
Bu makalade AlwaysOn yapısındaki Show Dashboard ekranında bazı açıklamaları hangi kolunun ne işe yaradığını ele almış olacağım. Herhangi bir failover işleminden önce secondary sunucunun ne kadar gereden geldiğini tahmin edeceğiz ve failover için uygun adımı gözlemlemiş olacağız.
İlgili AG üzerinde sağ tıklayıp Show Dashboard diyiyoruz.
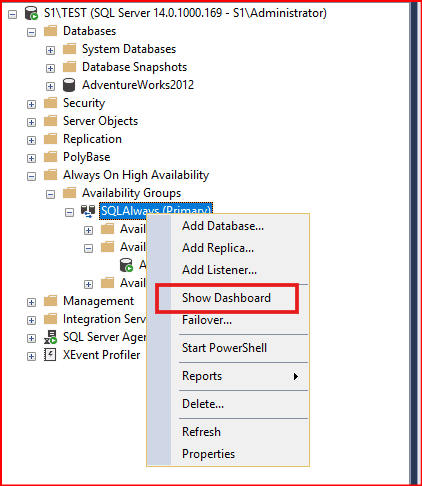
Aşağıdaki ekranda genel olarak Show Dashboard ekranını görmekteyiz.

Availability mode kısmı Synchronous Commit olduğu için Synchronization State durumu Synchronized olması gerekmektedir. Ama Availability mode kısmı Asynchronous olsaydı. Database’ler secondary sunucusunda Synchronizing durumunda olacaktı.

Synchronous işlemi herhangi bir insert update delete primary olan sunucuya geldiğinde işlem ilk olarak primary sunucusunda ilgili veritabanının log dosyasına yazılır. Kullanıcıya işlem tamamlandı bilgisi iletilmez.(uncommitted) SQL Server’ın transaction log kayıtlarını ikincil sunucuya gönderirken kullandığı lock block(genellikle 60 kb civarında) yapısı veriyi paketleme veya paketleme veya gruplama işlemidir. Düşünün ki, ana sunucuda sürekli küçük küçük log kayıtları (her bir INSERT, UPDATE için ayrı kayıtlar) üretiliyor. Her bir kaydı tek tek, anında ikincil sunucuya göndermek son derece verimsiz olurdu. Bu, postaneye her gün tek bir mektup atmaya gitmek gibidir. Bunun yerine, SQL Server bu küçük log kayıtlarını biriktirir, belirli bir boyuta ulaştığında veya belirli bir süre dolduğunda hepsini bir paket (yani Log Block) halinde ikincil sunucuya gönderir. Bu, postaneden haftalık mektupları bir kutuya doldurup tek seferde göndermek gibidir. Çok daha verimli bir işlemdir.
Ana sunucuda bir log kaydı oluştuğunda, hemen gönderilmez. Önce ana sunucunun belleğindeki (memory) kendi gönderi tamponuna (send buffer) eklenir. Bu tampon, gönderilmeyi bekleyen log kayıtları için bir bekleme alanıdır. Burada sadece lock block yapısının dolmasını beklemez çünkü hiç veride bu bloğu doldurmaya bilir. Bunun için kendi içerisinde ekstradan bir zaman dilimi vardır. Yukarıdaki iki koşuldan biri tetiklendiğinde, ana sunucu bu Log Block paketini ağ üzerinden ikincil sunucuya gönderir. İkincil sunucu bu Log Block’u alır, paketten çıkarır ve içindeki bireysel log kayıtlarını kendi transaction log dosyasına yazar. Yani commit edip garanti altına alır.
SQL Server’ın transaction log’u fiziksel bir yapıdır. Log kayıtları, bellekte (log buffer) ve diskte (log file) art arda (sequentially) dizilir. Log Block da bu fiziksel yapının bir parçasıdır. Log block içerisinde tüm veritabanlarının bilgileri tutulmaktadır.
Log block dolduktan sonra ikinci sunucuya gönderilir. İkincil sunucu, bu log kaydını kendi transaction log dosyasına fiziksel olarak yazar ve diske (disk) kalıcı hale getirir. Bu, senkron modun en kritik adımıdır. Bu olay hardining olarak geçmektedir.İkincil sunucu, log kaydını başarıyla diske yazdığını ana sunucuya bir “onay mesajı” (acknowledgement) göndererek bildirir.
Ancak ve ancak ana sunucu, ikincil sunucudan bu onay mesajını aldıktan sonra, işlemi kendi transaction log’unda commit eder. Ana sunucu, işlemin başarıyla tamamlandığına dair onayı (commit confirmation) istemci uygulamasına (client application) gönderir. İstemci ancak bu noktada “işlem tamam” bilgisini alır.
Ana sunucu anlık ve beklenmedik bir şekilde çöker (power loss, hardware failure). İşlem, çökmeden hemen önce istemciye commit onayı gönderilmişse, bu işlemin log kaydı kesinlikle en az bir ikincil sunucunun diskine de yazılmış durumdadır. Sıfır veri kaybı (Zero Data Loss) hedefine çok yakınsınız demektir. Kurtarma noktası hedefi (Recovery Point Objective – RPO) teorik olarak 0’dır. Yeni ana sunucu (eski ikincil) failover olduğunda, kayıpsız bir şekilde kaldığı yerden işleme devam eder.
İstemci, işleminin tamamlandığını öğrenmek için, işlemin ana sunucudan ikincil sunucuya gitmesi, ikincil sunucuda diske yazılması ve onayın ana sunucuya geri dönmesini beklemek zorundadır. İstemcinin aldığı yanıt süresi (transaction latency) artar. Bu artış, ana ve ikincil sunucular arasındaki ağ gecikmesi (network round-trip time – RTT) ve ikincil sunucunun disk yazma hızı ile doğru orantılıdır.
İkincil sunucunun yavaş diski veya sunucular arasındaki yüksek ağ gecikmesi, tüm sistemin işlem hacmini (throughput) ciddi şekilde düşürebilir. İkincil sunucu ne kadar yavaşsa, ana sunucu da o kadar yavaşlar.
Asenkron olarak seçilirse sistem siz failover modunu otomatik bir şekilde yapsanızda hata mesajı verecektir. Aslında veriler ms cinsinden yazılır. Kaybolma ihtimali olduğu için bu mesaj yazılmaktadır. Çünkü asenkron modda olan sunucu üzerine veri sonradan commit edilmektedir. Bu modda işlem ilk olarak primary sunucusuna yazılır. failover olduğunda primary sunucusuna yazılan veri secondary sunucusuna yazılmadan failover olabilir. Buda veri kaybına sebebiyet vermektedir.
Daha detaylı açıklayalım:
Asenkron modun felsefesi “önce hız, sonra tutarlılık”tır. Ana sunucu (primary), bir işlemin tamamlandığını istemciye bildirmek için ikincil sunucunun (secondary) onayını beklemez.
Bir UPDATE, INSERT veya DELETE işlemi ana sunucuya gelir. Ana sunucu, işlemin log kaydını (transaction log record) kendi transaction log dosyasına fiziksel olarak yazar ve hemen commit eder (yani, işlemin tamamlandığını işaretler). Ana sunucu, işlemin başarıyla tamamlandığına dair onayı (commit confirmation) hemen istemci uygulamasına gönderir. İstemci işlemin tamamlandığını öğrenir ve yoluna devam eder. İstemciye yanıt gönderildikten sonra, ana sunucu, log kaydını bir Log Block içinde ikincil sunucuya asenkron olarak gönderir. Bu gönderim, ana sunucunun iş yükünden bağımsız olarak, kendi hızında ve planında yapılır. İkincil sunucu log bloğunu alır, kayıtları kendi transaction log’una yazar ve veri sayfalarına uygular (redo). Ana sunucu, bu işlemin ne zaman tamamlandığıyla doğrudan ilgilenmez.
Kötü senaryo sunucu, işlemi commit ettikten ve istemciye onay gönderdikten sonra, ama o işlemin log kaydını ikincil sunucuya göndermeden önce anlık ve beklenmedik bir şekilde çöker. İstemciye “işlem başarılı” dendiği için uygulama işlemin yapıldığını düşünür. Ancak, bu işlemin kaydı ikincil sunucuya hiç ulaşmamıştır. İkincil sunucu yeni ana sunucu olduğunda, bu işlem yoktur. Veri kaybı (Data Loss) yaşanır.
Veri kaybı miktarı, ana sunucunun çöktüğü anda log buffer‘ında birikmiş ama gönderilmemiş ne kadar log kaydı olduğuna bağlıdır. Bu süre saniyeler, hatta yoğun yük altında dakikalar bile olabilir. RPO 0 değildir ve tahmin edilemez.
İstemci, işlemin tamamlandığını öğrenmek için sadece ana sunucunun kendi disk I/O hızını bekler. İkincil sunucunun ağ gecikmesi veya yavaş diski, istemcinin yanıt süresini hiçbir şekilde etkilemez.
İstemci için mümkün olan en düşük işlem gecikmesi (latency) sağlanır. Ana sunucunun işlem hacmi (throughput) üzerinde hiçbir kısıtlama yoktur. İkincil sunucunun durumu ne olursa olsun, ana sunucu maksimum hızda çalışmaya devam eder. İkincil sunucu ana sunucudan çok uzakta olsa bile (örneğin, farklı bir kıtada) performans etkilenmez. Bu, uzak felaket kurtarma (DR) senaryoları için idealdir.
Asenkron modda yapılandırılmış bir ikincil sunucu asla otomatik failover yapısında kullanılamaz. Ana sunucu çökerse, küme yöneticisi (Windows Failover Cluster) asenkron bir ikincil sunucuyu otomatik olarak yeni primary yapmaz. Çünkü bu sunucunun ana sunucuyla tamamen senkron olmadığını ve veri kaybı yaşanacağını bilir. Failover ancak manuel olarak (zorunlu manuel failover – forced manual failover) ve veri kaybı kabul edilerek yapılabilir.
Asenkron mod “gönder ve unut” gibi görünse de, SQL Server arka planda birikimi kontrol eder. Ana sunucu, ikincil sunucuya gönderilmeyi bekleyen log kayıtlarının boyutunu sürekli izler.(log_send_queue_size). Eğer bu kuyruk aşırı büyürse (örneğin, ikincil sunucunun ağı çok yavaşsa veya diski çok dolduysa), bu durum ana sunucuyu dolaylı olarak etkileyebilir. Çok aşırı durumlarda, ana sunucu log kayıtlarını temizleyemeyebilir ve bu da genel performansı etkileyebilir. Ancak, bu istemci işlemlerinin yanıt süresini doğrudan etkilemez.
Asynchronous-Commit seçmek, istemciye “işlem tamam” onayını en hızlı şekilde göndermek uğruna, ikincil sunucunun bu işlemden haberdar olup olmaması riskini almak demektir. Bu, yüksek performans ve uzak mesafeler için ödenen bir “veri tutarlılığı” bedelidir.
Genellikle aynı oda içerisinde olan sunucular fiber kabloyla birbirine senkron bir şekilde bağlanabilir. farklı ortamlarda olan sunucular bir yan oda olsa dahi asenkron modda seçilmesi demektedir. Çünkü veri ilk olarak secondary sunucunun ldf dosyasını commit yaptığı için buda network ve alt yapımıza bağlı olarak performans kaybımıza sebebiyet verecektir.
Senkronizasyon durumları asenkron modunda bırakılırsa herhangi bir manuel failover durumunda sistem kendini secondary sunucusuna atmaktadır. Yeni primary sunucusundaki AG databases sekmesinde tüm veritabanlarını resume yapmak lazım. Veri kaybından dolayı son kullanıcıdan tekrar onay almak içindir. Resume işlemi yapıldıktan sonra eski primary sunucusu yeni primary sunucusu ile kendini eşit hale getirmektedir. Eski primary sunucusunda fazla veri varsa silinir. Neden database AG altında suspend modunda olur. Veri kaybından dolayı veya tekrardan eski ortama dönmek isteyebiliriz. Sync modunda ise böyle bir sorunla karşılaşılmaz.
Disaster Recovery ortamlarında bulunan 3. node genellikle asenkron modda bırakılması gerekmektedir. Sebep farklı bir lokasyonda olduğu için verinin secondary sunucusuna bilgi düşüp primary sunucuna yazdığı için bir zaman kaybına sebebiyet verecektir.
Sonuç olarak:
Senkron Replikasyon: Primary node, değişiklikleri secondary node’a yazar ve onay alana kadar işlemi tamamlamaz. Veri kaybı riski yoktur. Gerçek zamanlı veri tutarlılığı sağlar. Performans düşebilir çünkü işlem ancak tüm kopyalar tamamlandığında başarılı kabul edilir.
Asenkron Replikasyon: Primary node değişiklikleri secondary node’a gönderir ama işlemi tamamlamak için beklemez. Daha hızlıdır ve ağ gecikmelerine karşı dayanıklıdır. Veri kaybı olabilir çünkü ikincil sunucu güncellenmeden primary sunucu çökebilir.
Örnek Senaryo:
– Primary Node: SQLServer01
– Secondary Node: SQLServer02
– Mod: Senkron (High Availability – HA)
İşleyiş nasıl olur:
1. Kullanıcı bir INSERT sorgusu çalıştırır.
2. SQLServer01, işlemi kendi veritabanına yazar.
3. Aynı işlemi SQLServer02’ye gönderir.
4. SQLServer02, işlemi tamamlayıp onay döner.(commit edilir.)
5. SQLServer01, kullanıcının işlemini onaylar.
Primary node, kullanıcıya işlemin tamamlandığını, ancak secondary node (SQLServer02) veriyi kendi LDF dosyasına (yani transaction log) başarıyla yazdıktan sonra bildirir.
Örnek Senaryo-2:
– Primary Node: SQLServer01
– Secondary Node: SQLServer03
– Mod: Asenkron (Disaster Recovery – DR)
İşleyiş nasıl olur:
1. Kullanıcı bir UPDATE sorgusu çalıştırır.
2. SQLServer01 işlemi hemen onaylar.
3. Aynı işlem SQLServer03`e gönderilir ama anında işlenmeyebilir.
Bu durumda primary node çökerse, SQLServer03 en son veriyi henüz almamış olabilir ve bir miktar veri kaybı yaşanabilir.
Hangi durumlarda hangisini kullanılması gerekmektedir. Senkron Mode’da, Aynı veri merkezindeki (low-latency) sunucular arasında, Gerçek zamanlı tutarlılık gerektiren finans ve kritik sistemlerde, Primary ve secondary node’lar yüksek hızlı ağ bağlantısına sahipse kullanılmaktadır. Asenkron Mode, Uzak veri merkezleri arasında (WAN bağlantılı), Felaket kurtarma (Disaster Recovery – DR) sistemlerinde, Performansın tutarlılıktan daha önemli olduğu durumlarda
Çok yoğun transaction olan sistemlerde asenkron olması tavsiye edilir. İki sunucudada bu işlem yapılır çünkü güncel olan sunucu başka zamanda secondary olabilir.
Asenkron olarak ayarlandıktan sonra failover işleminin manuel yapılması gerekmekte buda herhangi bir sıkıntı durumunda veri merkezine gidip failover işlemini manuel yapmanıza sebep olur. Mode kısmı asenkron olarak seçilirse primary sunucusu elimizde donanım ve network yapısına göre senkron olma durumları değişmektedir. Secondary sunucunun geriden gelmesi milisaniye veya saniyeler türündedir.
Not: Asenkron mod aktif edilirse show dashboard ekranında secondary sunucusu ünlem işareti olarak görülmektedir. Senkron moda çekildiğinde bu ibare kaybolmaktadır.
Bazen AG’yi senkron tanımlasak ve veritabanları senkron gözükmesine rağmen çeşitli sebeplerden dolayı geriden gelebilir. Şimdi bu geriden geldiğini görmek için bazı kavramlara değinmiş olacağız.

Synchronous commit olduğu için Failover Readiness kısmı ikinci sunucuda No Data Loss seklinde olması lazım. Ama Asynchronous olsaydı secondary sunucusunda Data Loss şeklinde gözükecekti.

Not: Alwayson yapısında Availability mode Asynchronous commit modunda olursa herhangi bir switch over işleminde data loss görülmektedir. Bu durumlarda veritabanını synchronous commit moduna alırız. Bu durumda primary ve secondary sunucusunda bulunan veritabanlarının ldf dosyaları aynı seviyeye geldikten sonra No data loss görülmektedir. Ldf dosyaları eşitleme işlemine kadar data loss şeklinde görülmektedir. Ldf dosyası eşitlendikten sonra failover işlemi olursa secondary sunucusu yeni primary sunucusu reverting moduna geçmektedir. Bu sefer veritabanları data file seviyesinde eşitleme işlemi olduktan sonra Synchronized görülmektedir.
Asenkron olduğunda ise bu işlemin tam tersi olmaktadır.

Gösterge ekranına bazı kolunlar eklemek için Add/Remove Colums’a tıklıyoruz.

Gelen ekrandaki değerlere tıklayarak Show Dashboard ekranına ekleyebiliriz.

Sorunlar ve Durumlar aşağıdaki ifadeler kullanılmaktadır.
Issues: Replika ile ilgili olası hatalar veya problemler
Suspended: Replikanın durdurulup durdurulmadığını gösterir. (True/False)
Not: Always on yapısında olan bir veritabanında herhangi bir tablo truncate edildiğinde ne gibi ne senaryolar yapılması yapılmaktadır. Öncelikle sql serverda tablo bazlı restore işlemi yoktur. Veritabanı bazlı restore işlemi olmaktadır. Tablo truncate edilmeden önce Always on altında ilgili veritabanı pause edilip veri akışı secondary sunucuna yapılmamasına yapılmaktadır. Eğer veritabanı servis aracılığıyla alınıyorsa ilgili veritabanının diğer kolonlarına veri akışı gelmektedir. Sadece ilgili veritabanı servis aracılığıyla alınır. Eğer çok büyükse primary makina üzerinde aynı veritabanı test olarak restore edilir son ana kadar verileri ordan alıp daha sonra servis aracılığıyla fark veriler alınabilir. Eğer canlı veritabanı alan bir tablo ise truncate komutu ile tablo silindi son ana kadar veritabanı başka bir isimde dönülür. Örneğin en son backup işlemden 10 dakika öncede alınmışsa 10 dakikalık veri kaybı olmaktadır.
Suspend Reason: Eğer replika durdurulduysa neden durdurulduğunu gösterir.
Kurtarma ve Veri Kaybı Tahminleri aşağıdaki ifadeler kullanılmaktadır.
Estimated Recovery Time (seconds): Olası bir failover durumunda ne kadar sürede toparlanabileceğini gösterir.
Estimated Data Loss (time): Asenkron modda bir failover olursa ne kadar veri kaybı yaşanabileceğini tahmin eder.

Log Gönderme ve Alma Bilgileri aşağıdaki ifadeler kullanılmaktadır.
Last Sent LSN: Primary sunucudan secondary sunucuya en son gönderilen log kaydının LSN değeri.
Last Sent Time: En son LSN’in secondary sunucuya gönderildiği zaman.
Last Received LSN: Secondary sunucunun primary’den en son aldığı LSN değeri.
Last Received Time: En son LSN’in secondary sunucuda alındığı zaman.

Log Gönderme ve Senkronizasyon Metrikleri Aşağıda Belirtilmiştir.
Log Send Queue Size (KB): Primary sunucudan secondary sunucuya gönderilmeyi bekleyen logların boyutu (KB cinsinden).
Log Send Rate (KB/sec): Logların secondary sunucuya gönderilme hızı (KB/saniye).
Redo Queue Size (KB): Secondary sunucunun uygulamayı bekleyen log büyüklüğü (KB cinsinden).
Redo Rate (KB/sec): Secondary sunucunun redo işlemlerini işleme hızı (KB/saniye).
FileStream Send Rate (KB/sec): Eğer FileStream kullanılıyorsa, verilerin gönderilme hızı.
NOT: Secondary sunucularda sadece redo işlemi gerçekleşir. Checkpoint işlemi sadece primary olan sunucuda gerçekleşmektedir. Bu işlem diske yazılma hızlarıdır.
Yukarıdaki bazı ifadelerin ekran resmi aşağıda belirtilmiştir.
Log Send Queue Size : Primary sunucudan secondary sunucuya gönderilmeyi bekleyen logların boyutu (KB cinsinden). Büyük databaselerde kuyrukta birikmelere sebep olabiliyor.

Log Send Rate: Logların secondary sunucuya gönderilme hızı (KB/saniye).

Redo Queue Size: Secondary sunucunun uygulamayı bekleyen log büyüklüğü (KB cinsinden). Yani ldf dosyasına commit edilmiş mdf dosyasına yazılmak için bekliyor.

Şunu belirtmek gerekirse Primary sunucusuna gelen istek ilk olarak buffer manager’e yazılır.(buffer log) Daha sonra buffer üzerindeki veri log hardened yardımıyla ldf dosyasına commit edilmektedir. Primary sunucundaki veri secondary sunucusunda ilk olarak buffer manager kısmına yazılmaktadır. Daha sonra log hardened ile secondary sunucusunun ldf dosyasına yazılmaktadır. Bizlerin show dashboard ekranından redo değerine bakmamız ldf dosyasında bulunan verinin mdf dosyasına yazılma zamanı, kuyrukta bekleyen veri miktarı ve eklenen son data değerini görmekteyiz. Aslında redo değerine bakmamız son kullanıcının veri okumasına ne kadar geriden geldiğini bulmasıdır.
Log Hardened Time: Secondary sunucusunun tam replike olabilmesi için primary sunucusundan gelen isteklerin diske yazılması gerekmektedir.
Hardening, bir log kaydının (log record), geçici bellek alanından (log buffer) kalıcı depolama birimine (LDF dosyası) fiziksel olarak ve güvenli bir şekilde yazılma işlemidir. SQL Server, bir işlemin kalıcı (durable) sayılabilmesi için, önce o işlemin log kaydının diske yazılması gerektiği kuralına uyar. Buna Write-Ahead Logging denir. “Log’un diske yazılması” işte buradaki “hardening” adımıdır. Hardening=Write-Ahead Logging diyebiliriz.

Log Uygulama (Hardened) ve Redo Süreçleri aşağıda verilmiştir.
Last Hardened LSN: Secondary sunucunun diskine kalıcı olarak yazılan en son LSN değeri.
Last Hardened Time: En son hardened LSN’in diske yazıldığı zaman.
Last Redone LSN: Secondary sunucunun uyguladığı (redo işlemi yapılan) en son LSN değeri.
Last Redone Time: En son redo işlemi yapılan LSN’in işlendiği zaman.
Last Redone Time: Diske yazılan log kayıtlarının secondary sunucusunda data file’a yazılma işlemi.

Son Log Kayıtları aşağıda belirtilmiştir.
Last Commit LSN: Primary sunucudaki en son commit edilen transaction’ın LSN değeri.
Last Commit Time: En son commit edilen transaction’ın zamanı.


Log hardened işlemi gerçekleşmişse ve senkron ag kullanıyorsanız dashboard’da synchronized görüyorsunuz. Ama bazı durumlarda log hardened işlemi gerçeklemişse bile redone işlemi geriden gelebiliyor.( Disk yavaşlığı vb.) Böyle bir durumda ag’yi synchronized görüp failover yapmaya çalışsanız failover’ın gerçekleşmesi için saatlarce beklemeniz gerekebilir. Çünkü redone işlemi yapılmamış.
Aşağıdaki kod bloğunda AlwaysOn yapısındaki herhangi bir veritabanının primary ve secondary sunucusundaki senkron durumlarını görebiliriz. Aşağıdaki çalıştırdığım ikinci komutla senkron bir şekilde görülebilir.
SELECT
ar.replica_server_name,
adc.database_name,
ag.name AS ag_name,
dhdrs.synchronization_state_desc,
dhdrs.is_commit_participant,
dhdrs.last_sent_lsn,
dhdrs.last_sent_time,
dhdrs.last_received_lsn,
dhdrs.last_hardened_lsn,
dhdrs.last_redone_time
FROM sys.dm_hadr_database_replica_states AS dhdrs
INNER JOIN sys.availability_databases_cluster AS adc
ON dhdrs.group_id = adc.group_id AND
dhdrs.group_database_id = adc.group_database_id
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = dhdrs.group_id
INNER JOIN sys.availability_replicas AS ar
ON dhdrs.group_id = ar.group_id AND
dhdrs.replica_id = ar.replica_id
where database_name='DB_NAME'
Aşağıdaki script yardımıyla Secondary sunucunun primary sunucuya göre ne kadar geriden geldiğini bulabilirsiniz. 1 saat üzerinden fazla olan veritabanlarıyla ilgili kayıt dönmektedir. Aşağıdaki dönen ilgili veritabanları yukarıdaki komut ile kordineli çalıştırdığımızda mantık anlaşılıyor.
SELECT DB_NAME(drs.database_id) AS Database_Name
,drs.last_commit_time AS Primary_Commit
,drs2.last_commit_time AS Secondary_Commit
,CONCAT(DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time)/3600 ,' Saat'
,(DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time)%3600)/60 ,' Dakika'
,DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time)%60 ,' Saniye') AS Senkronizasyon_Farki
FROM sys.dm_hadr_database_replica_states drs
JOIN sys.dm_hadr_database_replica_states drs2 ON drs.database_id=drs2.database_id
WHERE drs.is_local=1 AND drs2.is_local=0 AND DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time)>3600
ORDER BY DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time) DESC
Başka bir makalede görüşmek dileğiyle…
“Onlar, amelleri, dünyada da, ahirette de boşa gitmiş kimselerdir. Onların hiç yardımcıları da yoktur. “Âl-i İmrân-22