")
Geleneksel Always On Availability Groups (AG), tek bir Windows Server Failover Cluster (WSFC) yapısına bağlıdır. Distributed Availability Group (DAG) ise SQL Server 2016 ile hayatımıza giren ve farklı cluster yapıları arasındaki Availability Group’ları birbirine bağlayan “bir grubun grubu” mantığıyla çalışan özel bir mimaridir.
Neden DAG Kullanmalıyız:
- Cluster Bağımsızlığı: İki farklı lokasyondaki sunucuları tek bir cluster’a dahil etme zorunluluğunu (ve buna bağlı network karmaşasını) ortadan kaldırır.
- Coğrafi Yedeklilik (DR): Felaket kurtarma senaryolarında, ana merkezdeki cluster çökse bile diğer cluster tamamen bağımsız olduğu için ayakta kalır.
- Yüksek Ölçeklenebilirlik: Okuma amaçlı (Read-Only) replikaları farklı cluster’lara dağıtarak ana merkezin yükünü azaltır.
DAG özelliği SQL Server 2016 ve üzeri Enterprise Edition gerektirir. Ancak SQL Server 2022 ile birlikte seeding (veri senkronizasyonu) ve performans tarafında ciddi iyileştirmeler yapılmıştır.
Not: Alwayson yapısında tek sunucu üzerinde ag yapımızı oluşturmak için new availability group sekmesinden oluşturmak gerekmektedir.
Distributed AG yapısında iki tane listener olması gerekmektedir. Disk yollarının aynı olması önerilmektedir. Alwayson Auto Seeding modunun otomatik olması gerekmektedir.
Distributed Availability Group (DAG) yapısında farklı SQL Server versiyonlarını bir arada kullanabilirsiniz. Ancak bu genellikle versiyon yükseltme (upgrade) süreçleri için tercih edilen geçici bir yöntemdir.
SQL Server 2017’den 2022’ye doğru bir veri akışı (replikasyon) kurabilirsiniz. SQL Server’ın genel kuralı şudur: Düşük versiyondan yüksek versiyona veri gönderilebilir.
- Senaryo A (Mümkün): SQL Server 2017 (Primary Cluster) >SQL Server 2022 (Secondary Cluster).
- Senaryo B (İmkansız): SQL Server 2022 (Primary Cluster) >SQL Server 2017 (Secondary Cluster). SQL Server geriye dönük uyumlu değildir; yüksek versiyonda yazılan bir veritabanı düşük versiyonda açılamaz.
Eğer SQL Server 2017’den 2022’ye geçiş yaparsanız (failover), bu işlem tek yönlüdür. 2022 tarafı “Primary” olduktan sonra veritabanı seviyesi yükseleceği için tekrar 2017 tarafına geri dönemezsiniz (failback yapamazsınız).
Windows Cluster yapılarında işletim sistemi versiyonlarının da uyumlu olması önerilir. Farklı cluster’lar oldukları için işletim sistemleri farklı olabilir (Örn: Cluster 1 – Win 2016, Cluster 2 – Win 2022) ancak SQL Server’ın ilgili işletim sistemini desteklediğinden emin olmalısınız.
Özet Tablo
| Özellik | Durum | Not |
| 2017-> 2022 | ✅ Mümkün | Upgrade senaryoları için idealdir. |
| 2022 -> 2017 | ❌ İmkansız | Yüksek versiyondan düşüğe replikasyon yapılamaz. |
| Failback | ❌ Yok | 2022’ye geçince 2017’ye geri dönüş yapılamaz. |
| Cluster Yapısı | ✅ Ayrı | Her iki grup kendi cluster mekanizmasına sahiptir. |
Distrubeted ag oluştururken hangi sunucu üzerinde oluşturulmuşsa primary sunucusu olmaktadır. Diğer sunucu forwarded yapısındadır.
Avantajı:
Normal bir Availability Group yapısında, aynı cluster içindeki tüm node’ların aynı SQL Server versiyonuna sahip olması istenir. Ancak Distributed AG, iki farklı cluster’ı birbirine bağladığı için versiyon farklılıklarına izin verir.
Bu işlemleri yaparken Always On mimarisinde çalıişan 3 Node üzerinde geçekleştireceğiz. Sizler bu işlemleri FCI ve AO olan ortamda da Virtual Name ismi ile yapabilirsiniz.
1. Ortam (CLS01): Node1, Node2, Node3 | Listener: AGCorpList
2. Ortam (CLS02): Node4, Node5 | Listener: AGCorpDRList
Kuruluma başlamadan önce tüm replicalarda Automatic Seeding Mode‘un “Enabled” olduğundan emin olunmalıdır.
1. Adım: Registered Service (Ctrl+Alt+G) üzerinden Local Server Gruplarını doğrulayın.
2. Adım: Tüm Node’larda script çalıştırmak için yeni bir query ekranı açın.
3. Adım: Aşağıdaki sorgu ile her sunucuda Seeding modunu teyit edin:
SELECT seeding_mode_desc
FROM sys.availability_replicas
WHERE replica_server_name = @@ServernameDistributed Availability Group (DAG) mimarisinde temel kural şudur: Distributed yapıyı kurmadan önce, her iki cluster içindeki yerel Availability Group’ların (AG) halihazırda oluşturulmuş ve çalışır durumda olması gerekir.
Bunu bir “köprü” benzetmesiyle açıklarsak: DAG, iki farklı şehri (Cluster’ı) birbirine bağlayan bir otobandır. Otobanı inşa etmeden önce, her iki taraftaki şehir içi yolların (Yerel AG’lerin) hazır olması şarttır.
DAG komutunu çalıştırmadan önce şu hazırlıkları yapmış olmalısın:
- CLS01 (Ana Merkez): Burada AGCorp isminde bir AG oluşturulmuş olmalı. İçinde senkronize olan nodeların (Node1, Node2, Node3) ve bir Listener’ın (AGCorpList) bulunması gerekir.
- CLS02 (DR Merkezi): Burada da AGCorpDR isminde, CLS01’den tamamen bağımsız bir AG oluşturulmuş olmalı. Başlangıçta bu AG’nin içi boş olabilir (veritabanı içermez), ancak bir Listener’ı (AGCorpDRList) mutlaka olmalıdır.
4. adımdan önce 5. adımın yapılması gerkemektedir.
4. Adım: Distributed AG Oluşturma (CLS01 Üzerinde) CLS01 Cluster’ındaki Primary Node üzerinden (AGCorpList bağlantısı ile) DAG’ı oluşturuyoruz:
CREATE AVAILABILITY GROUP [AGCorpDistributed]
WITH (DISTRIBUTED) AVAILABILITY GROUP ON
'AGCorp' WITH (
LISTENER_URL = 'tcp://AGCorpList.domain.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC),
'AGCorpDR' WITH (
LISTENER_URL = 'tcp://AGCorpDRList.domain.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC);
GODistributed AG (DAG) kurarken sunucu isimlerini değil, mevcut AG’lerin Listener isimlerini birbirine bağlıyorsun.
Distributed AG’nin kendi özel bir Listener’ı (virtual name/IP) olmaz.
Distributed AG, zaten mevcut olan normal AG’lerin Listener’larını birer uç nokta (endpoint) olarak kullanır.
Süreci ve olası karmaşıklığı şu şekilde netleştirelim:
Mantıksal Ayrım
- Normal AG Listener’ı: Uygulamaların (Application) veritabanına bağlanmak için kullandığı isimdir (Örn: AGCorpList). Bu Listener, Cluster seviyesinde bir nesnedir.
- Distributed AG (DAG): Bu ise iki farklı AG arasındaki “kanal”dır. DAG oluştururken SQL Server’a dersin ki: “Sen veriyi CLS01’deki AGCorpList kapısından çıkar, CLS02’deki AGCorpDRList kapısına teslim et.”
NOT: Distributed AG oluştururken, yerel AG’nin (Local AG) sağlıklı ve tutarlı bir durumda olması gerekir. SQL Server, yerel AG’nin yapısını tam olarak doğrulayamadığında veya replicalar arası bir senkronizasyon sorunu olduğunda “locally exist” hatasını tetikleyebilir. Eğer sizin AG’niz 5022 portunu kullanacak şekilde ayarlandıysa ancak sunucudaki Firewall veya Endpoint tanımları 5023’e göre yapıldıysa, replicalar birbirine bağlanamaz (Kırmızı çarpı nedeni). Hedef sunucunun ilgili end point portona telnet çekildiğinde erişilebilir olup olmadığını görebiliriz.
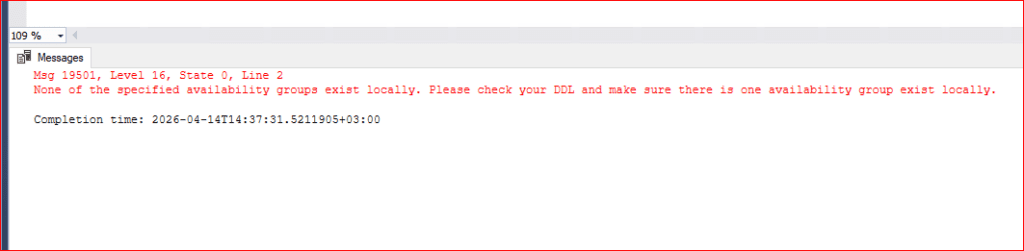
Yukarıdaki hata mesajını almaya devam ederseniz aşağıdaki komut ile ag yapınıza bir listener bağlı olup olmadığını kontrol etmeniz gerekmektedir.
SELECT
ag.name AS [AG_Name],
agl.dns_name AS [Listener_Name],
agl.port AS [Listener_Port]
FROM sys.availability_groups ag
LEFT JOIN sys.availability_group_listeners agl ON ag.group_id = agl.group_id;5. Adım: Direct Seeding (otomatik veritabanı senkronizasyonu) kullanıyorsan, 2. Cluster’daki (CLS02) sunucuların, 1. Cluster’dan gelen veriyi alıp kendi üzerinde otomatik olarak veritabanı yaratma yetkisine sahip olması gerekir.
Bu yetkiyi SQL Server Management Studio (SSMS) üzerinden şu şekilde veriyorsun:
- CLS02 (İkinci Cluster) üzerindeki her iki node’a da (Node4 ve Node5) tek tek bağlan.
- Security > Logins sekmesine git.
- Burada SQL Server servislerini çalıştırdığın Service Account‘u (veya Always On Endpoint’i hangi hesapla oluşturduysan o hesabı) bul.
- Sağ tıkla Properties de ya da yeni bir Query ekranı açıp şu komutu çalıştır:
-- Bu komutu CLS02'deki (Forwarder tarafındaki) her iki sunucuda da çalıştırmalısın
USE [master]
GO
GRANT CREATE ANY DATABASE TO [KULLANICI_ADINIZ];
-- Buradaki kullanıcı genelde SQL servis hesabıdır (örn: DOMAIN\sql_svc)
GOEğer bu yetkiyi vermezsen, DAG kurulur ancak veritabanı senkronizasyonu başlamaz. SQL Server loglarında “The user does not have permission to create a database” hatası görürsün. Bu yetki sayesinde 1. Cluster “Ben veriyi gönderiyorum, sen orada bu isimle bir DB oluştur” dediğinde, 2. Cluster’daki SQL buna izin verir.
6. Adım: DAG’a Katılma (CLS02 Üzerinde) CLS02 üzerindeki Primary Node’a (AGCorpDRList) bağlanarak DAG’ı “Alter” ediyoruz:
ALTER AVAILABILITY GROUP [AGCorpDistributed]
JOIN AVAILABILITY GROUP ON
'AGCorp' WITH (
LISTENER_URL = 'tcp://AGCorpList.domain.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC),
'AGCorpDR' WITH (
LISTENER_URL = 'tcp://AGCorpDRList.domain.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC);
GOYukarıdaki işlemlerden sonra kurulum her iki sunucu yapılmış olunur.
DAG Failover İşlemleri
7. Adım: Senkronizasyon modunu güncelleyin. Failover öncesi her iki tarafta (Primary ve Forwarder) şu scripti çalıştırarak yapıyı Synchronous moda çekin:
ALTER AVAILABILITY GROUP [AGCorpDistributed]
MODIFY AVAILABILITY GROUP ON
'AGCorp' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT),
'AGCorpDR' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);
GO8. Adım: Global Primary (CLS01) üzerinden rolü secondary’e çekin:
ALTER AVAILABILITY GROUP AGCorpDistributed SET (ROLE = SECONDARY);
GO9. Adım: Veri kaybı olmaması için LSN numaralarının eşitlendiğinden emin olun:
SELECT ag.name, drs.database_id, db_name(drs.database_id) as database_name,
drs.synchronization_state_desc, drs.last_hardened_lsn
FROM sys.dm_hadr_database_replica_states drs
INNER JOIN sys.availability_groups ag ON drs.group_id = ag.group_id;10. Adım: Hedef cluster (CLS02) üzerinde failover işlemi gerçekleştirilir:
ALTER AVAILABILITY GROUP AGCorpDistributed FORCE_FAILOVER_ALLOW_DATA_LOSS;DAG yapıları Cluster Manager’da görünmez. Takip için DMV’ler kullanılır:
AGCorpList üzerinden bağlanıyoruz ve yeni bir query ekranı açıyoruz. Hangi replicaların Hangi Distributed AG’ye bağlı olduğu bilgisini aşağıdaki script yardımı ile bulabilirim.
SELECT
ag.[name] AS [Distributed AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
WHERE ag.Is_Distributed = 1
GOGlobal Primary üzerinden yeni pencere açarak, Distributed AG’nin sağlık durumu ve sync mode’unu gözlemleyebiliriz.
SELECT r.replica_server_name, r.endpoint_url, r.failover_mode_desc,
rs.connected_state_desc, rs.role_desc, rs.operational_state_desc,
rs.recovery_health_desc,rs.synchronization_health_desc,
r.availability_mode_desc
FROM sys.dm_hadr_availability_replica_states rs
INNER JOIN sys.availability_replicas r
ON rs.replica_id=r.replica_id
ORDER BY r.replica_server_name;DAG Remove
Öncelikle bu işlemi yaptığımızda Distributed AG’yi tamamen sileceğimiz bilmemiz gerekmektedir. O yüzden bu işlemi başlatmadan önce gerekli uzmanlardan destek almanızda fayda var.
1.Adım: Distributed AG yapısında secondary (Forwarder) olan ortamda Distributed AG’yi düşürüyoruz. Bu işlemi script ile yapıyoruz.
2.Adım: Forwarder ortamından kaldırılan Distributed AG, Global Primary olan ortamdan kaldırmak içinde AGCorDRList ortamına bağlandıktan sonra distributed AG’yi drop ederek 2 farklı cluster arasındaki bağlantıyı tamamen koparıyoruz.
Script Çalıştırmadan Önce;
Script Çalıştırdıktan Sonra;
Database Remove in DAG
DAG ortamnın bulunduğu bir AlwaysOn mimarisinde bir database’i secondary node üzerinden kaldırmak istersek Primary AG altından ilgilii database’i remove ederek yapabiliriz. Fakat unutulmaması gereken önemli nokta Primary node üzerinden çıkardığımız database forwarder olarak adlandırdığımız Distributed AG’nin secondary ortamından silinmeyecektir. Eğer bu ortamdan yada bu ortamın secondary’lerinden kaldırmak istiyorsak ilgili ortamda primary olan AG altından remove ederek kaldırabiliriz.
Başka makalede görüşmek dileğiyle..
“Öyle ise emrolunduğun gibi dosdoğru ol.” Hud-112