
Bu makalede mssql server üzerinde ikinci bir AG oluşturma konusuna değinmiş olacağız. Bu yapıya gerek duymamızın sebebi bazen tek AG altında bulunan veritabanı sayısının fazlalığından dolayı AG ve Failover cluster bazında sıkıntıya sebebiyet vermektedir. AG altında bulunan veritabanlarımızı bölerek veritabanlarının farklı sunucular üzerinde çalışılması sağlanır. Bu sayede tüm kullanıcıların aynı sunucu üzerine yük bindirmeyip yük devretme işlemini farklı sunucular üzerine yaymış olacağız.
Microsoft SQL Server ekosisteminde buna “Multi-AG” veya “Multi-Instance AG” yaklaşımı diyoruz.
Özellikle yüksek işlem hacmine sahip (high-throughput) sistemlerde, tüm yumurtaları aynı sepete koymamak sistemin genel sağlığı (health check) için kritiktir.
1. Worker Thread Yönetimi
Her AG’nin kendine ait worker thread’leri vardır. Varsayılan olarak SQL Server, toplam thread sayısını dinamik yönetse de, çok fazla veritabanı tek bir AG altındaysa thread’ler arasındaki “context switching” (bağlam değiştirme) performansı düşürebilir. İkinci bir AG, bu iş yükünü mantıksal olarak ayırır.
2. Log Transport Verimliliği
Her AG’nin kendi Log Writer ve Log Scanner süreçleri bulunur. Veritabanlarını böldüğünüzde, log gönderme (redo) işlemleri paralel olarak daha sağlıklı yürütülür. Tek bir AG’deki çok büyük bir veritabanının log kuyruğu, diğer küçük veritabanlarının senkronizasyonunu geciktiremez.
3. Kaynak İzolasyonu (Resource Governor)
Eğer ikinci bir AG oluşturuyorsan, bu AG’lerin farklı IP adresleri ve Listener isimleri olacaktır. Bu sayede uygulama tarafında yükü sadece sunucu bazlı değil, servis bazlı da bölebilirsin.
4. Quorum ve Cluster Limitleri
Windows Failover Cluster (WSFC) tarafında çok fazla veritabanının tek bir “Resource Group” altında olması, failover (yük devretme) süresini uzatabilir. İkinci bir AG ile bu kaynak gruplarını küçülterek failover süresini (RTO – Recovery Time Objective) optimize etmiş olursunuz.
Çoklu AG Yapısının Faydaları: Her AG bağımsız worker thread pool kullanır. Her AG kendi worker thread pool’una sahiptir, CPU contention önlenir. AG’ler arası memory pressure riski azalır, predictable performance sağlanır. Log flush ve read işlemleri birbirini etkilemez. Kritik DB’ler için daha agresif sync commit kullanılabilir. Bir AG maintenance’de iken diğerleri servise devam eder. Donanım/network hatası sadece bir AG’yi etkiler. AG bazlı backup işlemleri yapılmaktadır.
Not: Her AG Listener’ı aynı portu (varsayılan 1433) kullanabilir ancak IP’lerinin farklı olması gerekir. Alternatif olarak farklı portlar atanmalıdır.
Not: Her yeni AG, az da olsa SQL Server üzerinde ek bir bellek yükü (overhead) oluşturur.
1. AG Üzerindeki Thread Sayısı ve Kapasite
SQL Server, AG işlemleri için dinamik bir thread havuzu kullanır. Her AG veritabanı ve her replica için belirli sayıda thread ayrılır.
Maksimum Thread Sayısı: sys.dm_os_sys_info üzerinden aldığın max_workers_count, tüm SQL Server instance’ın kullanabileceği toplam thread sınırıdır. AG, bu havuzun tamamını değil, sadece ihtiyacı olan kadarını kullanır.
AG Kapasite Hesabı: Genellikle SQL Server, AG worker thread’lerini şu formüle göre yönetir:
- Log Writer: Her AG veritabanı için 1 adet.
- Log Pool Consumer: Her replica/veritabanı çifti için 1 adet.
- Secondary Scan/Redo: İkincil sunucuda verileri işlemek için kullanılan thread’ler.
SQL Server’da her AG objesi belli bir “işçi” (worker) grubuna ihtiyaç duyar. Şöyle düşün:
- Log Writer: Her veritabanı için 1 thread. (AG içinde 5 veritabanı varsa = 5 thread).
- Log Pool Consumer: Her Replica (Sunucu) için veritabanı başına 1 thread.
- Redo Thread: Bu ikincil (Secondary) sunucuda çalışır. Her veritabanı için genellikle 1 ana redo thread’i bulunur (Parallel Redo açıksa bu sayı artar).
Örnek: 1 Primary + 2 Secondary sunucun var. AG içinde de 5 veritabanı var. Primary sunucuda: 5 (kendi log writer’ları) + 10 (2 secondary x 5 DB) = 15 thread sadece log gönderimi için harcanır.
Özetle: Veritabanı sayınız ve bağlı olan sunucu (replica) sayınız arttıkça, SQL Server’ın arka planda “sabit” olarak harcadığı thread sayısı katlanarak artar.
Max worker thread sayısını bulmak için aşağıdaki komut kullanılmaktadır.
SELECT max_workers_count FROM sys.dm_os_sys_info;Availability group üzerinde worker tread sayısını aşağıdaki komut ile görebiliriz.
SELECT
task_address,
task_state,
context_switches_count,
pending_io_count,
scheduler_id
FROM sys.dm_os_tasks
WHERE worker_address IN (
SELECT worker_address FROM sys.dm_os_workers
WHERE worker_address IS NOT NULL
)
AND (task_address IN (SELECT task_address FROM sys.dm_hadr_availability_replica_states)
OR task_address IN (SELECT task_address FROM sys.dm_hadr_database_replica_states));
Thread dağılımı “yük bazlı” ve “veritabanı sayısı bazlı” yapılır. Eğer iki AG’niz varsa:
- Yük (Workload): AG1 içindeki veritabanlarında saniyede 100 MB log üretilirken, AG2’de sadece 1 MB üretiliyorsa; SQL Server doğal olarak AG1’in Log Writer ve transport süreçleri için daha fazla aktif worker thread (veya daha sık CPU döngüsü) ayıracaktır.
- Veritabanı Sayısı: AG1’de 10, AG2’de 2 veritabanı varsa, AG1 mimari gereği daha fazla thread (her veritabanı için ayrı log writer vb.) tüketecektir.
3. Dikkat Etmen Gereken “Thread Starvation” Durumu
Eğer sistemindeki toplam thread sayısı (max_workers_count) dolmaya başlarsa, AG threadleri diğer kullanıcı sorgularıyla rekabet etmek zorunda kalır. Bu durum AG senkronizasyonunda gecikmelere (latency) neden olur.
Önemli Not: AG thread’lerini manuel olarak bir AG’ye “rezerve” edemezsin. SQL Server bunu otomatik yönetir. Ancak, işlemcinizdeki çekirdek (core) sayısı arttıkça max_workers_count otomatik olarak artar ve AG daha rahat çalışır.
SSMS üzerinde Availability Groups üzerine sağ tıklayıp New Availability Group.. diyiyoruz. Neden ilk seçeneği seçmedik çünkü ilk seçeneği seçersek AG kurulumu daha detaylı bir şekilde gerçekleşir. Biz sadece bir AG oluşturmak istediğimiz için herhangi bir veritabanı ekleme işlemi yapılıp yapılması tercihimize bırakılır. Wizard seçeneği seçilmişse veritabanı eklemek zorunludur. Detaylı bir şekilde kurulum yapmak isterseniz sayfamızda bulunan Alwayson makalesi okunabilir.
Gelen ekranda Availability group name kısmında yeni oluşturacağımız AG yapımıza bir isim veriyoruz. Diğer tüm bölümleri sayfamızda Always on makalelerinde detaylı bir şekilde görebiliriz.
Not: New Availability Group.. kısmında eklenen nodların endpoint kısmı farklı olabilir. Dikkat edilmesi gerekmektedir.

Yukarıdaki dikkat ederseniz Availability Databases kısmında veritabanı ekleme işlemi yapılabilir. Bu tamamen bizim tercihimize bırakılmış bir yapı olduğunu görmüş oluyoruz. Seeding mod açıksa veritabanı kendiliğinden secondary sunucusuna restore işlemi yapılmaktadır.
Yukarıdaki işlemleri tamamladıktan sonra oluşturulan AG altında Availability Replicas kısmında secondary olan nodun üzerinde çarpı işareti görünürse ilgili replicanın join edilmesi gerekmektedir.
Yük dağılımı yapılması için ilgili AG altında yeni bir listener yapısının eklenmesi gerekmektedir. Oluşturulan bu listener Active directory’de ilgili OU altına taşınır. Listener properties ekranından Cluster’ın ve sql server servisinin ilgili listener altında Full control yetkisi verilmesi gerekmektedir.

Yukarıdaki tüm adımları yaptıktan sonra AG23 altında bulunan TEST1 veritabanının yeni oluşturduğumuz AGTEST availability groups üzerine dahil edilmesi gerekmektedir.

Test1 veritabanına sağ tıklayıp Remove Database from Availability Group.. diyerek İlgili veritabanını AG altından çıkarıp yeni oluşturduğumuz AG altına ekleme işlemlerini yapıyoruz.
Daha sonra yeni AG altında Availability Databases sekmesinde Add Database.. diyiyoruz..

İlgili veritabanı seçildikten sonra hedef sunucuya bağlanıp veritabanımız hedef sunucuda bulunduğu için Join only veya Skip intial data sysnchronization seçenekleriyle ekleyebiliriz.

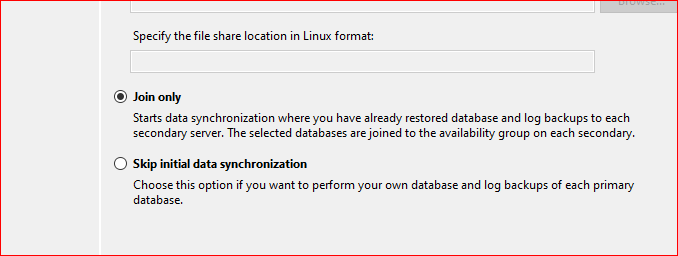
Secondary sunucusunda veritabanı hemen dahil olmuş oldu. Join only dersek veritabanı hemen dahil olur. Skip intial data sysnchronization seçeneği seçilirse manuel join işleminin yapılması gerekmektedir.
Daha sonra Failover işlemi yaptıktan sonra artık veritabanın hepsi tek bir sunucu üzerine gelmeyip birden fazla AG üzerine dağılmasını sağlayacaktır.

Primary üzerinde olan ag altından veritabanı çıkarılır. Yeni ag altına skip veya join only ile seçilip eklenir. Listener eklenmesine gerek yoktur. Sadece failover işlemi listener olmadığı için manuel yapılması gerekmektedir. Büyük veritabanların biraz beklenmesi gerekmektedir. Çünkü veritabanının secondary sunucularında restoring moduna düşmediğinden join only hata verir. Script ile AG üzerine bir database eklendiğinde default olarak auto seeding ile eklenir. Database secondary sunucusunda olduğu için hataya sebep verir. Dikkat edilmesi gerekir.
Not: Sql serverda AG yapısının çalışıp çalışmadığını anlamak için AG yapımıza boş bir veritabanı eklenir. Eğer ekleniyorsa AG yapımız çalışıyor demektir. Bu yapı aslında ag altında bulunan diğer veritabanlarının check edilmesine sebebiyet verecek. Kendi içerisinde check yapar. Diğer db lerde not sync den syncing veya end takısına geçer. İkinci yapılacak işlem AG den bir küçük db çıkartılır. Tekrar eklendiği zaman secondary sunucusundaki bağlantı kopukluğu gitmektedir.
Ola hallengrenn scriptleri kullanıyorsa yeni oluşturduğunuz ag içinde backupları doğru şekilde alacaktır. Joblarımızda Ag kontrol şartının kaldırılması gerekmektedir. Yeni oluşturulan ag altındaki veritabanlarına son kullanıcının secondary sunucuna gitmesi isteniyorsa ag propertiesdan readable read ifadesinin açılması gerekmekte. İnstance altında bulunan başka ag nin read only routing yönlendirme ekranını kullanır. Yeni oluşturulan Ag altında bu yapının oluşturulmasına gerek yoktur. Ayrıca backup için ag properties den backup refences bölümünde ayarlanması gerekmektedir.
Başka makalede görüşmek dileğiyle..
“Şüphesiz, Rabbin sana verecek ve sen de hoşnut olacaksın.”. Duha Süresi-5 Ayet