
Bu makalede Execution Plan yapılarımızda çokça karşılaşacağımız Key Lookup operatörünün ne işe yaradığına değinelim.
MSSQL Server’da Key Lookup, veritabanı motorunun bir sorguyu yanıtlarken ihtiyaç duyduğu tüm verileri seçtiği yardımcı indekste (Non-Clustered Index) bulamaması ve eksik kalan sütunları ana tablodan (Clustered Index) çekmek zorunda kalması durumudur.
Aşağıdaki ekran resminde bir önceki makalemizde dönen sonuç üzerinde işlemlerimize devam edelim;
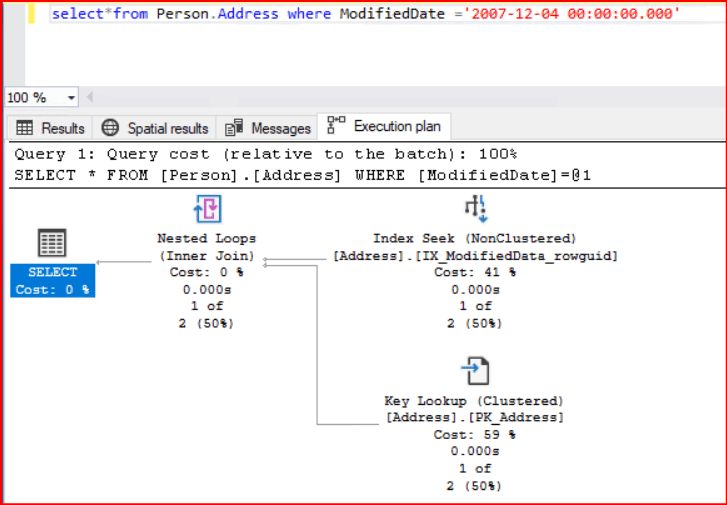
Yukarıdaki sorgumuzun Execution planına baktığımızda önceden görmüş olduğumuz Execution Plan yapılarına göre biraz daha karışmış gibi görünüyor. Daha önce herhangi bir Execution planı yorumlarken sağdan sola doğru gidilmesinin işimizi kolaylaştıracağını söylemiştik. Eğer Execution planımız yukarıdaki gibi sadece sağdan sola değil yukarıdan aşağıya da uzuyorsa yorumlama sırası öncelikle yukarıdan aşağı daha sonra sağdan sola şeklinde yapılmalıdır. Bu kurala uyduğumuzda ilk yorumlamamız gereken işlem önceki konuda değinmiş olduğumuz Nonclustered Indek Seek operatörü olup bu işlem hakkında gerekli bilgiyi önceki bölümde verdik. Fakat tüm planı daha anlamlı yorumlayabilmek için Nonclustered Indek Seek operatörünün üzerine gelip açılan Tooltip penceresinden kullanılan indeksimize bakalım.

Yukarıdaki Index Seek operatörün tooltip penceresine baktığımızda IX_ModifiedData_rowguid Nonclustered Indek yapısının kullanıldığını göstermektedir. Burada ModifiedData değerini yukarıdaki index yapısının içerisinde bulunduğu için index seek yaptığını görmekteyiz. Output List içerisinde bulunan yapıda sorgumuzda kullanıcının ModifiedDate kolununu kullanarak filtreleme yaptığı kullandığı ilgili index üzerinde AddressID clustered key değerini kullanarak gerçek tablomuza key lookup işlemi yapar, kısacası belirtilen tarihteki değerlerin yanındaki tarih kolonu yanında Clustered Key değeri ile gerçek tablodan diğer değerleri okuyacak ve birleştirme işlemi yapmış olacaktır.

Key Lookup işleminde iki ayrı okuma işlemi yapılır. İlk olarak Nonclustered Index ile Clustering Key elde edilir. Ardından bu key kullanılarak Clustered Index üzerinden istenilen diğer değerler getirilir.
Yukarıdaki Key Lookup Tooltip penceresini inceleyelim. Object kısmında PK_Address index yapısını kullanarak Output List kısmında gelen sonuç kolonlarını getirdiğini görüyoruz. Daha sonra Output List kolonundan gelen değerleri kullanarak birleştirme işlemi yapıp sonuçları karşımıza getirmektedir.
Key Lookup işlemi bizim işimizi görmüş olsa bile yukarıda açıkladığımız gibi fazladan işlem yapılmasına neden olmakta ve planda gördüğümüz gibi işlem eforunun büyük kısmı Key Lookup için harcanmaktadır. Hâlbuki Key Lookup işlemi ile eriştiğimiz diğer kolun değerleri indeks tanımına eklenmiş olsaydı Key Lookup işlemine gerek kalmayacaktı ve sorgumuz daha hızlı çalışacaktı. Fakat böyle bir işlem için hemen hemen tablodaki tüm alan kombinasyonlarına göre indeks oluşturmak gerekir ki fazla ve gereksiz indeks oluşturmanın çoğu zaman performansı olumsuz etkileyeceğine indeks konusunda değinmiştik. Ayrıca Key Lookup işlemlerini azaltmak ve onları Nonclustered Indeks Seek işlemine dönüştürmek bize performans sağlayacaktır. Bunun için indeksler konusunda bahsetmiş olduğumuz cover indeksler (Include option) incelenerek kullanılabilir.
Tekrar neden kullanıldığını açıklamak gerekir ise; ilgili sorguya uyan index kullanıldığında ve bu index sorguda istenilen sütunları barındırmıyor ise Key Lookup işlemi gerçekleştirir. Key Lookup şöyle bir yardımda bulunur, index seek sonucu bulunan kayıtların Primary Key’leri sayesinde tabloda o kayıtlara ulaşıp istenilen sütunların datalarını getirmektedir. Execution plana bakıldığında maliyetin büyük bir çoğunluğu bu aşamada harcanmakta olacaktır.
Bu maliyetten kurtulmanın yolu ise kullanılan index’imizde doğru sütunları include etmektir.

Execution planımızda bulunan bir diğer yabancı operatör olan Nested Loops operatörü ise performans açısından sorgumuzu etkilemeyen sadece iki operatörü birleştirmek için kullanılan yardımcı bir operatördür. Bizim işlemimizde Key Lookup ve Nonclustered Index Seek operatörlerini birleştirmek için kullanılmıştır. Eğer Key Lookup işlemi cover indeks işlemi ile ortadan kaldırılırsa Nested Loops operatörü de ortadan kalkacaktır.

Aslında Index yapımıza inclued kolunlar ekleyerek tablomuzla aynı boyutta bir tablo daha oluşturuyoruz. Genellikle istenmeyen bir durum olarak karşımıza çıkmaktadır.
Kısaca Key Lookup, where koşulunda vermiş olduğumuz kolon için bir NonClustered index mevcutsa ve Select ifadesiyle çağırdığımız diğer kolonlar için herhangi bir index yoksa (include edilmemişse) Clustered Index kullanıp onun üzerinden verileri getirmesidir.
Çözüm olarak ise, sorgu çok sık kullanılıyorsa Key Lookup yaptığı kolonu belirleyip NonClustered indexte include edebilirsiniz.
Son olarak şunları değinmek gerekirse koşulda belirtilen kolon yanına diğer kolonların included olarak eklenmesi index seek yapılmasına sebep verecektir. Included kolon olarak değil de composite index yapısında oluşturulduğunda aşağıdaki execution plan yapısı görülmektedir. Tablomuz yine key lookup işlemi yapmaktadır.


Yukarıdaki resimde ilgili kolonlar belirtilerek çağrıldığında key lookup işlemi yapılmamaktadır.

Şunu da belirtmek gerekirki composite index yapsıyla oluşturulmuş bir index yapısının çağrılan kolon eğer index yapısında ilk kolonda değilse sql server kullanıp kullanmayacağını kendi karar verir demiştik. İlgili index yapısı ve hangi execution plan görüldüğünü aşağıdaki resimlerde var.

Dikkat ederseniz tüm kolonları çağırmamıza rağmen sql server primary key üzerinden clustered index scan yapmayıp ilgili indexsi kullanmanın daha az maliyetli olduğuna karar verdi. Sql serverın önerdiği index yapısında ilgili tarih kolonunan göre index atılması gerektiğini belirtiyor.

Sadece belirli kolonları çağırmak istersek oluşturduğumuz index yapısına göre lookup işlemine gerek duymadı. Index uzerinden arama işlemini gerçekleştirmiş oldu.

Kısacası index oluşturma şeklimiz kolonun sırası tamamen execution plan oluşmasında temel faktördür.
Not: Key lookup işlemini gidermek için en yaygın ve etkili çözüm Covering Index (Kapsayan İndeks) oluşturmaktır. Yani, sorguda kullanılan eksik kolonları indekse INCLUDE yöntemiyle eklemektir.
Bu makalede Key Lookup operatörünü detaylı bir şekilde görmüş olduk. Başka bir makalede görüşmek dileğiyle..
“Şüphesiz, Rabbin sana verecek ve sen de hoşnut olacaksın.”. Duha Suresi-5 Ayet