

Bu makalede MSSQL Server Execution Plan Repartition Streams Operatörünü detaylı bir şekilde görmüş olacağız. Paralelizmin kullanıldığı Execution planlarda sık kullanılan bir diğer operatör de Repartition Streams operatörüdür. Bu operatör diğer operatörlerden farklı olarak veri kümesini birden fazla parçaya bölerek işlem yaparken yine çıktısını birden fazla veri kümesi olarak verebilmektedir. Dikkat ederseniz Repartition Streams operatörü işlev olarak özellikle Distribute Streams operatörüne çok benzemektedir. Fakat aralarındaki fark Repartition Streams operatörü çıktısını gerekirse sıralayabilirken, Distribute Streams operatörü ise işlem yaparken verinin geldiği sırayı değiştirmeden korumaktadır. Bu sebeple sorgularımızda eklediğimiz sıralama operatörü bu iki operatörden hangisinin kullanılabileceğini de etkileyecektir.
Paralel bir sorgu çalışırken, SQL Server veriyi “paketler” halinde işler. Ancak bazen bir sonraki işlem için verilerin belirli bir kurala göre (örneğin CustomerID’ye göre) gruplanması gerekir.
- Veri Dağıtımı: Birden fazla giriş stream’ini (akışını) alır ve bunları birden fazla çıkış stream’ine yönlendirir.
- Yük Dengeleme: İş yükünü thread’ler arasında eşit dağıtarak bir thread’in çok yorulup diğerinin boş kalmasını (skewness) engellemeye çalışır.
Bu operatör genellikle şu durumlarda ortaya çıkar:
- Parallel Join: İki tabloyu birleştirirken, birleştirme kolonuna (Join Key) göre verilerin aynı thread’e düşmesi gerekir. SQL Server veriyi “hash” ederek ilgili satırları eşleşecekleri thread’e gönderir.
- Parallel Aggregation: GROUP BY işlemi yaparken, aynı gruba ait verilerin aynı thread tarafından hesaplanması için yeniden dağıtım yapılır.
- DOP Değişikliği: Sorgunun bir bölümü 8 thread ile çalışırken, bir sonraki bölümü 4 thread ile çalışacaksa (Degree of Parallelism değişimi), akışın yeniden düzenlenmesi gerekir.
Buraya kadar Execution planda sık kullanılan paralelizm operatörlerine değindik. Şimdi bu operatörleri kullanacak bir sorgu yazıp Execution planımızı inceleyelim.
SELECT *
FROM Sales.SalesOrderDetail sod
RIGHT JOIN Production.Product p
ON sod.ProductID = p.ProductID
ORDER BY p.ProductID DESC Yukarıdaki sorgumuzun Execution planı aşağıdaki gibi olacaktır.
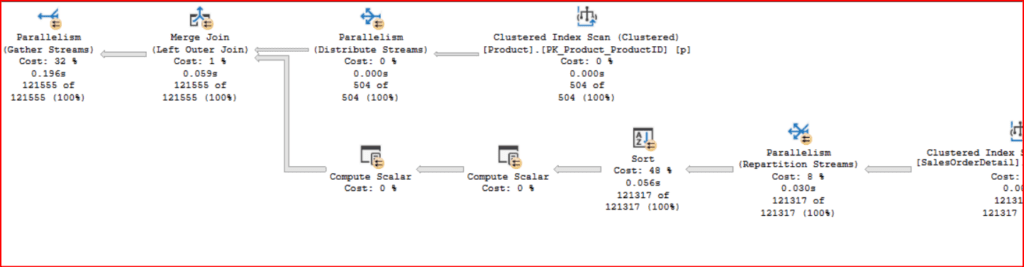
Sorgumuzun Execution planını incelediğimizde Query Optimizer’ın paralel bir Execution planı tercih ettiğini görebiliriz. Execution planımızın detaylarını incelediğimizde öncelikle Product tablosundaki kayıtlar okunmuş ve bunların işlenmesi için Distribute Streams operatörü kullanılmıştır. Bildiğiniz gibi Distribute Streams operatörü üzerinde işlem yaptığı veri kümesini birden fazla Thread ile okuyup işlem yapabilmektedir. Sorgumuzda Distribute Streams tarafından kullanılan veri kümesi Production. Product tablosunu temsil etmektedir. Burada Production.Product tablosunun çok büyük olmadığını ve Paralelizme ihtiyaç duymayacağını düşünebilirsiniz. Fakat bir sorgu da paralelizm kullanılıp kullanılmayacağına herhangi bir operatörün değil tüm sorgunun maliyetine bakılarak karar verilir. Bir sonraki kısımda ise Sales.SalesOrderDetail tablomuzdan kayıtlar Clustered Index Scan işlemi ile okunmuştur. Bu defa kayıtlar Repartition Streams operatörü kullanılarak okunmuştur. Bunun sebebi ise Sales.SalesOrderDetail tablosunun boyutunun büyük olması ve okunan veri kümelerinin paralel bir şekilde okunup aynı şekilde paralel olarak Sort yani sıralama işleminin de paralel yapılmasıdır. Sort işlemi de aynı şekilde Execution planımızda tercih edilen Merge Join işleminin yapılması için zorunludur. Fakat sorgumuzda dikkat ederseniz sıralama işlemini Production.Product tablosundaki ProductId kolonuna göre yapmamıza rağmen burada Sort operatörü kullanılmadı. Sebebi sizin de tahmin edeceğiniz üzere zaten Clustered Index Scan işlemi ile okunan kayıtların ProductId kolonuna göre sıralı olmasıdır.
Execution planımızın alt kısmında bulunan iki tane Compute Scalar operatöründen bir tanesi tablomuzda bulunan Computed Column değeri için kullanılırken diğeri ise veri tipi dönüşümü için kullanılmaktadır. Execution planımızdaki bir diğer operatör olan Merge Join ise iki tablomuzda bulunan kayıtların birleştirilmesi için kullanılmıştır. Daha sonra çıktısı paralel olan Merge Join işleminin sonucunda Gather Streams operatörü kullanılarak sorgumuzun nihai sonucu elde edilmiştir.
Sorgumuzun Execution planını incelediğimizde paralelizm kullandığını görmüş olduk. Paralelizm için SQL Server’ın birden fazla Thread kullanabileceğini söylemiştik. SQL Server’ın operatörlerdeki işlemi kaç Thread ile kaçarlı veri kümelerine böldüğünü operatörlerimizin özelliklerinden görebiliriz. Örneğin Production.Product tablosundan paralel bir şekilde veri okumak için kullanılan Distribute Streams operatörüne sağ tıklayarak Properties penceresini açalım ve bu operatörün özelliklerini inceleyelim.

Yukarıdaki resimde gördüğümüz gibi Distribute Streams operatörünün özelliklerinde görüleceği üzere Actual Number of Batches kaç tane Thread kullanıldığını yani diğer bir ifadeyle bu işlemin kaç parçaya bölünerek yapıldığını gösterirken, Actual Number of Rows kısmını incelediğimizde her bir Thread tarafından toplam okunan kayıt sayısını görebiliriz. Dikkat ederseniz her Thread hemen hemen eşit sayıda kayıt okuması yapmıştır. Bunun sebebi ise her Thread ‘in işini aynı zamanda bitirebilmesidir. Son olarak Actual Number of Rows değerindeki Thread 0 olarak görünen kısmında hiç kayıt olmamasının sebebi bu işlemin diğer işlemleri yönetmesidir.
Yukarıdakine benzer olarak sorgumuzdaki diğer paralelizm operatörü olan Repartition Streams operatörünün de Properties penceresini aşağıdaki gibi inceleyebiliriz.

Yukarıdaki resimde gördüğümüz gibi bu defa Sales.SalesOrderDetail tablosundan yapılan okuma 4 parçaya bölünerek paralel yapılmıştır. Paralelizm operatörlerimizin özellikler penceresinden kaç tane Thread kullanıldığını ve kaçar kayıt okuduklarını görebiliyoruz. Ayrıca bu operatörlerin Properties penceresinin en alt kısımdaki özelliklerini incelediğimizde karşımıza aşağıdaki gibi bir kaç tane daha özellik gelecektir.

Yukarıdaki resimde gördüğümüz gibi operatörümüzün Physical Operation özelliğinde paralelizmin kullanıldığını görebiliyoruz. Ayrıca benzer olarak Paralel adında olan diğer özelliği ise True değerini taşımaktadır. Fakat bu özelliklerden ziyade Partition Columns özelliğini incelediğimizde bu kısım paralelizm için küçük parçalara bölünecek tablonun bilgileriyle bölümleme işleminin hangi kolondaki değere göre yapılacağı bilgisini tutmaktadır. Örneğin bizim operatörümüz için Sales.SalesOrderDetail tablosundaki ProductId kolonuna göre veri kümemiz bölümlere ayrılacaktır.
Gemini şunu dedi:
SQL Server’da bir sorgu planında Repartition Streams operatörünü görmek, SQL Server’ın paralel bir işlem yürüttüğünü ve veriyi worker thread’ler (iş parçacıkları) arasında yeniden dağıttığını gösterir.
Basitçe ifade etmek gerekirse; veriler bir aşamadan (örneğin bir Index Scan) belirli sayıda thread ile gelirken, bir sonraki aşamaya (örneğin bir Join veya Aggregate) farklı bir dağılımla aktarılıyorsa bu operatör devreye girer.
Bu Operatör Ne Yapar?
Paralel bir sorgu çalışırken, SQL Server veriyi “paketler” halinde işler. Ancak bazen bir sonraki işlem için verilerin belirli bir kurala göre (örneğin CustomerID’ye göre) gruplanması gerekir.
- Veri Dağıtımı: Birden fazla giriş stream’ini (akışını) alır ve bunları birden fazla çıkış stream’ine yönlendirir.
- Yük Dengeleme: İş yükünü thread’ler arasında eşit dağıtarak bir thread’in çok yorulup diğerinin boş kalmasını (skewness) engellemeye çalışır.
Neden Görürsünüz? (Yaygın Senaryolar)
Bu operatör genellikle şu durumlarda ortaya çıkar:
- Parallel Join: İki tabloyu birleştirirken, birleştirme kolonuna (Join Key) göre verilerin aynı thread’e düşmesi gerekir. SQL Server veriyi “hash” ederek ilgili satırları eşleşecekleri thread’e gönderir.
- Parallel Aggregation:
GROUP BYişlemi yaparken, aynı gruba ait verilerin aynı thread tarafından hesaplanması için yeniden dağıtım yapılır. - DOP Değişikliği: Sorgunun bir bölümü 8 thread ile çalışırken, bir sonraki bölümü 4 thread ile çalışacaksa (Degree of Parallelism değişimi), akışın yeniden düzenlenmesi gerekir.
Performans Açısından Dikkat Edilmesi Gerekenler
Repartition Streams genellikle faydalıdır, ancak “pahalı” olabilir. Eğer bu operatörde bir darboğaz varsa şunları kontrol etmelisiniz:
- Skewness (Veri Çarpıklığı): Eğer bir thread 1 milyon satır işlerken diğeri 10 satır işliyorsa, bu operatör verimli çalışmıyor demektir. Bu genellikle istatistiklerin güncel olmamasından kaynaklanır.
- Yüksek CPU Maliyeti: Veriyi bölmek ve paketlemek CPU tüketir. Eğer veri seti çok küçükse, paralellik için harcanan efor (overhead), sorgunun seri çalışmasından daha uzun sürebilir.
- CXPACKET Beklemesi: Eğer yürütme planında bu operatör yoğunsa, CXPACKET bekleme türlerini sisteminizde sıkça görebilirsiniz.
Bu makalede execution yapılarında görülen Repartition Streams ifadesine değinmiş olduk. Başka bir makalede görüşmek dileğiyle..
“Lokmân oğluna öğüt verirken ona şöyle dedi: “Sevgili oğlum! Allah’a ortak koşma; çünkü O’na ortak koşmak kesinlikle çok büyük bir haksızlıktır.””Lokman-13