
Bu makalede sıfırdan Partition tablo nasıl oluşturma konusunu detaylı bir şekilde görmüş olacağız. Parçalanmış tablo yani partition table Microsoft tarafından SQL Server 2005 ile birlikte kullanıcılara sunulan bir özelliktir. SQL Server Enterprise Edition tarafından desteklenen bir özelliktir. Partitioning kullanılan bir database Enterprise olmayan bir sunucuya restore edemeyiz. (lisans maliyeti vb.). Herhangi bir veritabanı özelliği değiştirilmeden tablo bazlı yapılan bir işlemdir. Tablodaki veriler üzerinde herhangi bir değişiklik yapmadan kuracağımız partition performans anlamında tablomuza çok iyi bir katkı sunmaktadır. Tablomuzdaki partition kolununda herhangi bir arama işleminin yapılması sonucu tablodaki tüm veriler üzerinde arama işlemini yapmayıp ilgili tanımlanmış olan filegroup üzerinde işlem yapmamızı sağlayacak bu yapıda disk kullanımın fazla olmamasını sağlayacak ve bize performans anlamında ciddi katkılar sunacaktır. Kısacası elzem bir durum olmadıkça önceki yıllara ait veriler sorgulanmaz ve bu da bize partition yapının olmasını sağlamaktadır. Yoksa bu gereksiz kayıtlarında sorgulanması demektir. Partition table ile bütün veriler üzerinden değil de ilgili veriler üzerinde çalışır.
Aşağıda yapacağım örnek yıl yıl partition işlemi kullanıcı o yıla ait herhangi bir arama yaptığında ilgili partition’a gitmiş olacak buda bize hız anlamında ciddi katkı sağlayacaktır.
Kısacası partition verilerin okumasında yedekleme işlemlerinde(read-only yapılırsa) indexs bakım işlemlerinde bu avantajlar sunmaktadır.
Partition yapılmış iki kolun üzerinde herhangi bir join işlemi gerçekleşecekse performans anlamında ciddi katkılar sunabilir.
Performans alabilmek için Partition yaparken kullandığımız key alanımız bu tabloya erişirken kullanacağımız sorgularda kullanılmalıdır. (Aksi durumda Partition’ın bir faydası olmayacaktır, dahası eski halinden daha kötü bir sorgulama performansı verebilir.)
Partition key, sorgunun WHERE koşulunda mutlaka kullanılmalı. Aksi takdirde SQL Server, tüm partition’lar üzerinde tarama yapar (partition scan), bu da performans kaybına neden olur. WHERE koşullarında partition key’in ilk sırada olması gerekmez, SQL Server sorguyu optimize ederken bunu sıralamaya göre değil, içerik ve istatistiklere göre değerlendirir. Where koşullarının aşağıdaki yöntemlerle kullanılması partition yapısında kötü bir etkiye sebep olmaz.
WHERE PartitionKey = '2024-01-01'
WHERE PartitionKey BETWEEN '2024-01-01' AND '2024-12-31'Aşağıdaki şekilde kullanılması partition yapısını kullanmaz.
WHERE YEAR(PartitionKey) = 2024 -- KötüPartition key doğru şekilde kullanıldığında, SQL Server yalnızca ilgili partition’lara erişir. Bu olaya partition elimination denir ve bu performans açısından kritiktir.
Partition yapılacak kolonun NOT NULL olması zorunludur. SQL Server’da bir tabloyu partition ederken: Partition key kolonu NULL değer içeremez.
Eğer tablonuzda bazı kayıtlar NULL içeriyorsa ve partition yapmak istiyorsan, şu yolları düşünebilirsin:
- NULL kayıtları ayrı bir staging tabloda tut.
- Ya da NULL’lar için özel bir tarih (örneğin ‘1900-01-01’) kullanarak partition key’i dolu hale getir.
Bir tablonun partition yapısına geçirilebilmesi için aşağıdaki ifadelerin ilgili tabloda mutlaka olması gerekmektedir.
- Partition Key Kolonu NOT NULL olmalı Partition key kolonu bu koluna göre yapılmaktadır.
- Partition edilmiş tabloda mutlaka clustered index olmalı. Yoksa tabloyu partition edemezsin.
Son kullanıcı bir tabloyu partition yapılması için kapınızı çalarsa şu sorular sorulabilir. İlk olarak partition yapılacak tablonun boyutu öğrenilmelidir. Küçük tablolarda partition fayda sağlamaz. Sorgularınızın partition yapılacak key’e göremi sorgulandığı. Parition yapılacak uygun NOT NULL kolunun olup olmadığı. Önceki verilerin güncellenip güncellenmediği çünkü update işlemleri, partition’lı tablolarda doğru yönetilmezse performans kaybı veya beklenmedik davranışlara neden olabilir. Eğer partition olan kolunumuz değişirse page split, row migration,Fragmentation, triger tetiklemesi ve performans bozulmalarına sebep olur. Mümkünse update yerine delete insert yapılması update değerine göre daha iyidir. Partition key dışında diğer kolonlarda herhangi bir güncelleme ve değişiklik herhangi bir soruna sebep olmaz.
Genel olarak update ifadeleri OLTP sistemlerinde sıkıntıya sebebiyet vermektedir.
Şimdi bir örnek üzerinden konuyu anlamaya çalışalım. Bu makale ve bundan sonraki makalemde aynı tablo isimleri ve aynı yapıyla çalışmaya çalışacağım sadece her bir makaledeki örnekler için tabloları silip tekrardan sıfırdan oluşturmaya çalışacağım.
Örneğimize geçmeden önce partition tablo oluşturduğumuzda verileri neden farklı filegroupta oluşturma gereği duyarız. Filegroup, SQL Server’da mantıksal bir veri depolama yapısıdır. Ama gerçek performans farkı, filegroup’ların arkasındaki .mdf/.ndf dosyalarının fiziksel olarak farklı disklerde olmasıyla oluşur. Eğer 4 farklı filegroup oluşturdun ama hepsi aynı disk altındaki .ndf dosyalarına gidiyorsa: I/O aynı diskten geliyor → Disk kuyrukları, beklemeler olur → Gerçek bir performans kazanımı olmaz.
Gerçek performans için yapılması gerekenler: Her filegroup farklı disk veya RAID grubu üzerinde performans anlamında çok iyi bir katkı sağlamaktadır. Filegroup’ların hepsi aynı fiziksel diskte üzerinde ise sadece mantıksal olarak bölümlenme yapılmışsa performans anlamında pek katkısı yoktur. Kısacası hepsinin aynı disk yolu üzerinde farklı filegrouplarda olması primary filegroupta olmasıyla aynıdır.
Peki Neden Yine de Filegroup Kullanıyoruz?
Şu durumlar için mantıksal avantaj sağlar:
- Eski verileri ayrı bir filegroup’a alıp sadece o filegroup’u backup alabilirsin.
- Partition SWITCH veya SPLIT gibi işlemleri filegroup bazında yapabilirsin.
- Bakım (index rebuild vs.) sırasında daha rahat kontrol sağlarsın.
- Gelecekte farklı disklere taşımayı kolaylaştırır.
Ama eğer bu filegroup’lar aynı fiziksel disktelerse, performans için bir fark yaratmaz.
PRIMARY üzerinde partition yaparsan, Mantıksal partitioning olur, fiziksel bölünme olmaz. Partition yapını PRIMARY filegroup’a atarsan, yapı çalışır ama performans açısından filegroup ayrımının sana sağlayacağı kazancı elde edemezsin.
Partition’ı kurgularken arka tarafta filegroup gibi sanal ve data file gibi fiziksel objeleri de iyi planlamak gerekir. Şart değil ancak önerilir. Amaç ilerleyen aşamalarda verilemize daha hızlı erişebilmektir.
İlk başta partition yapımız için filegroup oluşturuyoruz ve bunun altında ilgili data file’lar tanımlıyoruz. Partition’ı oluştururken her partition’ı farklı filegroup’lara koyabiliyorsunuz. Filegroup’ları da farklı disklere koyarak I/O performans artışı sağlayabiliyorsunuz.
USE [master]
GO
ALTER DATABASE [PARTITIONTEST] ADD FILEGROUP [FG2019]
GO
ALTER DATABASE [PARTITIONTEST] ADD FILE ( NAME = N'FG2019', FILENAME = N'C:\FG\FG2019.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FG2019]
GO
GO
ALTER DATABASE [PARTITIONTEST] ADD FILEGROUP [FG2020]
GO
ALTER DATABASE [PARTITIONTEST] ADD FILE ( NAME = N'FG2020', FILENAME = N'C:\FG\FG2020.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP
[FG2020]
GO
GO
ALTER DATABASE [PARTITIONTEST] ADD FILEGROUP [FG2021]
GO
ALTER DATABASE [PARTITIONTEST] ADD FILE ( NAME = N'FG2021', FILENAME = N'C:\FG\FG2021.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP
[FG2021]
GO
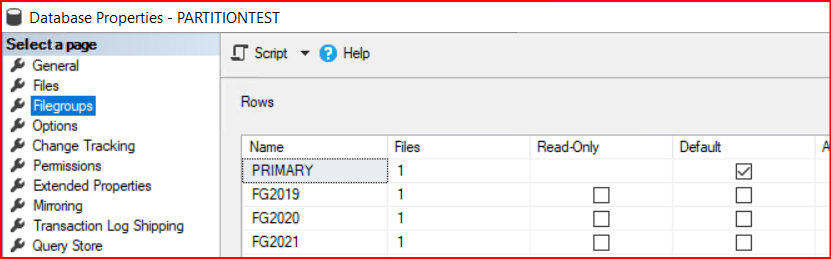

File group ve data file’larımızı oluşturduk.
Sırada elimizde function ve scheme’mızı oluşturmak. İlk başta function oluşturulur. Bu işlemler veritabanı bazında yapılır. Her veritabanı için ayrı function ve schema oluşturulur.
CREATE PARTITION FUNCTION [pf_Tarih](datetime) AS RANGE RIGHT FOR VALUES (N'2020-01-01T00:00:00.000', N'2021-01-01T00:00:00.000')NOT: RANGE RIGHT ve RANGE LEFT ifadeleri, SQL Server’da partitioning yapılırken sınır değerlerin hangi partition’a ait olduğunu belirler.
RANGE RIGHT: Bu ifade tarih kolununda belirtilen değere eşit olmadığını gösterir. 2020 yılı önceki değerlerin hepsini kapsar 2020 yılının ilk değerini kapsamaz. Kısacası görülen tarih sonraki partition schema’ya aittir. 2021<= aralık_değeri<2022 bu şekilde
1. Partition için tarih aralığı (Tarih<2020.01.01)
2. Partition için tarih aralığı (2020.01.01=<Tarih) AND (Tarih<2021.01.01)
3. Partition için tarih aralığı (2021.01.01=<Tarih)
RANGE LEFT: Bu ifade ise yukarıdaki right ifadesinin tam tersidir. 2021< aralık_değeri<=2022 bu şekilde bir anlamı vardır.
1. Partition için tarih aralığı (Tarih=<2020.01.01)
2. Partition için tarih aralığı (2020.01.01<Tarih) AND (Tarih=<2021.01.01)
3. Partition için tarih aralığı (2021.01.01<Tarih)
Tarih değerlerine göre parçaya ayırdığımız veri bloklarını fiziksel olarak nerede tutulacağını Partition Scheme ile belirtiyoruz. Burada her parça için ayrı FileGroup belirlenmiştir.
Partition yapılarında partition scheme içinde tanımlanan filegroup sayısının, value (bölümleme aralık) sayısından bir fazla olması gerekiyor. Bu gerçekten SQL Server’da partition mantığının temel kurallarından biridir. Dikkat ederseniz yukarıda sadece iki tarih değeri girildi. n değer → n+1 partition → n+1 filegroup
Son Partition Tehlikesi
- Son Partition için tarih aralığı (2021.01.01=<Tarih) sınırı açık uçludur.
- Eğer veri buraya giriyorsa ve sen SPLIT yapıp yeni aralık eklemiyorsan, tüm yeni yıllar bu tek partition’da birikir. İlerleyen makalelerde Split işlemiyle yeni function ve scheme ekleme işlemini görmüş olacağız.
- Bu da:
- Partition elimine etmeyi zorlaştırır
- Tek partition’da veri şişer
- Bakım ve performans açısından sıkıntı çıkarır.
Son partition’a henüz veri gelmeden SPLIT işlemiyle bir sonraki yılı açılması gerekmektedir. SQL Agent Job ile ay başlarında otomatik olarak bir yıl sonrasını SPLIT eden script yazılabilir (çok yaygın bir çözümdür).
Not: Split işlemi yapılmazsa son partition yapımıza veriler geldiğinde ne olur. Eski yıllar kendi partition’larında kaldığı için performans anlamında hâlâ hızlı çalışır. Ama yeni veriler, sen partition bölmezsen, tek yerde birikir. Bu yüzden o yeni tarihli sorgular yavaşlar. Bizim örneğimize göre 2021.01.01<Tarih 2021 yılı verisi gelmeden Split yapılırsa partition bozulmaz. Veri geldikten sonra partition yapısı bozulmaktadır. Her şey son partitionda birikmektedir.
CREATE PARTITION SCHEME [ps_Tarih] AS PARTITION [pf_Tarih] TO ([FG2019], [FG2020], [FG2021])Şimdi burada 2020 yılı ve önceki verileri FG2019’a yazılır her yıl bir önceki FG’ye yazılır. 20 ile 21 arasındaki veriler FG2020’ye yazılır. 2021 yılından sonraki veriler FG2021 e yazılır.
Not: Function ve scheme eklendiğinde scheme sayısının 1 fazla olacağını yukarıda belirtmiştik. Fazladan filegroup ve scheme oluşturulmak isteniyorsa n+1 kuralına uyacak şekilde yapılandırılmanın yapılması gerekmektedir. Aksi taktirde partition tablomuz bozulmaktadır.
Şimdi ise bir tablo oluşturalım ve bu tablomuzu partition scheme’mızı ekleyerek partition’lı yapıya getirelim.
CREATE TABLE ORNEKTABLO(
ID INT IDENTITY(1,1) NOT NULL,
AD VARCHAR(50) NULL,
SOYAD VARCHAR(50) NULL,
TARIH DATETIME NOT NULL
)ON ps_Tarih(TARIH)Şimdi bakalım partition işlemimiz doğru olmuş mu? Aşağıdaki komutla kontrol edilmektedir.
use [ORNEKTABLO]
SELECT
OBJECT_NAME(si.object_id) AS object_name
,pf.NAME AS pf_name
,ps.NAME AS partition_scheme_name
,p.partition_number
,ds.NAME AS partition_filegroup
,rv.value AS range_value
,(
CASE pf.boundary_value_on_right
WHEN 0
THEN 'RAGE_LEFT'
ELSE 'RANGE_RIGHT'
END
) AS range_direction
,SUM(CASE
WHEN si.index_id IN (
1
,0
)
THEN p.rows
ELSE 0
END) AS num_rows
FROM sys.destination_data_spaces AS dds
INNER JOIN sys.data_spaces AS ds ON dds.data_space_id = ds.data_space_id
INNER JOIN sys.partition_schemes AS ps ON dds.partition_scheme_id = ps.data_space_id
INNER JOIN sys.partition_functions AS pf ON ps.function_id = pf.function_id
LEFT JOIN sys.partition_range_values AS rv ON pf.function_id = rv.function_id
AND dds.destination_id = CASE pf.boundary_value_on_right
WHEN 0
THEN rv.boundary_id
ELSE rv.boundary_id + 1
END
LEFT JOIN sys.indexes AS si ON dds.partition_scheme_id = si.data_space_id
LEFT JOIN sys.partitions AS p ON si.object_id = p.object_id
AND si.index_id = p.index_id
AND dds.destination_id = p.partition_number
LEFT JOIN sys.dm_db_partition_stats AS dbps ON p.object_id = dbps.object_id
AND p.partition_id= dbps.partition_id
WHERE si.object_id = OBJECT_ID('[dbo].[ORNEKTABLO]')
GROUP BY ds.NAME
,p.partition_number
,pf.NAME
,pf.type_desc
,pf.fanout
,pf.boundary_value_on_right
,ps.NAME
,si.object_id
,rv.value
ORDER BY p.partition_number

Şimdi yukarıda bulunan tablomuza manuel kayıt insert edelim. Şuna da değinmek gerekiyor partition yapısı aslında yeni kurulacak sistemlerde veya tablolarda veriler gelmeden önce baştan oluşturulması gerekiyor. Herhangi bir veritabanı kurarken kullanıcıya ilettiğimiz sorunlardan bir tanesi tablolarınız büyüklüğü şeklinde eğer bunun gibi bir yapı varsa tablo yukarıdaki gibi ilk kurulurken bu yapıya dönüştürülür.
insert into ORNEKTABLO([AD], [SOYAD], [TARIH])values('YUNUS','YUCEL','20200402')
insert into ORNEKTABLO([AD], [SOYAD], [TARIH])values('YUNUS','YUCEL','20200302')
insert into ORNEKTABLO([AD], [SOYAD], [TARIH])values('YUNUS','YUCEL','20200102')
insert into ORNEKTABLO([AD], [SOYAD], [TARIH])values('YUNUS','YUCEL','20150102')Tekrar yukarıdaki kontrol sorgumuzu çalıştırdığımda partition işleminin gerçekleştiğini görüyorum. Eğer son yıla veri atmış olursam partition yapısı bozulur.

2020 yılına ait 4 insert daha gerçekleştirelim.

SELECT *
FROM [dbo].[ORNEKTABLO]
WHERE $PARTITION.[pf_Tarih]([TARIH]) =2
ORDER BY [TARIH] ASC ;Hangi partition’da ne kadar kayıt olduğumuzu yukarıdaki komut ile görebiliriz. İlgili partition numarasını yazarak diğer partitionları görebiliriz.

Partition yapısısında 2 senaryo vardır.
- Senaryo tablomuzu en başta içinde veriler olmadan oluşturulması
- Senaryo partition yapıda yeni bir tablo oluşturup içerisine partitonsuz tablodan veriler atmaktır. Partition yapısı tablolardada bu yöntem yapılabilir.
Hangi partition’da kaç kayıt olduğunu aşağıdaki komutlada bulabiliriz.
SELECT partition_id, object_id, partition_number, rows
FROM sys.partitions
WHERE object_id= OBJECT_ID('ORNEKTABLO')

Ek Bilgi:
SQL SERVER 2016 ile birlikte gelen truncate table partition yapısıyla partition tablomuzda istediğimiz partition’da verileri silme işlemini gerçekleştirebiliriz. Aşağıdaki komut ile ilgili partition daki veriler silinebilir.
TRUNCATE TABLE ORNEKTABLO WITH (PARTITIONS (1));Truncate table delete ifadesine göre verileri silerken herhangi bir log kaydı tutmaz bu yüzden daha hızlıdır ama delete ifadesindeki gibi istediğimiz bir değeri silemeyiz.

Birden fazla partition verileri silinmek isterse ilgili komut kullanılır.
TRUNCATE TABLE canliveri WITH(PARTITIONS(1, 2,4))Partition tablomuz hakkında bilgi almak için tablomuzun properties ekranından bulunan storage kısmından gerekli inceleme yapılabilir.

Insatance ve veritabanı altındaki partition tabloları bulmak için ilgili makale okunmalıdır.
Not: Partition yapısı bozulmuş bir tablo üzerinde yeni bir partition yapısı farklı filegroup kullanarak oluşturulmak istenirse yeni partition yapısına veriler atılır. Eski filegroup üzerinden yukarıdaki partition kontrol komutumuzla veriler olmadığı anlaşıldıktan sonra ilgili filegrouplar silinebilir.
Not: Partition tablosu olan bir veritabanının disk alanı maksimum boyuta ulaştıktan sonra sunucu üzerinde bulunan local diskler olmasından dolayı disk artırılımı geçerleştirilememiş. Bunun için ne yapılması gerekmektedir. Çünkü partition yapılmış tablonun partition yapısının bozulmaması gerekmektedir.
Şöyle bir senaryo yapılabilir. Partition yapısının devam etmesi için aynı filegroup altında yeni bir data file oluşturulması gerekmektedir. Veritabanı altında bulunan diğer tablolar için farklı bir filegroup veya primary filegroup altında yeni bir data file oluşturularak verilerin buradan devam edilmesi sağlanabilir. Diğer yılların partition filegroupları değiştirilebilir tabi yeni veriler gelmeden önce. Yani filegroup aynı kalacak ama data file değiştirilmesi gerekmektedir. Sadece Partition file group haricinde diğer veritabanı filegroup üzerinden kesin büyümesi için eski disk üzerinde olan filegroupların auto growth değeri NONE yapılması gerekmektedir.
Dikkat edilmesi gereken partition yapımız değişmez aynı filegroup a bir tane daha data file eklenmektedir.
Başka bir makalede görüşmek dileğiyle..
“İnsanlar arasında öyleleri vardır ki bilgisizlik yüzünden başkalarını Allah yolundan saptırmak ve o âyetleri alay konusu etmek için eğlendirici sözler kullanırlar; işte bunları alçaltıcı bir azap bekliyor.”Lokman-6