
Bu makalede Clustered-NonClustered Index Komutları ve aynı zamanda aralarındaki farkı görmüş olacağız. SQL Server’da çeşitli index türleri bulunur, ancak en yaygın kullanılanları şunlardır:
Aşağıdaki komut yardımıyla tablo altında bulunan clustered ve nonclustered index yapılarımızı görebilir. Bu sp yardımıyla hangi kolunlara index altıldığı hangi filegroup üzerinde olduğu görülebilir.
EXEC sp_helpindex 'Person.Person'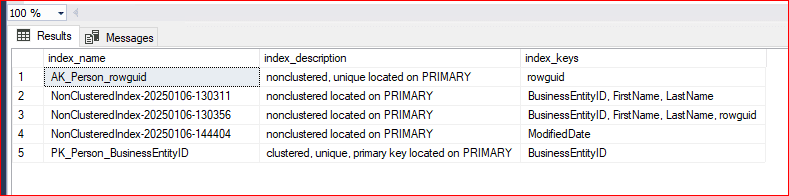
SSMS üzerinden herhangi bir tablo altında clustered veya non clustered index oluşturulmak istendiğinde gelen ortak parametrelerin ne işe yaradığını detaylı bir şekilde görmüş olalım.
Clustered Index:
CREATE UNIQUE CLUSTERED INDEX [ClusteredIndex_Table1_id] ON [dbo].[Table_1]
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GONon-Clustered Index:
CREATE NONCLUSTERED INDEX [IX_Person_BusinessEntityID_FirstName_LastName] ON [Person].[Person]
(
[BusinessEntityID] ASC,
[FirstName] ASC,
[LastName] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, Maxdop=16, fillfactor=90)
GOAşağıdaki komut, bir Non-Clustered Index oluşturmak için kullanılmış ve çeşitli indeks özellikleri tanımlanmıştır. Aşağıda her bir parametre detaylı olarak açıklanmıştır:
- Komutun Temel Yapısı
CREATE NONCLUSTERED INDEX [IX_Person_BusinessEntityID_FirstName_LastName] ON [Person].[Person]
(
[BusinessEntityID] ASC,
[FirstName] ASC,
[LastName] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, Maxdop=16, fillfactor=90)
- CREATE NONCLUSTERED INDEX: Bu komut, bir Non-Clustered (kümeleme olmayan) indeks oluşturur. Non-Clustered indeksler, tablodaki veriyi fiziksel olarak sıralamaz; yalnızca bir referans tablosu oluşturur.
- [IX_Person_BusinessEntityID_FirstName_LastName]: İndeksin adıdır. İsimlendirme standartlarına uygun olarak genellikle tablo ve kolon isimlerini içerir.
- [Person].[Person]: İndeksin oluşturulacağı tablo.
- [BusinessEntityID], [FirstName], [LastName]: İndeksin kapsadığı kolonlar. Burada sıralama (ASC = Ascending) belirtilmiştir.
2. WITH Kısmındaki Parametreler:
Bu kısımda indeks oluşturma işlemine ait çeşitli özellikler tanımlanmıştır.
- PAD_INDEX = OFF
Fill factor değeri leaf node’larda uygulandığını söylemiştik. Bu değerin Intermediate seviyesindeki node’lara da uygulamak istersek fill factor seçeneği ile birlikte pad_index seçeneğini de kullanmalıyız.
- STATISTICS_NORECOMPUTE = OFF
SQL Server’ın indeks üzerindeki istatistikleri otomatik olarak yeniden hesaplayıp hesaplamayacağını belirler. OFF seçeneği SQL Server, indeksin kullanımına bağlı olarak otomatik olarak istatistikleri yeniden hesaplayacaktır. (Varsayılan ayardır.) Performans iyileştirmeleri için önemlidir. Ancak bu işlem devre dışı bırakılırsa istatistikler güncel kalmayabilir. Büyük tablolarda tekrardan istatistik güncellenmesi olmasın diye bu değer On yapılır.
- SORT_IN_TEMPDB = OFF
İndeks oluşturma sırasında sıralama işlemlerinin geçici olarak TempDB’de yapılıp yapılmayacağını belirtir. OFF, Sıralama işlemleri aynı veritabanı üzerinde gerçekleştirilir. Bu yapının avantajı TempDB kullanımı devre dışıdır, ancak bu büyük indekslerde daha fazla I/O kullanımıyla sonuçlanabilir.
SORT_IN_TEMPDB internal database snapshot oluşturur mu:
SORT_IN_TEMPDB=ON ayarı doğrudan snapshot oluşturmaz, ancak farklı bir davranış sergiler:
- Nasıl çalışır?:
- Index oluşturma/rebuild işlemlerinde sıralama işlemleri tempdb’de yapılır.
- Ana veritabanının transaction log yerine tempdb’nin log dosyası kullanılır.
- Ana veritabanının log büyümesini azaltır.
- Snapshot ile ilişkisi:
- Doğrudan snapshot oluşturmaz.
- Ancak tempdb kullanımı nedeniyle dolaylı olarak performans etkisi olabilir.
- Büyük index işlemlerinde log şişmesini engellemek için kullanışlıdır.
- DROP_EXISTING = OFF
Eğer mevcut bir indeks varsa, bu indeksin yeniden oluşturulup oluşturulmayacağını belirler. OFF, Mevcut bir indeksin üzerine yazılmaz, yeni bir indeks oluşturulur. Eski bir indeksi performans artırıcı bir şekilde yeniden oluşturmak için DROP_EXISTING = ON kullanılabilir.
- ONLINE = OFF
İndeks oluşturma işlemi sırasında tablonun diğer işlemler tarafından erişilebilir olup olmadığını belirler. OFF, Tablodaki diğer işlemler indeks oluşturma sırasında kısıtlanır (kilitlenir).
Online olarak indeks oluşturmak için ONLINE = ON kullanılabilir, bu da sistemin kesintisiz çalışmasını sağlar (daha fazla kaynak gerektirir). Enterprise ve Developer Edition’da kullanılabilir. Standard Edition’da desteklenmez.
SQL Server genellikle okuma ve yazma işlemlerine izin verir, yani işlemler kesintiye uğramadan devam etmelidir. index oluşurken herhangi bir lock olmamasına rağmen index sonlarına doğru lock işlemi gerçekleşmektedir. Bu sebepleri açıklayalım.
Final Schema Modification Lock (Sch-M) ONLINE=ON kullanarak index oluştururken, işlem büyük oranda low impact (düşük etkili) şekilde çalışır, yani tabloya okuma/yazma işlemleri devam edebilir. Ancak işlem son aşamaya geldiğinde (yaklaşık son birkaç dakika içinde), SQL Server final aşamada bir *Schema Modification Lock (Sch-M)* almak zorunda kalır. Sch-M lock, tüm yazma işlemlerini (INSERT, UPDATE, DELETE) ve bazı okuma işlemlerini bile durdurur. Bu nedenle dakikalar boyunca sorun yokken, işlemin sonuna doğru lock’lar oluşmaya başlamış olabilir. Çözüm olarak Index oluşturma işlemini daha az yoğun saatlerde yapmak en iyi çözümdür. Partitioning gibi teknikleri kullanarak indeksleme yükünü azaltabilirsin. Eğer büyük tablolar varsa ve indexleme süreci uzun sürüyorsa, bunu parça parça yapmak mantıklı olabilir.
ONLINE=ON ile index oluştururken, SQL Server arka planda transaction log’u kullanarak değişiklikleri takip eder. Eğer transaction log dolmaya başlarsa, SQL Server log dosyasını temizleyene kadar işlemleri yavaşlatabilir veya durdurabilir. Bu durumda write işlemleri yavaşlamaya başlayabilir ve lock oluşabilir. Büyük tablolar üzerinde indeksleme işlemi SQL Server tarafından *paralel (multi-threaded) olarak yürütülür. Eğer sistemde zaten yüksek CPU tüketimi yapan işlemler varsa, SQL Server bu kaynakları optimize etmek için lock mekanizmasını devreye sokabilir. Özellikle veritabanı sorguları + index oluşturma aynı anda CPU’yu zorladığında bu tarz gecikmeler ve lock’lar oluşabilir. Çözüm olarak Maxdop ayarı veya paralelizm ayarı yapılabilir. Bir başka online=on ifadesine lock olacak ifade ise SQL Server, büyük değişiklikler olduğunda istatistikleri otomatik olarak güncelleyebilir (Auto Update Statistics). Eğer bu sırada ONLINE=ON ile indeksleme devam ediyorsa, istatistiklerin güncellenmesiyle indeksleme çakışabilir ve bu da lock oluşturabilir. Özellikle büyük tablolar için auto-update statistics çalışıyorsa, lock süreleri artabilir.
ONLINE=ON parametresi index işlemleri sırasında özel bir snapshot mekanizması kullanır:
- Nasıl çalışır?:
- Online index işlemleri bir internal snapshot benzeri yapı kullanır
- SQL Server, işlem sırasında verinin hem eski hem de yeni versiyonunu tutar
- Kullanıcılar index oluşturulurken verilere erişmeye devam edebilir
- Snapshot farkı:
- Tam bir database snapshot değildir
- Sadece ilgili index için geçici bir versiyonlama mekanizmasıdır
- İşlem tamamlandığında otomatik olarak temizlenir
- Avantajları:
- Uygulama kesintisiz çalışmaya devam eder
- Uzun süren index işlemlerinde kullanışlıdır
- Dezavantajları:
- Daha fazla tempdb kullanımına neden olur
- İşlem normalden daha uzun sürebilir
- Ek kaynak tüketimi yaratır
- ALLOW_ROW_LOCKS = ON
İndeks üzerinde satır düzeyinde kilitlemeye izin verir. ON, SQL Server, satır bazında kilitleme yapabilir. Bu, işlem paralelliğini artırır.
- ALLOW_PAGE_LOCKS = ON
İndeks üzerinde sayfa düzeyinde kilitlemeye izin verir. ON, SQL Server, sayfa bazında kilitleme yapabilir. Bu, daha büyük veri işlemleri için uygundur.
- MAXDOP = 16
İndeks oluşturma işlemi sırasında maksimum paralel iş parçacığı sayısını belirler. İndeks oluşturma sırasında maksimum 16 iş parçacığı kullanılabilir. Daha yüksek iş parçacığı sayısı daha hızlı indeks oluşturma sağlar ancak CPU kullanımını artırabilir.
Not: Sorgularımızın sonuna option(maxdop 1) yazılınca sorgumuz belirtilen maxdop yapısında çalışmaktadır.
- FILLFACTOR = 90
Verilerin tutulduğu leaf node’lardaki data page’lerin yoğunluğunu ayarlamak için kullanılır. Gelen yeni kayıtlar page’lere yazılırken doluluk oranı kontrol edilir, yer varsa ilgili page’e yoksa page ikiye bölünür ve yeni gelecek veri için organize edilir. Her indeks sayfasının ne kadar dolu olacağını belirler. Boş bırakılan kısım gelecekteki eklemeler için ayrılır. Sayfa, %90 dolu olacak şekilde oluşturulur. %10’luk alan gelecekteki veri eklemeleri için ayrılır.
Veri ekleme ve güncellemelerin sık olduğu durumlarda daha düşük bir Fill Factor belirlemek faydalı olabilir.
Eğer indeks büyük bir tablo için oluşturuluyorsa ve çevrim içi erişim önemliyse, ONLINE = ON kullanmanız daha uygun olabilir.
Bu makalede MSSQL Server’da Index Yapısında Kullanılan komutları görmüş olduk. Başka bir makalede görüşmek dileğiyle..
İsraf etmeyin. İsra-26