
SQL Server üzerinde geliştirme yaparken kullandığımız Max, Min, Sum, Avg, Count gibi gruplama fonksiyonları Execution Planlarımıza Stream Aggregate veya Hash Match Aggregate olarak yansıyacaktır. Stream Aggregate yönteminde kullanılan veri kümesi sıralı olmak zorundadır. Bu sebeple gruplama işlemleri için SQL Server tarafından Stream Aggregate operatörü seçilmiş ise ya üzerinde işlem yaptığımız veri kümesi sıralıdır ya da işlem yapılacak veri kümesi Stream Aggregate operatöründen önce sıralanmalıdır. Stream Aggregate operatörü kendisine gelen veri kümesindeki verileri tek tek okuyarak aynı olan değerleri kendi içinde oluşturduğu gruba dâhil ederken farklı bir değerin okunmasıyla beraber yeni bir grup oluşturulur. Stream Aggregate operatörü SQL Server üzerinde gruplama işlemi yaparken kullanılabilecek en hızlı operatördür. Bu sebeple sıralanmış veri kümesi üzerinden işlem yapıyorsak diğer bir değişle uygun indeksin olduğu bir tablodan bu indeks vasıtasıyla veriyi okuyorsak SQL Server Stream Aggregate operatörünü tercih edecektir.
Stream Aggregate operatörünün tercih edileceği bir başka durum ise gruplanacak veri kümesi sıralanmamış olsa bile bu veri kümesini sıralama işleminin maliyeti çok yüksek değilse muhtemelen SQL Server öncelikle veri kümesinin Sort operatörü yardımıyla sıralayacak daha sonra ise gruplama işlemi için Stream Aggregate operatörünü kullanacaktır. Şimdi Stream Aggregate operatörünü bir örnek üzerinde görelim.
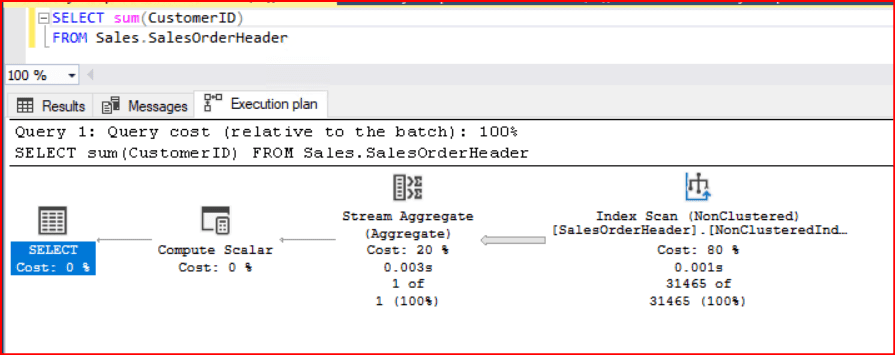
Yukarıdaki ifadede CustomerID kolununun üzerinde Nonclustered Index Scan olduğu için ve elimizdeki veri kümesi sıralı olduğu için SQL Server tarafından gruplama işlemi için Stream Aggregate operatörü tercih edilmiştir

Stream Aggregate operatörünü üzerinde geldiğimizde yukarıdaki açılan Tooltip penceresini incelediğimizde en alt kısımda Grup By bölümünde gruplama işleminin CustomerID kolonuna göre yapıldığını görebiliriz. Ayrıca bir diğer bölüm olan Output List kısmında ise Stream Aggregate operatörünün çıktısında yer alacak olan kolonların listesini görebiliriz. Bu listeden gruplama işlemini yaptığımız CustomerID kolonu ile beraber Expr1005 adında sonradan eklenmiş ve sorgumuzda kullandığımız gruplama fonksiyonu olan Count fonksiyonun çıktısını temsil eden geçici kolon bulunmaktadır.
Stream Aggregate operatörünün çıktısını incelediğimizde aslında bizim ekranda gördüğümüz çıktı ile aynıdır. Fakat Execution Planımızı incelediğimizde Stream Aggregate operatöründen sonra Compute Scalar operatörünün kullanıldığını görebiliriz. Bu operatörün kullanılmasının sebebi ise sorgumuzda kullandığımız Count fonksiyonun çıktısı integer iken Stream Aggregate operatörü sayma işlemini Count fonksiyonunu ile değil varsayılan olarak Count_Big fonksiyonu ile yapmaktadır. Bu sebeple Count fonksiyonunu kullandığımızda Stream Aggregate operatörümüz çıktı olan big integer tipinde sonuç dönecektir. Bu sebeple buradaki Compute Scalar operatörünün asli görevi Stream Aggregate operatörünün çıktısından dönen big integer olan değeri count fonksiyonun çıktısı olan integer’a dönüştürmektir. Bu durumu açıkça görmek için Execution Planımızdaki Compute Scalar operatörünün özellikleri aşağıdaki gibi görüntüleyelim.

Yukarıdaki resimde gördüğümüz gibi Compute Scalar operatörünün yaptığı iş Stream Aggregate operatörünün çıktısı olan Expr1005 değerini integer veri tipine dönüştürmektir. Yapılan bu dönüşüm işlemini engellemek için sorgularımızda count yerine cout_big fonksiyonunu kullanabiliriz.
Şimdi aynı sorgumuzu count_big fonksiyonunu kullanarak yazalım ve Execution Planımızı inceleyelim. Sorgumuz ve Execution planımız aşağıdaki gibi olacaktır.

Yukarıdaki resimde gösterilen Execution planımızı inceldiğimizde Compute Scalar işleminin yapılmadığını görebiliriz. Bunun sebebi ise sorgumuzda count_big fonksiyonunu kullanarak SQL Server’a çıktı olarak zaten big integer istediğimizi söylemiş olduk ve SQL Server da bu sebeple veri tipi dönüşümü yapmak için Compute Scalar operatörünü kullanmayarak işlemi gerçekleştirmiş oldu.
Stream Aggregate operatörünün sıralı veri kümesi üzerinde kullanıldığını söylemiştik. Bu sıralama işleminden kastımız üzerinde işlem yapılan veri kümesinin gruplama yapılan kolona göre sıralanmış olmasıdır. Çünkü Stream Aggregate operatörü bu sıralamayı gruplama yaparken kullanacaktır. Bu sebeple gruplama işlemi yapılmadan sadece sum, avg gibi gruplama fonksiyonu kullanarak yaptığımız işlemlerde SQL Server Stream Aggregate operatörünü tercih edecektir. Çünkü gruplama yapmadığımız için tüm veriler tek grup olarak değerlendirilecek ve veri kümesi sıralı olarak ele alınacaktır.
Yukarıdaki resimde gördüğümüz gibi Stream Aggregate operatörü için kullanılan veri kümesi Clustered Index Scan işlemi sonucunda elde edilmiştir. Fakat biz CustomerID kolonu üzerinde toplama işlemi yaptık. Fakat herhangi bir kolona göre gruplama yapmadığımız için veri kümesi zaten sıralı olarak kabul edilmekte ve bu sebeple Stream Aggregate operatörü tercih edilmektedir.
Avantajları Nelerdir?
- Bellek Dostudur: Hash Aggregate gibi tüm veriyi hafızaya (RAM) yüklemez. Sadece o anki grubun toplamını tutar. Bu yüzden çok az bellek harcar.
- Hızlıdır: Veri zaten sıralıysa (bir Index sayesinde), işlem çok az maliyetle tamamlanır.
- Düşük CPU Kullanımı: Karmaşık matematiksel hesaplamalar (hashing) gerektirmediği için CPU’yu yormaz.
Dezavantajları Nelerdir?
- Sıralama Bağımlılığı: Veri sıralı değilse, SQL Server bu operatörü kullanabilmek için önce bir Sort (Sıralama) operatörü eklemek zorunda kalır. Sıralama işlemi ise disk ve bellek üzerinde çok maliyetlidir.
- Sadece Gruplama Odaklıdır: Veri seti çok büyükse ve uygun bir index yoksa, SQL Server genellikle Hash Aggregate’i tercih eder çünkü devasa veriyi baştan sona sıralamak daha zordur.
Execution Plan’da bir Stream Aggregate gördüğünüzde şu iki durumu değerlendirmelisiniz:
- Öncesinde “Sort” Operatörü Varsa: Eğer planda Stream Aggregate’den hemen önce bir Sort işlemi görüyorsanız, bu bir “uyarı” işaretidir. Bu, SQL Server’ın “Veri sıralı değil ama ben Stream Aggregate kullanmak istiyorum, o yüzden önce bir zahmet sıralıyorum” dediği anlamına gelir.
- Çözüm: GROUP BY yaptığınız kolonları içeren bir Non-Clustered Index oluşturun. Böylece Sort operatörü ortadan kalkar ve sorgu hızlanır. Sort Operatörü Yoksa İdeal durumdur.
Eğer doğrudan Index Scan veya Index Seek sonrası Stream Aggregate geliyorsa, SQL Server mevcut bir index’i verimli kullanıyor demektir. Bu durumda genellikle bir şey yapmanıza gerek kalmaz; bu en verimli gruplama yöntemlerinden biridir.
Bu makalede execution yapılarında görülen Stream Aggregate ifadesine değinmiş olduk. Başka bir makalede görüşmek dileğiyle..
Onlar, siz birbirinizi namaza çağırdığınızda onu alay ve oyun (konusu) edinirler. Bu, gerçekten onların akıl erdirmeyen bir topluluk olmalarındandır. Maide Suresi, 58. Ayet