
Bir önceki partition makalemizde sıfırdan partition’lı bi tabloda verileri nasıl insert ettiğimizde ilgili partition altında nasıl konumlandığını görmüştük. İlgili makalede partition hakkında detaylı bilgilere de ulaşabilirsiniz.
Bu makalede oluşturmuş olduğumuz normal tabloyu herhangi bir partition’lı tabloya import etmeden önce kendi üzerinde partition yapısına geçirme çalışacağız.
İlk olarak partition yapısında olmadan bir tablo oluşturuyoruz. Birinci adım partition’sız tablomuzu oluşturma.
CREATE TABLE PARTITIONSIZ(
ID INT IDENTITY(1,1) NOT NULL,
AD VARCHAR(50) NULL,
SOYAD VARCHAR(50) NULL,
TARIH DATETIME NOT NULL
)ON [PRIMARY]Oluşturmuş olduğum tablo içerisine bazı değerler insert ediyorum. 11 değer insert ettim. Eğer tablomuz herhangi bir partition işlemine tabi olmamışsa her zaman partition number’ı 1 olarak gözükür yani tek partition üzerinde büyür.
SELECT partition_id, object_id, partition_number, rows
FROM sys.partitions
WHERE object_id= OBJECT_ID('PARTITIONSIZ')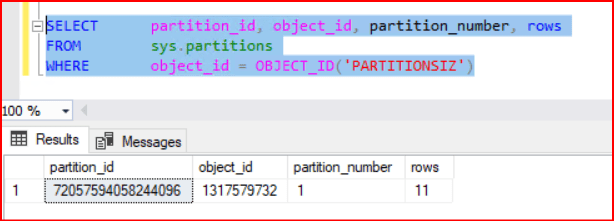
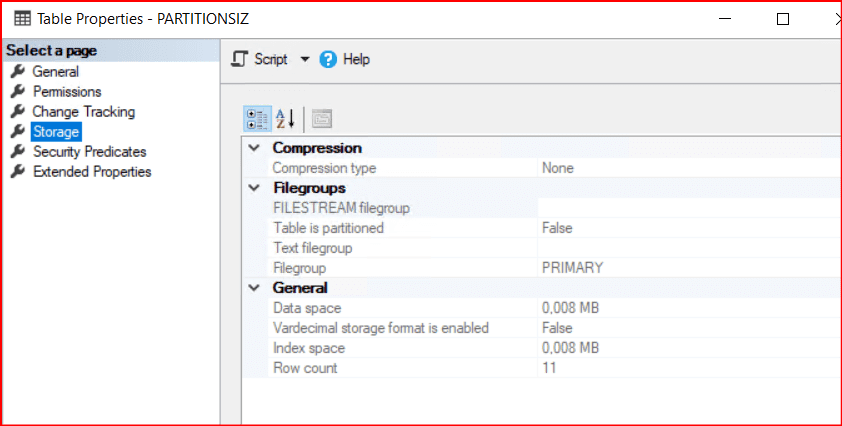
Tablomuzun storage bölümünde Hangi filegroup üzerinde olduğu ve table is partitioned kısmında tablomuzun partition yapısında olup olmadığını görebiliriz.
Veritabanımız altında tablomuzu partition yapısına geçirmek için bir function ve scheme yapısının oluşturulması gerekiyor. Aşağıdaki scriptler yardımıyla oluşturulur. Sizde elinizde bulunan verilerin dağılımına göre partition işleminin filegroup ve tarih aralığını belirlemeniz lazım. Detaylı bilgi için ilgili makalenin okunabilir.
CREATE PARTITION FUNCTION [pf_Tarih](datetime) AS RANGE RIGHT FOR VALUES (N'2020-01-01T00:00:00.000', N'2021-01-01T00:00:00.000')CREATE PARTITION SCHEME [ps_Tarih] AS PARTITION [pf_Tarih] TO ([FG2019], [FG2020], [FG2021])Veritabanı altında storage bölümünde bulunmaktadır.
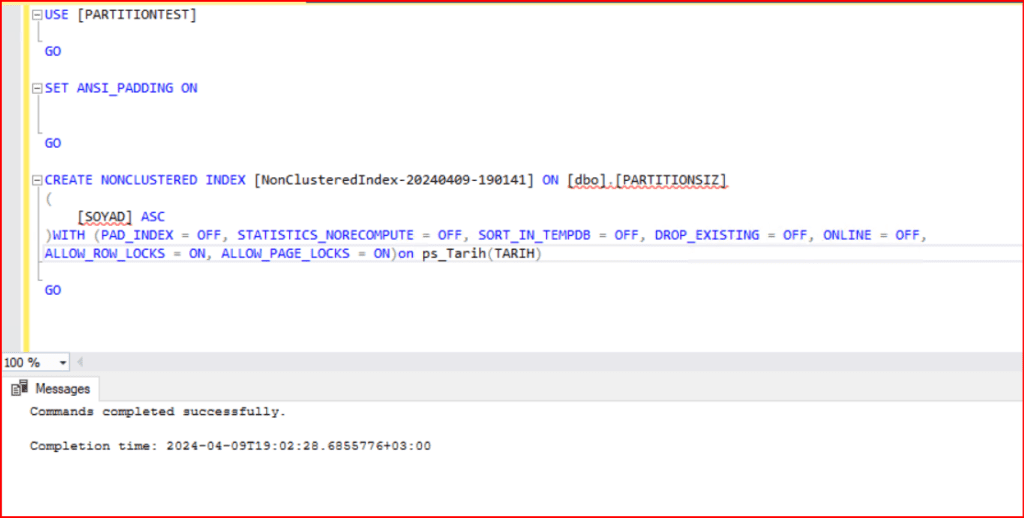
Şimdi tablomuzu partition’lı yapıya geçirmek için ID kolunuma clustered indexs tanımlıyorum. Burada online on yapıp tablomu erişilebilir durumda olmasını sağlıyorum. Ya da belirli maxdop ayarı verilebilir.
USE [PARTITIONTEST]
GO
CREATE UNIQUE CLUSTERED INDEX [ClusteredIndex-IX_PARTITIONSIZ] ON [dbo].[PARTITIONSIZ]
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = ON, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON ps_Tarih(TARIH)
GO
Aşağıdaki görüldüğü gibi bir hatayla karşılaştım.
Msg 1908, Level 16, State 1, Line 5
Column ‘TARIH’ is partitioning column of the index ‘ClusteredIndex-IX_PARTITIONSIZ’. Partition columns for a unique index must be a subset of the index key.
SQL Server Kuralı:
Eğer partitionlı bir tabloda UNIQUE index oluşturuyorsan: Partition yaptığın kolon(lar) UNIQUE index key’inin içinde olmak zorundadır. Şöyle düşünmek gerekir unique index tanımlı bir kolonda ikinci bir aynı değere sahip ID değeri olmaz. İmkansızdır. Ama partition yapılarında unique index farklı çalışır. Partition yapısı aynı ID değerinin kendi partition içerisinde de olabileceği ihtimaline karşılık unique index olan indexlerin içerisine partition kolonunda gelmesini ister. Partition yapısına özgü bir kuraldır.
Eğer partition yapılan tabloyu ID gibi bir kolonla UNIQUE yapmanı istiyorsan, o zaman partition key’ini de index key’e dahil etmen gerekir. Böylece SQL Server, partitionlar arasındaki farklı veri kümelerini hesaba katarak her partition’daki ID’yi benzersiz yapar.
Not: non-clustered unique index’lerde de aynı partition column ve index key ilişkisi geçerlidir. Yani, partition edilmiş bir tablodaki non-clustered unique index için de, partition yaptığın kolon(lar) index key’ine dahil edilmelidir. Bunun sebebi, SQL Server’ın partitionlı tablolarda partitionlar arasında veri tekrarı olmaması gerektiğini sağlamaktır. Eğer partitioning kullanıyorsan, SQL Server partition key’ini index key’e dahil etmezsen, partitionlar arasında aynı değerin tekrarına izin verir, çünkü SQL Server partitionlar arasındaki bağımsızlığı göz önünde bulundurur.
Eğer ilgili kolunumuz unique ise ve ilgili partition’lı kolunda belirtilmemişse bizden partition’lı TARIH kolonumuzuda istemektedir. Bu olay bu tabloda kaçta unique index tanımlarsak aynı hatayı verecektir. Kodumuzun aşağıdaki şekilde düzeltilmesi gerekiyor.
USE [PARTITIONTEST]
GO
CREATE UNIQUE CLUSTERED INDEX [ClusteredIndex-IX_PARTITIONSIZ] ON [dbo].[PARTITIONSIZ]
(
[ID] ASC,
[TARIH] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = ON, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON ps_Tarih(TARIH)
GO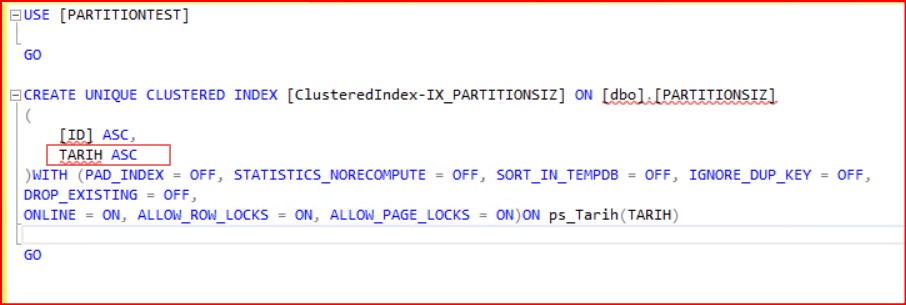
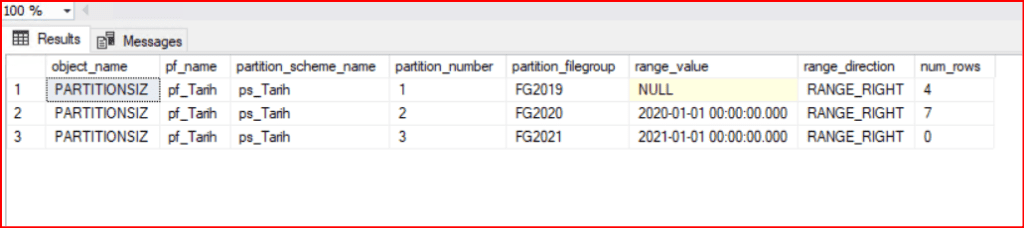
Kontrol işlemi yapıldıktan sonra tablomuzun partition yapısına geçtiğini görmüş oluyoruz.
use PARTITIONTEST
SELECT
OBJECT_NAME(si.object_id) AS object_name
,pf.NAME AS pf_name
,ps.NAME AS partition_scheme_name
,p.partition_number
,ds.NAME AS partition_filegroup
,rv.value AS range_value
,(
CASE pf.boundary_value_on_right
WHEN 0
THEN 'RAGE_LEFT'
ELSE 'RANGE_RIGHT'
END
) AS range_direction
,SUM(CASE
WHEN si.index_id IN (
1
,0
)
THEN p.rows
ELSE 0
END) AS num_rows
FROM sys.destination_data_spaces AS dds
INNER JOIN sys.data_spaces AS ds ON dds.data_space_id = ds.data_space_id
INNER JOIN sys.partition_schemes AS ps ON dds.partition_scheme_id = ps.data_space_id
INNER JOIN sys.partition_functions AS pf ON ps.function_id = pf.function_id
LEFT JOIN sys.partition_range_values AS rv ON pf.function_id = rv.function_id
AND dds.destination_id = CASE pf.boundary_value_on_right
WHEN 0
THEN rv.boundary_id
ELSE rv.boundary_id + 1
END
LEFT JOIN sys.indexes AS si ON dds.partition_scheme_id = si.data_space_id
LEFT JOIN sys.partitions AS p ON si.object_id = p.object_id
AND si.index_id = p.index_id
AND dds.destination_id = p.partition_number
LEFT JOIN sys.dm_db_partition_stats AS dbps ON p.object_id = dbps.object_id
AND p.partition_id= dbps.partition_id
WHERE si.object_id = OBJECT_ID('[dbo].[PARTITIONSIZ]')
GROUP BY ds.NAME
,p.partition_number
,pf.NAME
,pf.type_desc
,pf.fanout
,pf.boundary_value_on_right
,ps.NAME
,si.object_id
,rv.value
ORDER BY p.partition_number
Not: Önceden clustered index olarak oluşturulmuş bir index yapısı tekrardan aynı index üzerinde Drop_existing=on ifadesiyle oluşturulabilir. Create komutunda aynı index isminin olması gerekmektedir.
SSMS arayüzünde herhangi bir index oluşturulacağı zaman Storage kısmında partition scheme yapısı seçilmelidir.
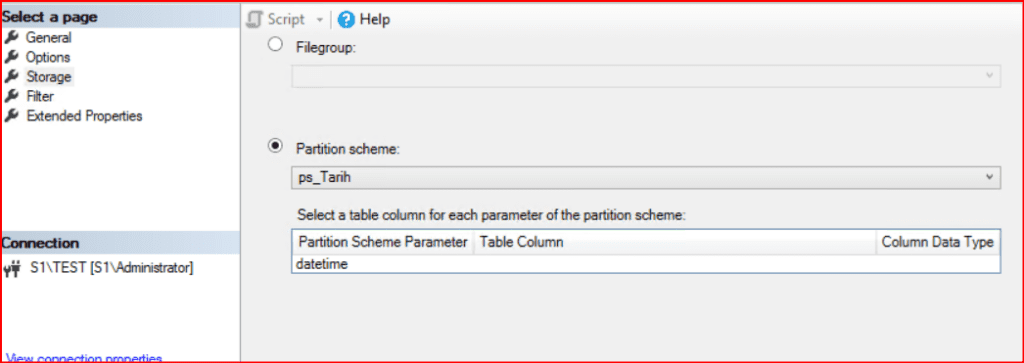
Partition’lı tabloda herhangi bir sıkıntı yaşamamak için yeni oluşturulacak her indexs ps_Tarih scheme yapısına göre oluşturulması gerekmektedir.
Unique index’lerde partition column’un index key’ine eklenmesi zorunludur, çünkü partitioning ve unique index’in amacı veri bütünlüğü ve benzersizlik sağlamak için birlikte çalışır.
Non-unique index’lerde partition column’un index key’ine dahil edilmesi gereksizdir, çünkü bu tür index’ler sadece performans optimizasyonu sağlar ve veri bütünlüğü sağlamaz. Bu nedenle veri tekrarına izin verilir ve partition column yalnızca veriyi fiziksel olarak böler.
Yukarıda görmüş olduğumuz gibi partition’lı tablolarda ps_Tarih(TARIH) ifadesinin belirtilmesi gerekir. Switch over işlemlerimizde sıkıntı olmasın diye yukarıda dikkat edersek tarih kolonunu eklemedik çünkü oluşturmuş olduğum indexs unique değil. Eğer unique olsaydı tarih kolonumuz eklenir olurdu.
Burada dikkat edersek herhangi bir koluna eklenmesi yeterli tablo hemen partition’lı yapıya geçiyor.
Belirtilen makalede veritabanı altında bulunan partition yapılmış tabloları bulabilirsiniz. Bu yapmış olduğumuz indexs’te tablomuzda herhangi bir indexs yok ama eğer tablomuz partition’sız yapılmışsa ve indexs bazı kolunlarda varsa ilgili kolundaki indexs’in değiştirilmesi gerekiyor. Online on maxdop veya değişik parametreler kullanarak.
Not: Sorgularınızda performans anlamında iyi bir sonuç elde etmek istiyorsanız. Partition kolonun where koşulunda olması gerekmektedir. Sql server tüm partition’ı taramak zorunda kalır.
Not: Aligned Index = Partition Scheme ile Uyumlu İndeks Eğer bir indeks, tablonun bölümleme fonksiyonu (Partition Function) ve şeması (Partition Scheme) ile aynı sütuna ve aynı fiziksel yapıya göre oluşturulmuşsa, otomatik olarak “aligned” kabul edilir. Eğer indeks, farklı bir dosya grubunda (PRIMARY gibi) veya farklı bir bölümleme şemasıyla oluşturulursa, non-aligned olur. Normal oluşturulan index yapılarımız diyebiliriz.
Başka makalede görüşmek dileğiyle..
“Böyle birine âyetlerimiz okunduğunda sanki kulaklarında ağırlık varmış da onu işitemiyormuş gibi büyüklük taslayarak sırt çevirir. Ona acıklı bir azabı müjdele!”Lokman-7