
Bu makalede NonClustered Index’in ne olduğunu detaylı bir şekilde görmüş olacağız. SQL Server’da çeşitli index türleri bulunur, ancak en yaygın kullanılanları şunlardır:
Aşağıdaki komut yardımıyla tablo altında bulunan clustered ve nonclustered index yapılarımızı görebilir. Bu stored procedure yardımıyla hangi kolonlara index atıldığı hangi filegroup üzerinde olduğu görülebilir.
EXEC sp_helpindex 'Person.Person'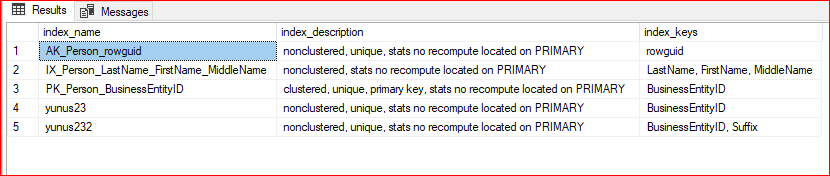
Bir tabloya birden fazla non-clustered index ekleyebilirsiniz. Non-clustered index ler, tablonun fiziksel düzenini değiştirmezler, ancak index sütunlarını sıralarlar. Non clustered index koyulan kolonlar tablodan bağımsız olarak diskte ayrı bir şekilde tutulur. Bu yüzden ekstra yer kaplarlar ve tabloda çok fazla non-clustered index varsa her insert, update ve delete işlemi tablonun haricinde bu tablodaki bütün nonclustered index’lere de uygulanacağı için insert,update ve delete performansı yavaşlayacaktır. Bu yüzden çok fazla nonclustered index oluşturmak her zaman iyi bir şey değildir. Sql server 2005 ve öncesinde tabloda 249 adet NONCLUSTERED index oluşturulabilir. SQL Server 2008 ve Sonrası (2012, 2014, 2016, 2017, 2019, 2022)tablo başına 999’a kadar çıkar.
NonClustered Index’te arama yaparken Leaf Level’e ulaştığımızda verinin kendisi yerine Row Locator bulunur.
Eğer tablo heap ise(tabloda clustered index yoksa) row locator olarak pointer /Row ID(RID) bulunur. Arama yaparken Leaf Level’a gelindiğinde row id kullanılarak ilgili kayda ulaşılır. Bu işlem RID Lookup olarak geçer. İyi bir şey değildir. Tablonuza mutlaka bir clustered index koyun.
Eğer tablo heap değilse(clustered index varsa) row locator olarak Clustered Index Key vardır. Arama yaparken Leaf Level’a gelindiğinde clustered index key kullanılarak ilgili kayda ulaşılır. Bu işlem Key Lookup olarak geçer. Tablo nonclustered index’e göre sıralı olmadığı için, non clustered index tablonun dışından ekstra bir alan kullanılarak oluşturulduğu için bir tabloda birden fazla sayıda olabilir. Unique te olabilir non unique’te olabilir. Unique olursa aramalar daha hızlı sonuç döner. Unique işlemlerinde seek işlemi yapılırken, non unique’te işlemlerinde scan işlemi yapılmaktadır.
Non-Clustered İndeks Çeşitleri:
- B-tree: En yaygın non-clustered indeks türüdür. Dengeli bir ağaç yapısı kullanır ve çok çeşitli sorgu türleri için uygundur.
- Full-text: Metin verilerinde kelime veya ifade aramaları için kullanılır. Kelime kökleri, eş anlamlılar ve yakınlık aramaları gibi gelişmiş arama özellikleri sunar.
- Spatial: Coğrafi ve geometrik veriler için kullanılır. Uzamsal veriler üzerindeki sorguları hızlandırır.
- XML: XML verileri indekslemek için kullanılır. XML verileri üzerinde XPath sorguları yapmanızı sağlar.
- Columnstore: Büyük veri kümeleri için tasarlanmıştır. Veriyi sütun bazında depolar ve sıkıştırır, bu da analitik sorguların performansını önemli ölçüde artırır. Clustered ve non-clustered columnstore indeksleri mevcuttur.
- Filtered: Belirli bir filtreye uyan verileri indeksler. Bu, nadiren kullanılan verileri indekslemekten kaçınarak indeks boyutunu ve bakım maliyetini azaltır.
- Unique: Yinelenen değerlere izin vermez. Birincil anahtar ve benzersiz kısıtlamalar için kullanılır.
Aşağıdaki iki komut kullanılabilir. Manuel script’le aşağıdaki gibi oluşturulabilir.
CREATE INDEX [NonClusteredIndex_Table1_id] ON [dbo].[Table_1] (id);SSMS arayüzünden oluşturulması isteniyorsa aşağıdaki komut kullanılmaktadır.
CREATE NONCLUSTERED INDEX [IX_Person_BusinessEntityID_FirstName_LastName] ON [Person].[Person]
(
[BusinessEntityID] ASC,
[FirstName] ASC,
[LastName] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, Maxdop=16, fillfactor=90)
GOClustered index olmayan heap tablolara nonclustered index eklenebilir. Heap tablolarda sys.dm_db_index_physical_stats DMV’si sorgulandığında fragmentation değerleri NULL olarak dönebilir, çünkü heap’lerin geleneksel anlamda “fragmentation”ı yoktur. Ancak heap’lerde forwarding pointers (yönlendirme işaretçileri) oluşabilir ve bu da bir tür fragmentation sayılabilir. Genellikle index bakım jobları heap tabloları atlar çünkü geleneksel index fragmentation’ı yoktur. A+ncak heap tablolar da satır silme/ekleme işlemleriyle parçalanmaya (fragmentation) uğrayabilir. Forwarding Pointers: Heap’te bir satır güncellendiğinde ve yeni konuma taşınması gerektiğinde oluşur Heap’te Boş Alan: Silinen satırların yarattığı boşluklar. Nonclustered indexler heap tablolarda çalışabilir, ancak bookmark lookup işlemleri clustered indexlere göre daha maliyetli olabilir. İlgili makaleden detaylı bir şekilde bakım çalışmaları yapılabilir.
Veritabanı altında herhangi bir sorguda index force edilebilir.
Select*from tableName with (INDEX=IndexName)Bu makalede nonclustered index yapısını detaylı bir şekilde görmüş olduk.. Başka bir makalede görüşmek dileğiyle..
“Onlar, yaptıkları dünyada ve ahirette boşa gitmiş olanlardır. Ve onların yardımcıları yoktur. Al-i İmran Suresi, 22. Ayet