
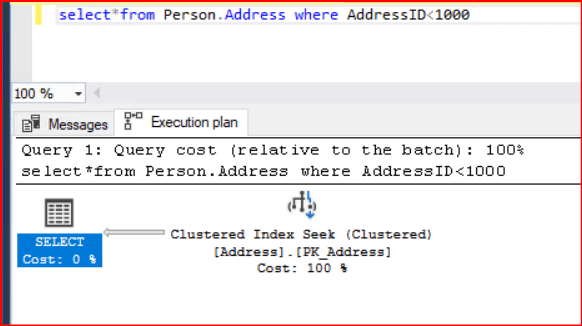
Bir önceki execution plan operatöründeki Clustered Index Scan işleminde sorgu sonucumuzda dönen sonuç kümesini azaltırsak performans anlamında bizlere daha iyi katkı sağlayacak bir operatöre dönüştürüleceğinden bahsetmiştik. Bu makalemizde belirtilen sorgumuzda index tanımlı kolun üzerinde şart ifadesini belirtirsek karşılaşacağımız Clustered Index Seek operatörünü görmüş olalım.
Clustered Index Seek operatörünün üzerine gelip Tooltip penceresinde yapının ne olduğunu görelim.

Yukarıdaki Execution planımıza baktığımızda bir önceki plandan farklı olarak Clustered Index Seek işleminin kullanıldığını görebiliyoruz. Index Seek ve Index Scan işlemleri birbirlerinden çok farklıdır. Index Scan işlemi yukarıda da belirttiğimiz gibi tablomuzdaki tüm verilerin baştan sona kadar satır satır okunmasıdır. Index Seek işlemi ise veriye erişirken Clustered veya Nonclustered olan bir indeksin belirlenip kullanıldığını ve böylece tüm tablodaki veriye erişmeden sadece istenen verilere eriştiğimizi göstermektedir. Bu yüzden indeks Seek işlemleri Indeks Scan işlemlerine göre daha performanslı çalışmaktadırlar.
Sorgumuzda filtreleme kullandığımız için index seek işlemini kullandığını görüyoruz. Parantez içerisinde dikkat edersek clustered yazdığını görmekteyiz. Buda primary key kolununda bulunan index’in kullanıldığını göstermektedir.
Yukarıda sorgumuzda implicit convertion yapısının görülmesinin sebebi SSMS arayüzünde kullandığımız 1000 değeri biz ne kadar int olarak görsek sql server arka tarafta ilgili değeri @1 değerine atamış bu değer büyük ihtimalle varchar olduğu için girilen değer siz ne kadar int olarak görseniz bile sql server bu değeri başka bir türe tahsis edip dönüştürme işlemi yapmaktadır. Neden tüm tablo kolonlarını dönüştürmeyip girilen değeri dönüştürme işlemi yapmış dersek burda sql server sadece 1 değerin dönüştürülmesini performans anlamında daha iyi olacağına inanmasından dolayıdır.
Estimated Row Size (4241 B): Bu değer aslında bir “alarm” zilidir. Bir satırın 4 KB olması çok büyüktür. SQL Server bu 999 satırı okurken aslında bellekte (RAM) yaklaşık 4 MB yer ayırıyor.
Tooltip içerisinde Ordered: True ifadesi geçiyor. Bu şu anlama gelir:
- Veriler zaten AddressID kolonuna göre fiziksel olarak sıralı olduğu için, SQL Server bu verileri çekerken ekstra bir Sort (Sıralama) işlemi yapma zahmetine girmeyecektir. Bu, özellikle ORDER BY kullanılan sorgularda büyük bir avantaj sağlar.
Tooltip’teki değerler şu şekilde yorumlanmalıdır:
- Actual Number of Rows Read: Bu, SQL Server’ın sonuç kümesini oluşturmak için “dokunduğu” satır sayısıdır. Eğer bir Table Scan yapıyorsan tablodaki her şeyi RAM’e çekmeye çalışır. Eğer Index Seek (senin ikinci görselin) yapıyorsan sadece ilgili 999 satırı RAM’e çeker.
- Neden
SELECT *Tehlikelidir? Görselde Estimated Row Size 4241 Byte görünüyor. Eğer sen sadece AddressID kolonunu seçseydin (sadece 4-8 byte), RAM’e alınan veri miktarı MB’lar seviyesinden KB’lar seviyesine düşecekti.
RAM’e Alınan Diğer Veriler Sadece satırlar değil, SQL Server o işlemi yaparken şunları da belleğe alır:
- Index Sayfaları: Aradığın veriyi bulmak için kullandığı index ağacının (B-Tree) ilgili sayfalarını RAM’e alır.
- Execution Plan: Sorgunun nasıl çalıştırılacağına dair planın kendisi de (senin şu an gördüğün şema) RAM’deki Plan Cache üzerinde tutulur.
Bu makalede Clustered Index Seek operatörünü görmüş olduk. Başka bir makalede görüşmek dileğiyle..
“Allah içinizden iman edenlerin ve kendilerine ilim verilenlerin derecelerini yükseltir.” Mücâdele – 11