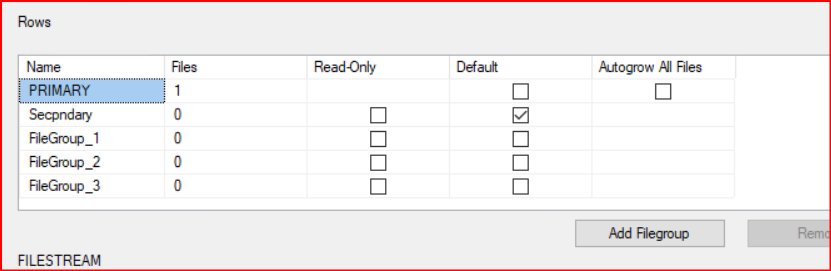
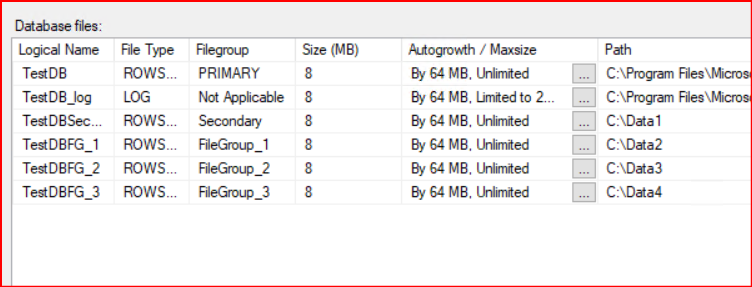
Oluşturulan Filegroup’lara data file ekleme işlemi yapılmaktadır.
USE [master]
GO
ALTER DATABASE [TestDB] ADD FILE ( NAME = N'TestDBFG_1', FILENAME = N'C:\Data2\TestDBFG_1.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FileGroup_1]
GO
ALTER DATABASE [TestDB] ADD FILE ( NAME = N'TestDBFG_2', FILENAME = N'C:\Data3\TestDBFG_2.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FileGroup_2]
GO
ALTER DATABASE [TestDB] ADD FILE ( NAME = N'TestDBFG_3', FILENAME = N'C:\Data4\TestDBFG_3.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FileGroup_3]
GO
ALTER DATABASE [TestDB] ADD FILE ( NAME = N'TestDBSecondary', FILENAME = N'C:\Data1\TestDBSecondary.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Secondary]
GO
Filegroup ve data file oluşturduktan sonra veriyi 0, 1, 2, 3 şeklinde bölecek fonksiyonu tanımlıyoruz.
RANGE LEFT veya RANGE RIGHT mantığında, sistem belirttiğiniz değerlerin arasına “duvarlar” örer. 4 parçalı bir yapıda MOD 4 işleminden sonuç olarak 0, 1, 2, 3 değerleri çıkar.
Yani 3 adet sınır noktası (0, 1, 2) veriyi toplamda 4 bölgeye ayırır.
Eğer 4 sınır değeri (0, 1, 2, 3) yazsaydınız, SQL Server bunu 5 parçaya ayırırdı:
| Sınır Noktaları | Oluşan Parça Sayısı |
| VALUES (0, 1, 2) | 4 Parça |
| VALUES (0, 1, 2, 3) | 5 Parça |
Eğer kodunuzda % 4 (yüzde 4) modunu kullanıyorsanız, PARTITION FUNCTION kısmında şu şekilde 3 değer bırakmanız tam olarak istediğiniz 4 parçayı oluşturur:
CREATE PARTITION FUNCTION [pf_Hash_Partition] (INT)
AS RANGE LEFT FOR VALUES (0, 1, 2);
| Hesaplanan Değer (Mod 4) | Partition No | Atanan Filegroup |
| 0 | Partition 1 | PRIMARY |
| 1 | Partition 2 | FileGroup_1 |
| 2 | Partition 3 | FileGroup_2 |
| 3 | Partition 4 | FileGroup_3 |
Kısacası, MOD 4 işlemi ile 0, 1, 2, 3 değerlerini üretiyorsanız, VALUES (0, 1, 2) yazmanız doğru olan yöntemdir. 3 değer, 4 bölge demektir.
CREATE PARTITION FUNCTION [pf_Hash_Partition] (INT)
AS RANGE LEFT FOR VALUES (0, 1, 2); -- 4 bucket (0,1,2,3) oluşturur
CREATE PARTITION SCHEME [ps_Hash_Partition]
AS PARTITION [pf_Hash_Partition]
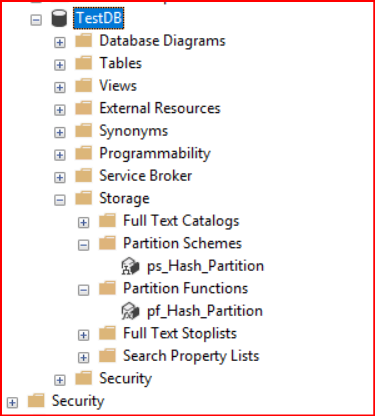
TO ([PRIMARY], [FileGroup_1], [FileGroup_2], [FileGroup_3]);Veritabanımızın Storage bölümünden oluşturduğumuz yapımızı görebiliriz.
SQL Server’da hashleme için ABS(CHECKSUM(ID)) % 4 mantığını kullanan bir Persisted kolon eklemek en yaygın yöntemdir.
CREATE TABLE HashTablosu (
ID INT NOT NULL,
Veri NVARCHAR(100),
-- ID'nin 4'e modu
HashKey AS (ABS(CHECKSUM(ID)) % 4) PERSISTED NOT NULL
) ON [ps_Hash_Partition](HashKey);
-- Partition yapısını kontrol edin
SELECT * FROM sys.partitions
WHERE object_id = OBJECT_ID('HashTablosu');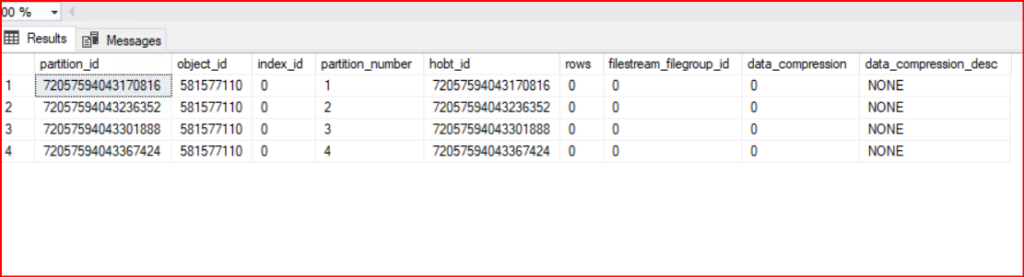
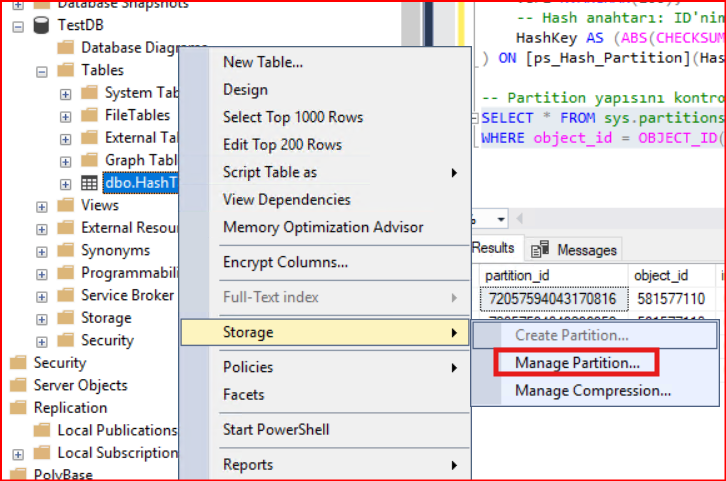
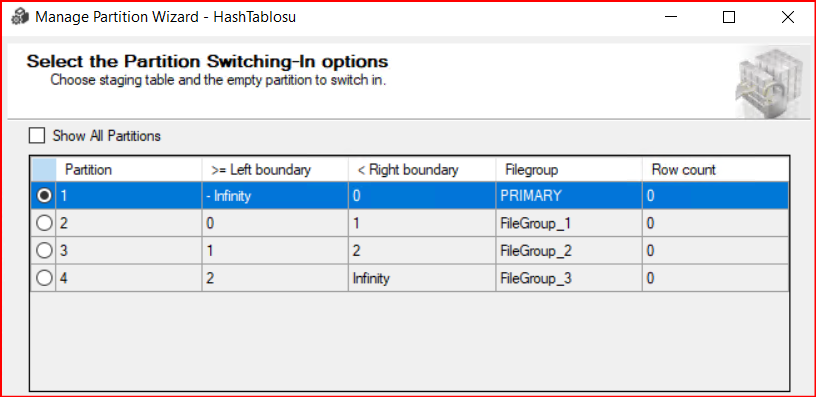
Tablomuzun üzerine sağ tıklayıp Storage bölümünde Manage Partition… bölümünde oluşturduğumuz partition yapısını detaylı bir şekilde görebiliriz.
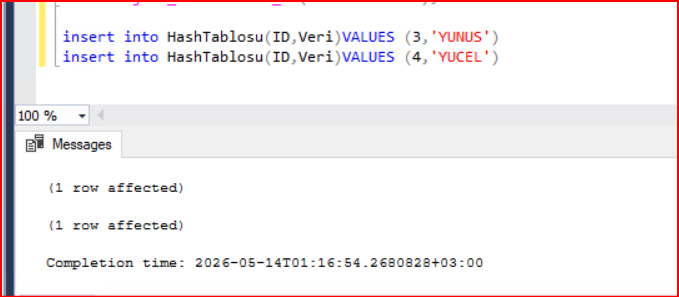
Tablomuza veri eklediğimizde ilgili partition grouplara kaydedildiğini aşağıdaki resimde görebiliriz.
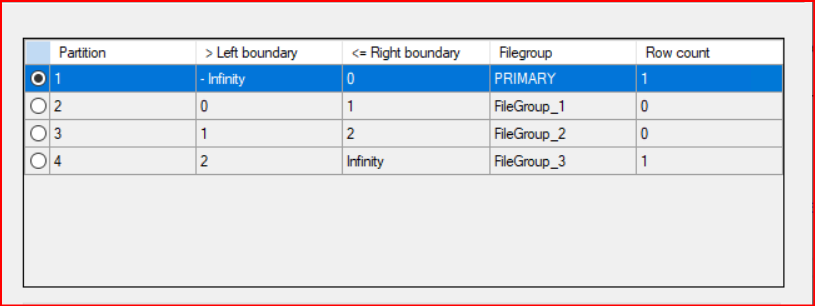
Hash partitioning, Hotspot (sıcak nokta) sorununu çözer. Örneğin, ardışık ID’ler (Identity kolonları) kullandığınızda, veriler sürekli son eklenen sayfaya yazılır. Hash yapısı ise gelen her yeni ID’yi rastgele bir bucket’a yönlendirdiği için, sistem genelindeki disk yazma yükü %25, %25, %25, %25 şeklinde 4 diske dengeli dağılır.
Eğer sorgularınızda WHERE ID = 123 gibi tekil değerler arıyorsanız, SQL Server “Partition Elimination” sayesinde doğrudan ilgili bölümü bulur ve çok hızlı yanıt verir. Ancak WHERE ID BETWEEN 100 AND 500 gibi aralık sorguları yaparsanız, veriler hashlenerek dağıtıldığı için tüm bölümler taranacaktır.
Hash partitioning, veri setiniz devasa boyutlara ulaştığında ve disk I/O’su bir darboğaz haline geldiğinde mükemmel bir çözümdür. Ancak, uygulamanızın sorgu desenlerini analiz etmelisiniz. Eğer yoğunlukla “nokta atışı” (point lookup) aramalar yapıyorsanız hash partitioning, “aralık” (range) aramalar yapıyorsanız Range Partitioning daha uygundur.
Başka makalede görüşmek dileğiyle..
Kötülüğe iyilikle karşılık verin.Fussilet-34