
Bu makalede Mssql Server Statistics konusunu detaylı bir şekilde ele almış olacağız. İlk olarak sql serverda sorgular nasıl gelir buna değinelim. Sql server sorgu ilk geldiğinde sorgu ilk olarak Relational Engine tarafından karşılanır. Gelen sorguda için ilk olarak söz dizimi kontrolü yapılmaktadır. Söz dizimi doğruysa query parse(parsing tree) oluşturur. Sorguda yazım hataları var mı diye kontrol edilmektedir. Bunu çalıştırmadan önce kendinizde bulabilir veya görebilirsiniz. Yani parsing tree bölümünde ilk kısımda T-sql kurallarına göre herhangi bir yazım hatası var mı diye kontrol işlemi yapmaktadır. Hangi sorgunun ilk çalıştıracağının sıralaması yapılır. Sorguda bulunan stored procedure, functions, tablo gibi ifadelerin var olup olmadığıyla ilgilenmez. Query parse tree işleminin kontrolü yapıldıktan sonra parse işleminin ikinci aşamasında yukarıdaki bahsettiğim stored procedure, table, functions gibi sql server nesneleri var mı bu kontrolü yapmaktadır. Bu kısım parse tree oluşturulmuş değerin tablo ve kolon isimleri sistemdeki nesnelerle eşleştirilir Bu kontrol’ü yapan birim Algebraic olarak adlandırılan kısım tarafından yapılmaktadır. Parse tree, algebraic tree’ye dönüştürülür. En uygun query execution plan bu aşamada belirlenir. Diğer bir ifadeyle Name Resolution olarak adlandırılmaktadır. İsim çözümlenmesi denilmektedir.
Yukarıda yapılan parse işleminde sonra Query Optimizer kısmı gelmektedir. Query Optimizer yapısı parse işleminde ayrılan sorgunun maliyete göre elde etmiş olduğu birden fazla execution plan yapılarını tutmaktadır. Bu execution planlar içerisinde birbirinden farklı maliyetli sorgular olabilir. Genelde sql server en iyisini seçmektedir.
Maliyet derken neyin maliyetini hesaplıyor sql server ?
Burada makalemizin ana başlığı olan statistics yapısının neden sql server için önemli olduğu karşımıza çıkacaktır. İlgili sorgunun maliyeti için sql server I/O ve CPU zamanına bakıp maliyeti hesaplamaktadır. Bu maliyet hesaplaması için sql server verinin dağılımının bulunduğu istatistiklerden faydalanmaktadır. Dikkat ederseniz veriye doğrudan erişmek yerine istatistikleri kullandı. Buda ilerleyen aşamalarda execution planımızla performans yaparken görmüş olacağımız tahmini execution plan(Display Estimated Execution Plan) olarak karşımıza çıkacaktır. Sorgumuz gerçek anlamda çalışmıyor istatistikleri kullanıyor. Kısacası sorgu çalıştığı zaman tablolarda ve indexslerde istatistik verilerini dayanarak bir plan oluşturur.
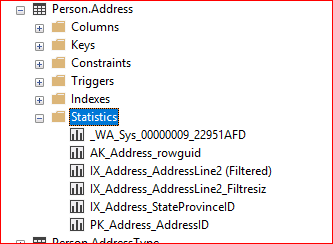
Aşağıdaki resim veritabanı altında bulunan herhangi bir tablonun istatistiklerine nasıl ulaşacağımızı görmüş oluyoruz. İlerleyen bölümlerde istatistiklerin nasıl oluştuğuna değinmiş olacağız.(_WA, Pk gibi..)
Sql server’ın istatistiklerden faydalanarak execution plan yapılanmamızda aşağıdaki yöntemler olarak karşımıza çıkmaktadır. Şimdi bu kavramların ne işe yaradığına değinelim. Kısacası aşağıdaki ifadeler istatistiklerdeki verileri kullanarak execution plandaki kavramların oluştuğunu görmüş olacağız. Aşağıdaki verilere istatistikleri kullanarak ulaşmaktayız.
İndex Scan: Sql server da ilgili kolun üzerinde indexs var ama tekrarlayan veri olduğu için sql server indexs’in hepsini tarayarak aradığı kaydı bulması sağlanır.
İndexs Seek: Sql server’ın indexs bulunan kolunu üzerinde direk aradığı kaydı bulmasıdır. Yukarıdaki indexs yapısından farkı tablonun tamamını taramadan aradığı kaydı bulmasıdır.
Yukarıdaki indexs seek ve scan yapısını örnek üzerinde açıklamak gerekirse. Tablomuzda 10 kaydın olduğunu bunlardan 8 kaydımız aynı değere sahiptir. 2 kayıt ise tamamen bir birinden farklıdır. Sql server burada aynı kayıttan 8 tane olduğunu istatistiklerden bakarak anlar. Herhangi bir sorgumuz geldiğinde sql server istatistiklere bakarak gelen sorgumuz 8 tane kayıt içerisinde değerlere bakarak indexs scan işlemi yapar. Eğer tekil olan kayıtlar üzerinde sorgumuz geldiğinde tekrardan sql server istatistiklere bakacak ve hangi kendisi için minumum maliyetli olan execution planını almış olacak.
Şimdi istatistiklere bakarak sql server’ın belirlediği diğer arama biçimlerini açıklayalım.
Clustered index seek: Tablomuzda primary key olarak tanımlanan kolundur. Eğer ilgili kolun üzerinde arama işlemi yaparsak ve belirtilen kolun üzerinde bir arama işlemi yaptığımızda sql server’ın direk aradığı sonucu bulmasıdır. Clustered index yapısı tablo üzerinde tutulmaktadır. Aslında tablonun kendisi de diyebiliriz. Bence burada yapı direk indexs üzerinde arama yaparsa bu yapıyı kullanmış olacaktır.
Clustered index scan: Tablomuzda non clustered indexs yok ve kullanıcı herhangi bir kolun üzerinde bir değeri aramak istediğinde sql server clustered indexs’in taranarak aradığı kaydın en minimize sürede olacağına karar verecek. Tablonun hepsini tarayarak aradığı kaydı bulmaya çalışmış olacaktır.
Not: Karmaşık sorgular kullanılarak yapılan sorgulama işlemlerinde sıklıkla koşul operatörü olan WHERE ifadesi kullanılır. Daha önceki açıklamalarımızın birçoğunda SQL Server’ın Indeks Seek işlemi yerine istenmeyen bir durum olan Indeks Scan işlemini tercih ettiğini ve bunun temel nedeninin kabaca sorgumuzdan çok fazla sayıda kayıt dönmesi olarak açıklamıştık. Bu nedenle çok fazla kayıt dönmesini Where operatörünü gerekli yerlerde sorgumuza ekleyerek önleyebiliriz.
İndex seek+Key lookup: Tablomuzda primary key ve koşulumuzda belirttiğimiz kolun üzerinde arama işlemi yaparsak sql server ilgili indexs’i bulacak non clustered indexsler clustered indexslerden ayrı bir yerde tutulduğu için non clustered üzerinde bulunan kayıt ile birlikte bulunan clustered id ile clustered indexs’e giderek aradığı kaydı bulmuş olacağız.
İndexs scan+Key lookup: Where koşulunda belirtilen şarta göre ilgili kolunda tarama işlemi yapacak ilgili değeri bulduktan sonra kolunun yanından bulunan clustered key değeri ile aradığı kaydı bulmaya çalışacaktır.
Yukarıdaki ifadeler sql server’ın istatikleri kullanarak ilgili değerleri görmüş olacağız. İlerleyen makalelerde daha detaylı bir şekilde işlemiş olacağız.
Herhangi bir sql server veritabanı üzerinde istatistikleri otomatik olarak yapabileceğimiz kavramlar görülmektedir.
Herhangi bir veritabanı üzerine sağ tıklayıp Properties> Options bölümünde bulunan bu kavramlara değinelim.

Aşağıdaki komut yardımıyla hangi veritabanları altında hangi değerleri aktif olduğu görebiliriz.
select name as DatabaseName, is_auto_create_stats_on,is_auto_update_stats_on,is_auto_create_stats_incremental_on,is_auto_update_stats_async_on from sys.databases
Auto Create Incremental Statistics: Bu yapı partition yapısında olan tablolarımız için partition bazında otomatik istatistik oluşturma bölümü olarak karşımıza çıkmaktadır. Incremental Statistics makalesinde bu başlığı detaylı bir şekilde öğrenebilirsiniz. Partition yapıları için makale sayfamızın arama kısmında bulabilirsiniz.
Hangi veritabanı altında partition yapısında tablomuz varsa bu özellik açılır. Herhangi bir sakıncası yoktur. partition yapısında olan tablomuzun bulunduğu veritabanı herhangi bir index jobına dahil edilirse partition tabloda sadece partition level seviyesinde index bakımı yapılmaktadır. Tüm tablo üzerinde yapılmaz. Olahallangren stored procedure incelenirse bu yapının default olduğu gözlemlenir.

Auto Create Statistics: Bu değerin aktif edilmesi sorgularımızda where koşulunda bulunan şart veya şartlar için istatistik oluşturması sağlanır. Otomatik istatistik oluşturma _WA olarak geçmektedir. Bu değerin true olarak işaretlenmesi gerekmektedir.

Manuel bir şekilde istatistik oluşturmak için aşağıdaki komut kullanılmaktadır. Yukarıda veritabanı üzerinde where koşuluna bağlı olarak istatistik otomatik olarak açılmazsa manuel bir şekilde ekleme işlemi yapılır.
CREATE STATISTICS Statistics_Name on AdventureWorks2014.[Person].[Person](Title);Eğer istatistiklerimiz otomatik olarak oluşmuyorsa execution planda aşağıdaki gibi bir ünlem işaretiyle karşılaşmaktayız. Bu ifade belirtilen kısımda istatistik sıkıntısı olduğunu göstermektedir.

Otomatik olarak oluşmamasının sebebi veritabanı üzerinde Auto Create Statistics değerinin false olmasıdır.
Auto Update Statistics: İstatistiklerimiz belirli bir eşik değerini geçtiğinde bu değer %20 olarak belirlenmiş durumda bu belirtilen değeri geçtikten sonra istatistiklerin otomatik olarak güncellemesi sağlanmaktadır. Genellikle sistemlerde true olması tavsiye edilmektedir. Herhangi bir istatistik güncelleme job’ımız yoksa bu değerin açık kalması hayati önem taşımaktadır. Çünkü tablomuza veri eklenmesi index ve istatistiklerin güncellenmeme durumunda performans anlamında çok ciddi sıkıntılar yaşayabiliriz. Şunu da belirtmek gerekir ki istatistikler güncellenirken gelen sorgu istatistiğin güncellemesini beklemez önceki istatistiği kullanmaktadır.
Not: Sql server bir tabloda %20 olarak bir değişiklikten sonra istatistikleri güncellenmesi gerekiyor. Bunu nasıl hesaplıyor sql server, kendi içerisinde güncelleme eşiğini kullanır. Tablodaki satır sayısına göre otomatik olarak ayarlanır.
Insert, update, delete gibi DML işlemlerini düzenli olarak gerçekleştiriyoruz ve bu tür işlemler veri dağılımını veya histogram değerini değiştiriyor. Bu işlemler nedeniyle istatistikler güncel olmayabilir ve
query optimizer verimliliğiyle ilgili sorunlara neden olabilir.
Bu istatistikleri Auto Update Statistics Otomatik Güncelleştirme seçeneğiyle query optimizer , istatistikler güncel olmadığında SQL Server istatistiklerini güncelleştirir. Sql server aşağıda belirtilen eşik değerini kullanmaktadır.
Eşik = √((1000)*Mevcut tablodaki satır sayısı)
Örneğin 100 bin satırlık bir tabloda kaçıncı değişiklikten sonra sql server otomatik olarak istatistikleri günceller.
Eşik = √((1000)*100000)=10000
10 bin satır değişikliğinden sonra sql server 100 bin satırlık tabloda güncelleştirme işlemi yapar.
Not: Bu hesaplamayı kullanabilmesi için compatibility level seviyesinin 130 ve üzerinde olması gerekmektedir.
Not: İstatistikler güncellendikten sonra Always On yapısında istatistikler ikinci sunucuda da güncellenmektedir.
Auto Update Statistics Asynchronously: Bu yapı istatistiklerin güncellenirken sisteme herhangi bir yük getirmemesi için istatistiklerin asenkron bir şekilde güncellenmesidir. Yani yukarıda belirttiğim gibi sorguyu bekletmemesi için kullanılan bir özellik olarak karşımıza çıkmaktadır. Sorgu çalışmaktadır statistics arka planda güncellenir.
SQL Server güncel olmayan istatistikleri algıladığında önce istatistikleri güncelleyecek, yeni bir yürütme planı oluşturacak ve ardından sorguyu yürütecektir. Bazı durumlarda, sorgunuzun yeni istatistiklerin oluşturulmasını beklemesini istemezsiniz çünkü istatistiklerin oluşturulması ve sorgunun yeni planla yürütülmesi için gereken süre, eski sorgu planıyla çalıştırılmasından daha uzun sürer. Bu davranışı önlemek için, veritabanınız da aşağıdaki komutu çalıştırarak “Auto Update Statistics Asynchronously” veritabanı seçeneğini ayarlayabilirsiniz.
ALTER DATABASE AdventureWorks SET AUTO_UPDATE_STATISTICS_ASYNC ONNot: Sql serverda istatistikleri daha hızlı bir şekilde güncellemek için 2371 trace flag parametresinin eklenmesi gerekmektedir.
Not: 2371 compatibility level 120 ve aşağıda olan yapılardan kullanılmaktadır. 130 ve üzerinde yapılarda yapılmasına gerek yoktur.
İlgili trace flag 1.000.000 satıra sahip bir tablonun artık istatistiklerin eski kabul edilmesi için yalnızca 32.000 değişikliğe ihtiyaç duyacağını gösterir. Trace Flag olmadan aynı tablonun istatistiklerin güncelliğini yitirmesi için 200.500 değişikliğe ihtiyaç duyması gerekir. Yukarıdaki kısımda belirttiğim eşik değeri ile aynı sonucu vermektedir.
Bu bayrak, SQL Server hizmetlerini yeniden başlatmadan açılıp kapatılabilir:
Bu değişiklik, bir üretim sisteminde uygulanmadan önce bir geliştirme ortamında test edilmelidir. Tekrardan söylemek gerekirse compatibility level 120 ve aşağıda olan yapılardan kullanılmaktadır.
DBCC TRACEON (2371,-1)
DBCC TRACEOFF (2371,-1)SQL Server Configuration Manager bölümünde 2371’i bir başlangıç parametresi olarak eklemesi gerekmektedir. Bu Trace Flag sql server servisi restart yapıldıktan sonra aktif olmaktadır.
Bu makalede Sql Server Statistics hakkında detaylı bilgilere değinmiş olduk. Başka bir makalede görüşmek dileğiyle..
Kim bir iyilikle gelirse, kendisine bunun on katı vardır, kim bir kötülükle gelirse, onun mislinden başkasıyla cezalandırılmaz ve onlar haksızlığa uğratılmazlar. En’am Suresi, 160. Ayet