
Bu makalede AlwaysOn’a eklenmiş bir veritabanında database’in pathlerinin yanlışlıkla farklı yerlerde olması ve bu yolların aynı yere nasıl alınacağını görmüş olacağız.
Sql server AlwaysOn’da best practices olarak primary ve secondary’de oluşturulan databaselerin aynı pathlerde olmasını öneriyor ama database filelarının olduğu klasörler farklı olabilir bunları tekrar aynı path’e çekmek istersek aşağıdaki yöntemler izlenir. Data file farklı yerde olabilir ama primary ve secondary sunucularında aynı pathlerin olması gerekiyor. Failover anında sıkıntı yaşamamak içindir.
Ne gibi sıkıntılar yaşarız. Bu yapılarda otomatik seeding yapısı çalışmaz hata vermektedir. İkincisi secondary sunucusuna manuel database eklenecekse backup alınacak veritabanının disk yolları yeni sunucuda move komutuyla değiştirilmesi gerekmektedir. Bir başka karşılaşılacak hata Diyelim ki path’leri farklı yapmanın bir yolunu buldunuz ve secondary’yi AG’ye eklediniz. Bu sefer de failover durumunda büyük bir sorunla karşılaşırsınız. Primary sunucu çöktü ve bir failover işlemiyle secondary yeni primary oldu. Yeni primary (eski secondary), database dosyalarını kendi path’inde arar. (örneğin D:\SQLData\MyDB.mdf). Ancak, orijinal primary sunucu kurtarılıp tekrar çalışmaya başladığında ve artık bir secondary olduğunda, kendisine gelen log kayıtlarını işlemeye çalışır. O da dosyaları orijinal path’inde (F:\Data\MyDB.mdf) arayacaktır. Eski primary (şimdi secondary), dosyaları beklediği yolda bulamayacağı için veritabanını recovery pending veya suspect durumuna düşürür. Availability Group senkronizasyonu bozulur ve bu sunucu artık bir secondary olarak çalışamaz. Durumu manuel olarak düzeltmeniz gerekir. Daha özetlemek gerekirse:
NodeA (Primary) çöküyor ve bir failover işlemiyle NodeB (Secondary) yeni Primary oluyor. Yeni Primary (NodeB) Sorunsuz Çalışır: NodeB, database dosyalarını her zaman olduğu gibi kendi local path’inde (D:\SQLData\…) arar ve bulur. İstemciler yeni primary’e bağlanıp işlemlerine devam eder. Şimdilik her şey iyi görünür. NodeA sunucusu tamir edilip tekrar ayağa kaldırılıyor ve Availability Group’a tekrar katılıyor. Artık o bir Secondary Replica. AG mimarisi gereği, yeni Primary (NodeB), tüm log kayıtlarını eski Primary’e (şimdiki Secondary NodeA) gönderir. NodeA da bu log kayıtlarını kendi üzerindeki database kopyasının transaction log’una yazmaya ve veri sayfalarına uygulamaya (redo) çalışır. NodeA (şimdiki Secondary), kendi üzerindeki database’in metadata bilgisine bakar. Bu metadata, database’in dosyalarının orijinal yolunun (F:\Data\MyDB.mdf) hala geçerli olduğunu söyler. Ancak, siz daha önce bu sunucuyu kullanıma almadan önce dosyaları MOVE komutuyla D:\SQLData\… yoluna taşımıştınız. Ya da daha kötüsü, çöken sunucu kurtarılırken dosyalar orijinal yerinde bile olmayabilir. NodeA (Secondary), kendisine gelen log kayıtlarını işleyebilmek için database dosyalarını F:\Data\ yolunda arar. Ancak dosyalar ya o yolda yoktur ya da eski bir kopya vardır. Bu nedenle, logları işleyemez (redo yapamaz). Bu durumda, NodeA üzerindeki database SUSPECT veya RECOVERY PENDING durumuna düşer. Availability Group senkronizasyonu bozulur. NodeA artık bir secondary olarak çalışamaz ve AG’den düşer. Bu hatayı düzeltmek için manuel müdahale gerekir. NodeA’daki database’i AG’den çıkarmanız, doğru path’e (D:\SQLData\…) taşımanız veya restore etmeniz ve sonra tekrar AG’ye eklemeniz gerekir. Bu da planlanmamış downtime demektir.
| Path’ler Aynı İse | Path’ler Farklı İse |
|---|---|
| Automatic Seeding sorunsuz çalışır. | Automatic Seeding çalışmaz, hata verir. |
| Backup/Restore işlemleri doğrudan, MOVE olmadan çalışır. | Backup/Restore işlemlerinde mutlaka manuel MOVE komutu yazmak gerekir. |
| Failover/Role Değişimleri sorunsuz gerçekleşir. Dosya yolları tutarlı olduğu için her sunucu dosyayı doğru yerde arar. | Failover Sonrası eski primary kurtarıldığında dosyaları bulamaz, senkronizasyon bozulur. Database suspect/recovery pending durumuna düşebilir. |
| Yönetim ve Otomasyon çok daha basittir. Script’ler ve bakım planları tüm sunucularda aynı şekilde çalışır. | Yönetim karmaşıklaşır, her sunucu için özel script ve düzenleme gerekir. |
| Best Practice‘e uygundur. | Best Practice’e aykırıdır, potansiyel sorun kaynağıdır. |
Özetle Karışıklığın Düzeltilmiş Hali:
- Failover olduğunda, YENİ PRIMARY (eski secondary) kendi dosya yolunu kullanır ve SORUNSUZ çalışır.
- Asıl sorun, ESKİ PRIMARY (artık yeni secondary) tekrar çevrimiçi olduğunda ortaya çıkar. Çünkü o hâlâ kendi eski dosya yolunu kullanmaya çalışır ve dosyaları bulamaz.
Not: Disk yollarının farklı olması başlangıçta herhangi bir sorun teşkil etmez. Ama yeni bir data file veya file group oluşturulacağı zaman veritabanı suspect moda düşüyor. Neden primary yeni data file ekler bunu log dosyasıyla secondary sunucuya yollamaktadır. Secondary ilgili dosyayı bulamaz suspect moduna düşmektedir.
S1 sunucumuz Primary S2 sunucumuz ise secondary:
Şimdi primary sunucumuzda aşağıdaki komutları çalıştırdığımızda mdf ve ldf data fileların oluştuğu pathleri görmekteyiz.
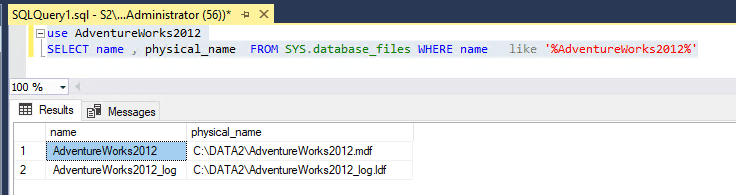
Secondary sunucumuzda aşağıdaki komutları çalıştırdığımızda mdf ve ldf data fileların oluştuğu pathleri görmekteyiz.

Dikkat edersek iki sunucuda data fileların yolları farklı, databaselerimiz çoğu böyleyse bir süreden sonra içinden çıkılamaz bir hal alabilir.
Genellikle küçük veritabanlarımda bu işlemi kullanmaktayım.(250 GB)
1.ADIM:
Secondary sunucumuzda ilgili veritabanı Availibility Databases sekmesinden çıkarılır. Aslında bu adımlarada gerek yok primary’den çıkartsak secondary sunucusundan çıkarmamıza gerek kalmıyor.

Suspend Data Movement yapıldıktan sonra Remove Secondary Database sekmesine tıklanıp veritabanı AG’den çıkartılır. Veritabanı Suspend denilmeden Remove komutu ilede hemen çıkartılabilir.


AG’den çıkartılmış veritabanı Secondary sunucusundan silinir. Tabi yukarıda çarpı işareti olarak göstermesinin sebebi primary’de AG altında çıkartılmamış. Sadece suspect moduna alınmış. AG altında çıkarttıktan sonra secondary sunucusundan da silindiğini görmüş oluyoruz. Çıkarılan veritabanı AdventureWorks2012 veritabanıdır.


Not: Detach yöntemide yapılarak veritabanı çıkarılabilir. Veritabanının sql server’la bağlantısını kestikten sonra path yolları manuel bir şekilde değiştirebilir.

Secondary sunucusundan tamamen veritabanımızı yok ettik.
2. ADIM
Bu adımda ise önceden elimizde bulunan(yada primary sunucusundan yeni alınan ) full backup’ı secondary sunucusuna No Recovery modundan restore işlemini gerçekleştiriyoruz.


Full backup’ı secondary sunucusuna restore yaptıktan sonra PRİMARY sunucusundan sırasıyla dif backup ve log backup işlemleri gerçekleştiriyorum. Log backup’a gerek duymadan en son diff alınsada yeterli aslında.

Almış olduğum dif ve log backup’ı secondary sunucusuna no recovery mode’da restore ediyorum tabi bu restore işlemleri sırasında yeni path’imide belirtmiş oluyorum.


Diff backup’ıda yükledikten sonra log backup’ıda yüklüyorum no recovery modda aslında en son diff backup aldıktan sonra log backup’ı restore etmeye gerek yok.
Database’i secondary sunucusunda restoring moduna aldıktan sonra primary sunucusunda AlwaysOn Databases kısmından ilgili database join only ile AG’ye katıyorum. AlwaysOn’da seeding modu açıksa kendisi senkron oluyor.

Primary sunucusunda ilgili veritabanını AG altından çıkartmıştık. Şimdi tekrardan primary sunucusunda AdventureWorks2012 database’ini AG altına alalım.

Add Database diyiyoruz. Gelen ekranda Next deyip bir sonraki aşamaya geçiyoruz.

Gelen ekranda secondary olan sunucumuza bağlanıyoruz. Next deyip bir sonraki aşamaya geçiyorum.

Gelen ekranda join only seçeneğini seçiyorum. İkinci sunucumda database restoring modundaydı. Join Only demeden önce hazır duruma getirilmesi gerekmekte secondary sunucusundaki veritabanını. Bu seçenek seçilmeyip Skip initial data synchnization bölümü seçilir. Daha sonra join işlemi yapılır.

Next, Next Finish diyerek işlemlerimi tamamlıyorum.

İşlemimiz bittikten sonra primary altında database’in replica olduğunu görmüş oluyoruz. Skip initial data synchnization seçeneği ile almış olsaydık sadece join işlemini manuel yapmamız gerekliydi.

İkinci sunucumda hemen senkron olmuş oldu.

Primary veritabanında disk yolu değişikliği yapmak istersek failover işlemi yaparak sunucudaki veritabanının disk path’ini düzeltebiliriz. Başka bir yöntemde ilgili database’i primaryden çıkarıp ve ardında silerek tekrardan restore işlemini yapmaktır.
“Allah’ın âyetlerini inkar edenler, Peygamberleri haksız yere öldürenler, insanlardan adaleti emredenleri öldürenler var ya, onları elem dolu bir azap ile müjdele.” Âl-i İmrân-21