
SQL Server’da Execution Plan’a müdahale ederken kullanılan faydalı kullanımlardan biri de Fast N seçeneğidir. Sıkça karıştırılan bu operatörü kullanarak, SQL Server’ın sorgu sonucunda gösterilecek olan sonuç kümesinin içinde N (N pozitif bir sayı) tane kaydı en hızlı getirecek şekilde Execution Planı optimize etmesini sağlayabiliriz. Fakat dikkat edilmesi gereken nokta burada verilen N pozitif bir sayı olmakla beraber gösterilecek kayıt sayısı ile alakalı değildir. Şöyle ki sorgumuzun sonucunda 1000 tane kayıt döndüğü durumda bu 1000 kaydın ilk 10 tanesinin olabilecek en hızlı bir şekilde ekrana getirilmesi ve kalan 990 tanesinin de ilk 10 tane hızlı bir şekilde gösterildikten sonra normal bir şekilde ekranda gösterilmesi isteniyorsa SQL Server’da bulunan Fast N seçeneği kullanılarak bu işlem çok daha performanslı bir şekilde gerçekleştirilebilmektedir. Ancak bu operatör çoğu zaman kayıt kümesinin N tane kayıt ile sınırlandırılacağı olarak düşünülmektedir. Bu yanılgıya düşülmemeli ve buna göre sorgular yazılmalıdır.
SQL Server genellikle büyük veri setleri için Hash Join kullanmayı sever çünkü toplu işlemde daha verimlidir. Ancak FAST N kullandığınızda, optimizer genellikle Nested Loops Join‘e döner.
- Neden? Nested Loops, ilk eşleşen satırı bulur bulmaz sonuç üretebilir. Hash Join ise önce bir “Hash Table” kurmak zorundadır (bu da beklemek demektir).
FAST N her zaman “daha hızlı” demek değildir. Yanlış kullanımda performansı kötüleştirebilir:
- Toplam Süre Uzayabilir: İlk 10 satırı çok hızlı alırsınız ama 11. satırdan sonrasını okumaya devam ederseniz, toplam sorgu süresinin normalden çok daha uzun sürdüğünü görebilirsiniz.
- Yanlış İndeks Seçimi: Optimizer, ilk birkaç satırı bulmak için “non-optimal” bir indeksi taramaya (Scan) karar verebilir.
- Bellek Yönetimi:
FAST Nile optimizer daha az bellek (Memory Grant) talep edebilir. Eğer verinin devamı beklenenden büyükse “spill to tempdb” (diske yazma) sorunu oluşabilir.
Şimdi Fast N operatörünün nasıl kullanıldığını bir örnek üzerinde görelim. İlk sorgumuzda Fast N operatörünü kullanmadan Execution Planımızı inceleyelim daha sonra aynı sorgumuzu Fast N operatörünü kullanarak SQL Server’ın kullanacağı Execution Planı inceleyelim ve karşılaştıralım.
SELECT *
FROM Sales.SalesOrderHeader oh
JOIN Sales.Customer c ON oh.CustomerID = c.CustomerID
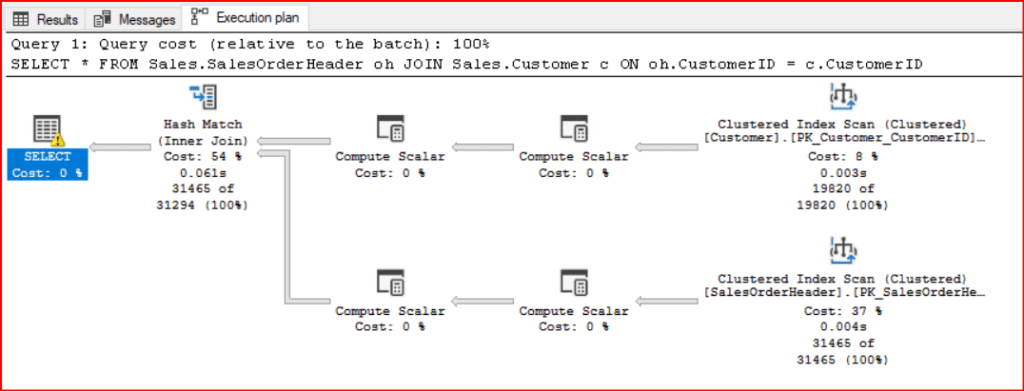
Hash Match Join seçilmesinin sebebi sıralı olmayan iki büyük veri kümesinin birleştirilmesidir. Şimdi sorgumuza Fast 10 değerini ekleyerek SQL Server’a ilk 10 kaydın en hızlı geleceği şekilde sorgumuzun Execution Planını optimize ettirelim ve çıkan Execution Planı inceleyelim
SELECT *
FROM Sales.SalesOrderHeader oh
JOIN Sales.Customer c ON oh.CustomerID = c.CustomerID option(fast 10)
Yukarıdaki sorgunun execution plan yapısının ekran resmini aldığımızda iki execution planımızın sonucunu karşılaştırabiliriz.

Yukarıdaki Customer tablosunda Clustered Index scan işleminin Clustered Index Seek operatörüne dönüştüğü fast ifademizde 10 kaydın çağrıldığını görmüş oluyoruz. Elde edilen sonuçlar ile Nested Loop Join operatörü ile birleştirilmiştir.
Eğer fast işleminden sonra 10 değeri yerine 10000 kullansaydık sorgumuz tekrardan Clustered Index Scan işlemi yapmış olacaktı.

Not: Fast N operatörü özellikle bazı durumlarda sorgu performansını beklenenden fazla artırıyor. Örneğin sorgularımızda top kullandığımızda gelen sonuç kümesinin sıralı olması önemli değilse ve bu sebeple order by operatörünü kullanmıyorsak Fast N operatörü performans açısından yararlı olacaktır.
Bir başka örnek:


Bu makalede execution yapılarında görülen FAST N Query Hint Kavramıyla Müdahale edilmesi ifadesine değinmiş olduk. Başka bir makalede görüşmek dileğiyle..
“Şüphesiz, Rabbin sana verecek ve sen de hoşnut olacaksın.”. Duha Süresi-5 Ayet