
Bu makalede AlwaysOn’a eklenmiş bir veritabanında database’in pathlerinin yanlışlıkla farklı yerlerde olması ve bu yolların aynı yere nasıl alınacağını görmüş olacağız.
Sql server AlwaysOn’da best practices olarak primary ve secondary’de oluşturulan databaselerin aynı pathlerde olmasını öneriyor ama database filelarının olduğu klasörler farklı olabilir bunları tekrar aynı path’e çekmek istersek aşağıdaki yöntemler izlenir. Data file farklı yerde olabilir ama primary ve secondary sunucularında aynı pathlerin olması gerekiyor. Failover anında sıkıntı yaşamamak içindir.
AlwaysOn yapısında Primary sunucuda yapılan her türlü fiziksel değişiklik (dosya ekleme, boyut büyütme vb.), işlem günlükleri (Transaction Logs) aracılığıyla Secondary sunuculara iletilir. Eğer sistemin temel dizin yapısı sunucular arasında farklılık gösteriyorsa, otomasyon ve senkronizasyon mekanizmaları sekteye uğrar.
Temel Risk Faktörleri
- Otomatik Seeding (Automatic Seeding) Arızası: Yeni nesil SQL Server sürümlerinde, veritabanını ikincil sunucuya taşımak için kullanılan otomatik seeding yöntemi, dosya yolları farklı olduğunda hedef dizini bulamaz ve hata vererek işlemi sonlandırır.
- Manuel Veritabanı Ekleme Zorluğu: Farklı dizin yapılarında, backup-restore işlemleri sırasında her seferinde MOVE komutu ile manuel yol tanımı yapmak zorunludur. Bu durum, yönetimsel karmaşayı ve hata payını artırır.
Failover Sonrası Ortaya Çıkan Kritik Senaryo
Dosya yollarının farklı olması, sistem normal çalışırken bir sorun teşkil etmiyor gibi görünebilir. Ancak asıl kriz, bir Failover (rol değişimi) anında ve sonrasında yaşanır.
Senaryo Analizi:
- Hizmet Kesintisi: Node A (Primary) beklenmedik bir şekilde çöker. Sistem otomatik olarak Node B’yi (Secondary) yeni Primary yapar.
- Yeni Primary’nin Durumu: Node B, dosyaları kendi yerel yolunda (Örn: D:\SQLData\) bulur ve hizmet vermeye başlar. Buraya kadar her şey normaldir.
- Eski Primary’nin Dönüşü: Node A tamir edilip ayağa kalktığında artık bir “Secondary Replica”dır. Senkronizasyon gereği Node B’den gelen logları işlemeye çalışır.
- Çakışma Noktası: Node A, kendi metadata kayıtlarında dosyaları orijinal yolunda (Örn: F:\Data\) arar. Eğer dosyalar bu yolda değilse veya sistem bu yolu tanımıyorsa, veritabanı log kayıtlarını işleyemez (Redo hatası).
Bu durum sonucunda veritabanı RECOVERY PENDING veya SUSPECT moduna düşer. Senkronizasyon tamamen kopar ve sistem manuel müdahale edilene kadar yedeksiz (unprotected) kalır.
Yeni Veri Dosyası (Add File) Ekleme Sorunu
Sistemin en zayıf halkası, veritabanına yeni bir veri dosyası (NDF) veya Filegroup eklendiği andır. Primary üzerinde yeni bir dosya oluşturulduğunda, SQL Server bu komutu tüm replicalara gönderir.
Secondary sunucu, Primary’deki dosya yolunun aynısını kendi üzerinde oluşturmaya çalışır. Eğer o harf veya dizin Secondary’de mevcut değilse, veritabanı anında devre dışı kalır. Bu durum, planlanmamış ciddi downtime (kesinti) sürelerine yol açar.
| Path’ler Aynı İse | Path’ler Farklı İse |
|---|---|
| Automatic Seeding sorunsuz çalışır. | Automatic Seeding çalışmaz, hata verir. |
| Backup/Restore işlemleri doğrudan, MOVE olmadan çalışır. | Backup/Restore işlemlerinde mutlaka manuel MOVE komutu yazmak gerekir. |
| Failover/Role Değişimleri sorunsuz gerçekleşir. Dosya yolları tutarlı olduğu için her sunucu dosyayı doğru yerde arar. | Failover Sonrası eski primary kurtarıldığında dosyaları bulamaz, senkronizasyon bozulur. Database suspect/recovery pending durumuna düşebilir. |
| Yönetim ve Otomasyon çok daha basittir. Script’ler ve bakım planları tüm sunucularda aynı şekilde çalışır. | Yönetim karmaşıklaşır, her sunucu için özel script ve düzenleme gerekir. |
| Best Practice‘e uygundur. | Best Practice’e aykırıdır, potansiyel sorun kaynağıdır. |
Özetle:
- Failover olduğunda, YENİ PRIMARY (eski secondary) kendi dosya yolunu kullanır ve SORUNSUZ çalışır.
- Asıl sorun, ESKİ PRIMARY (artık yeni secondary) tekrar çevrimiçi olduğunda ortaya çıkar. Çünkü o hâlâ kendi eski dosya yolunu kullanmaya çalışır ve dosyaları bulamaz.
Not: Disk yollarının farklı olması başlangıçta herhangi bir sorun teşkil etmez. Ama yeni bir data file veya file group oluşturulacağı zaman veritabanı suspect moda düşüyor. Neden primary yeni data file ekler bunu log dosyasıyla secondary sunucuya yollamaktadır. Secondary ilgili dosyayı bulamaz suspect moduna düşmektedir.
S1 sunucumuz Primary S2 sunucumuz ise secondary:
Şimdi primary sunucumuzda aşağıdaki komutları çalıştırdığımızda mdf ve ldf data fileların oluştuğu pathleri görmekteyiz.
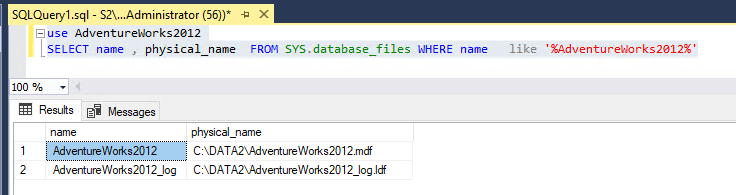
Secondary sunucumuzda aşağıdaki komutları çalıştırdığımızda mdf ve ldf data fileların oluştuğu pathleri görmekteyiz.
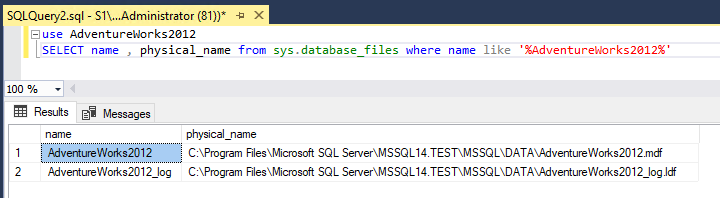
Dikkat edersek iki sunucuda data fileların yolları farklı, databaselerimiz çoğu böyleyse bir süreden sonra içinden çıkılamaz bir hal alabilir.
Genellikle küçük veritabanlarımda bu işlemi kullanmaktayım.(250 GB)
1.ADIM:
Secondary sunucumuzda ilgili veritabanı Availibility Databases sekmesinden çıkarılır. Aslında bu adımlarada gerek yok primary’den çıkartsak secondary sunucusundan çıkarmamıza gerek kalmıyor.

Suspend Data Movement yapıldıktan sonra Remove Secondary Database sekmesine tıklanıp veritabanı AG’den çıkartılır. Veritabanı Suspend denilmeden Remove komutu ilede hemen çıkartılabilir.

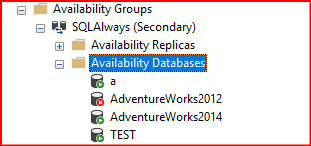
AG’den çıkartılmış veritabanı Secondary sunucusundan silinir. Tabi yukarıda çarpı işareti olarak göstermesinin sebebi primary’de AG altında çıkartılmamış. Sadece suspect moduna alınmış. AG altında çıkarttıktan sonra secondary sunucusundan da silindiğini görmüş oluyoruz. Çıkarılan veritabanı AdventureWorks2012 veritabanıdır.

Not: Detach yöntemide yapılarak veritabanı çıkarılabilir. Veritabanının sql server’la bağlantısını kestikten sonra path yolları manuel bir şekilde değiştirebilir.

Secondary sunucusundan tamamen veritabanımızı yok ettik.
2. ADIM
Bu adımda ise önceden elimizde bulunan(yada primary sunucusundan yeni alınan ) full backup’ı secondary sunucusuna No Recovery modundan restore işlemini gerçekleştiriyoruz.


Full backup’ı secondary sunucusuna restore yaptıktan sonra PRİMARY sunucusundan sırasıyla dif backup ve log backup işlemleri gerçekleştiriyorum. Log backup’a gerek duymadan en son diff alınsada yeterli aslında.

Almış olduğum dif ve log backup’ı secondary sunucusuna no recovery mode’da restore ediyorum tabi bu restore işlemleri sırasında yeni path’imide belirtmiş oluyorum.
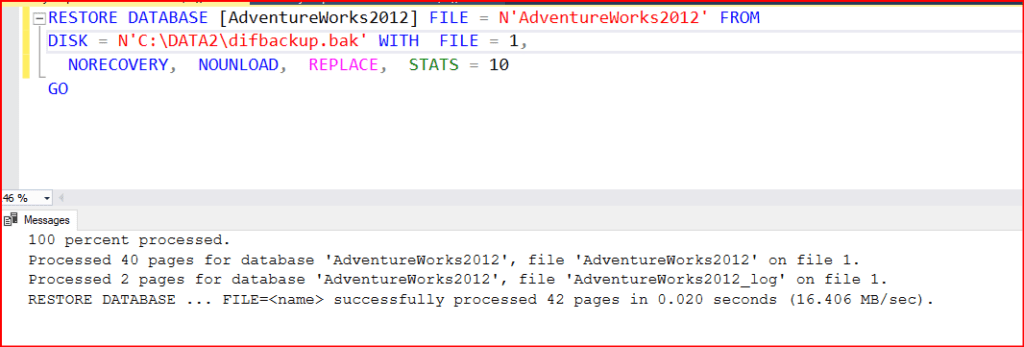
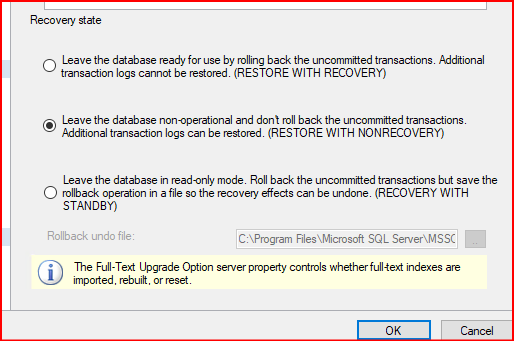
Diff backup’ıda yükledikten sonra log backup’ıda yüklüyorum no recovery modda aslında en son diff backup aldıktan sonra log backup’ı restore etmeye gerek yok.
Database’i secondary sunucusunda restoring moduna aldıktan sonra primary sunucusunda AlwaysOn Databases kısmından ilgili database join only ile AG’ye katıyorum. AlwaysOn’da seeding modu açıksa kendisi senkron oluyor.
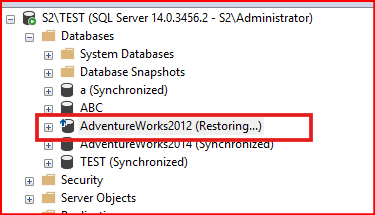
Primary sunucusunda ilgili veritabanını AG altından çıkartmıştık. Şimdi tekrardan primary sunucusunda AdventureWorks2012 database’ini AG altına alalım.
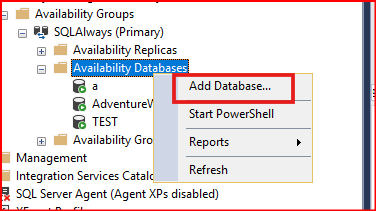
Add Database diyiyoruz. Gelen ekranda Next deyip bir sonraki aşamaya geçiyoruz.
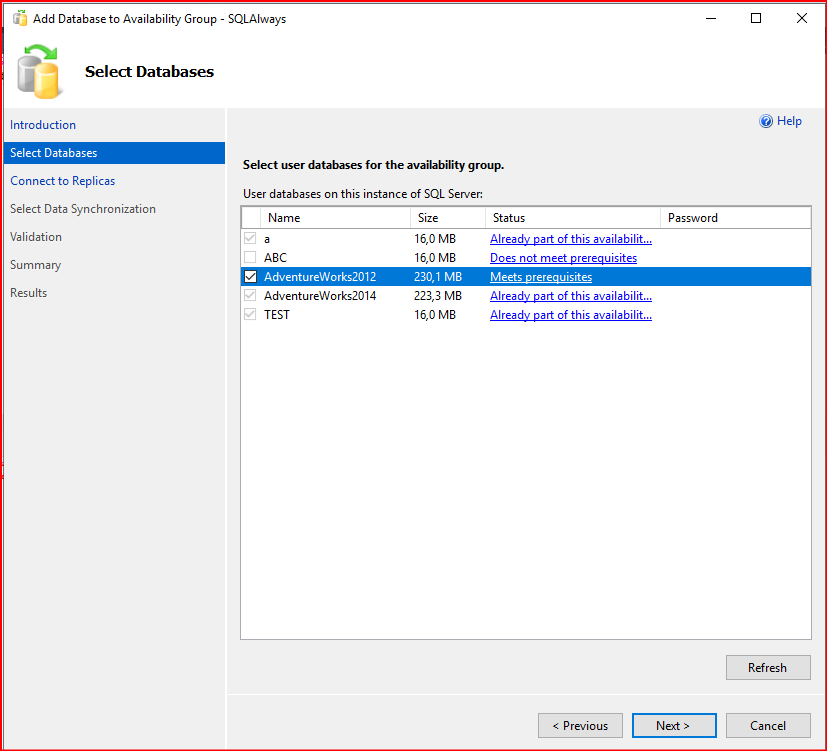
Gelen ekranda secondary olan sunucumuza bağlanıyoruz. Next deyip bir sonraki aşamaya geçiyorum.
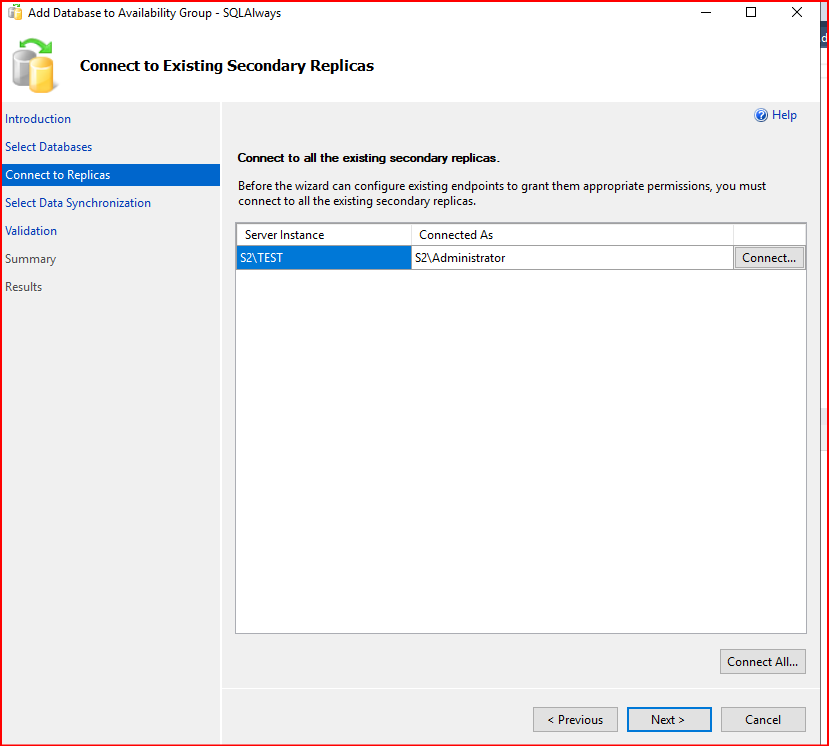
Gelen ekranda join only seçeneğini seçiyorum. İkinci sunucumda database restoring modundaydı. Join Only demeden önce hazır duruma getirilmesi gerekmekte secondary sunucusundaki veritabanını. Bu seçenek seçilmeyip Skip initial data synchnization bölümü seçilir. Daha sonra join işlemi yapılır.
Next, Next Finish diyerek işlemlerimi tamamlıyorum.
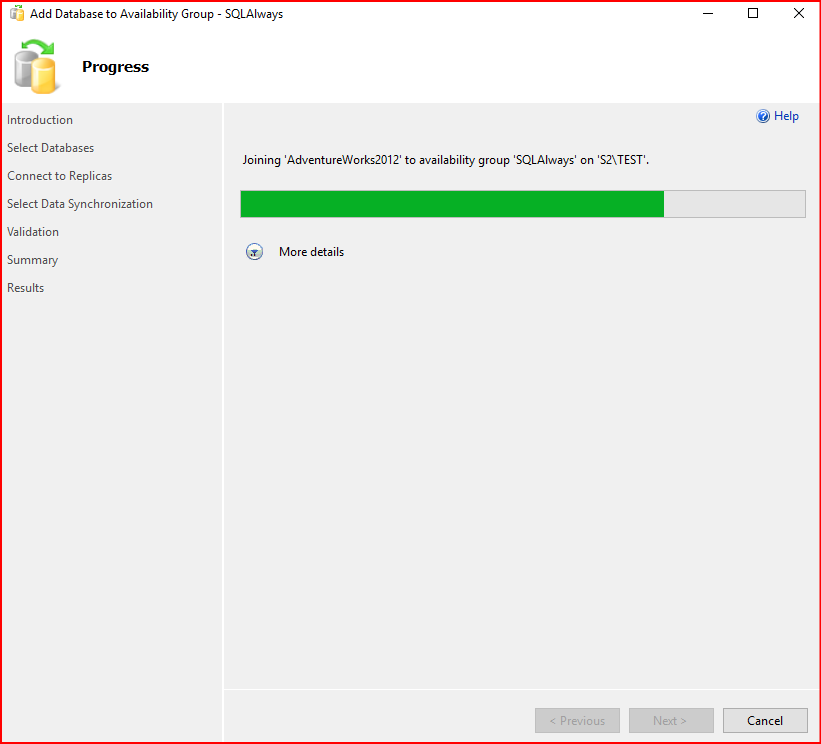
İşlemimiz bittikten sonra primary altında database’in replica olduğunu görmüş oluyoruz. Skip initial data synchnization seçeneği ile almış olsaydık sadece join işlemini manuel yapmamız gerekliydi.
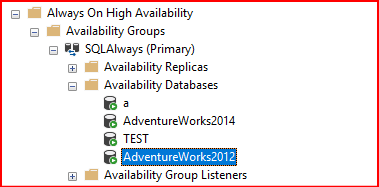
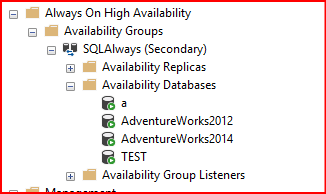
İkinci sunucumda hemen senkron olmuş oldu.
3. ADIM
Farklı disklerde bulunan veritabanlarından taşınmasını istediğimiz veritabanı data file yolları aşağıdaki komut ile master seviyesinde tanıtılması gerekmektedir. Bu işlemler sadece meta data güncellemektedir. Fizeiksel olarak database taşınmaz. Veritabanı ilk açıldığında bu yolla veritabanını aramaktadır.
ALTER DATABASE [Veritabani_Adiniz] MODIFY FILE (NAME = 'Veritabani_Data_Dosyasi', FILENAME = 'D:\SQLData\Veritabani_Data.mdf');
ALTER DATABASE [Veritabani_Adiniz]
MODIFY FILE (NAME = 'Veritabani_Log_Dosyasi', FILENAME = 'L:\SQLLogs\Veritabani_Log.ldf');
Yukarıdaki işlemden sonra veritabanımızı offline moda alıp data klasörleri taşınabilir. Bu şekilde data klasörleri taşımaktadır.
use [master];
GO
ALTER DATABASE [DeleteTestDB] SET OFFLINE
GOData dosyaları değiştikten sonra tekrardan online moduna alınmaktadır. OFFLINE modda veritabanı dosyaları rahatlıkla değiştirilebilir.
ALTER DATABASE [Veritabani_Adiniz] SET ONLINE;Primary veritabanında disk yolu değişikliği yapmak istersek failover işlemi yaparak sunucudaki veritabanının disk path’ini düzeltebiliriz. Başka bir yöntemde ilgili database’i primaryden çıkarıp ve ardında silerek tekrardan restore işlemini yapmaktır.
SQL Server AlwaysOn mimarisinde sürekliliği sağlamak adına, tüm replicaların disk harfleri ve klasör hiyerarşisi (Mount Point veya Drive Letter) birebir kopyalanmalıdır. Dosya yollarının farklı olduğu mevcut yapılarda, veritabanları AG’den geçici olarak çıkarılmalı, dosyalar standart yollara taşınmalı ve sistem “Best Practice” standartlarına göre yeniden yapılandırılmalıdır.
Başka makalede görüşmek dileğiyle..
“Allah’ın âyetlerini inkar edenler, Peygamberleri haksız yere öldürenler, insanlardan adaleti emredenleri öldürenler var ya, onları elem dolu bir azap ile müjdele.” Âl-i İmrân-21