
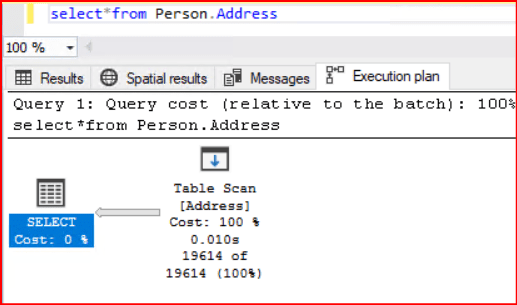
Bu makalede Execution Plan operatörlerin olan Clustered Index Scan operatörünü görmüş olacağız. İlk olarak sorgumuzun primary key tanımlanmadan dönen execution plan yapısı aşağıdaki ekran resminde görülmektedir. Table Scan makalesinde bu operatörün ne işe yaradığına değinmiştik. İlgili makaleyi sayfamızdan okuyabilirsiniz. Şimdi böyle bir yapıyla karşılaşınca ne gibi bir adım yaparız buna değinmiş olalım.
Öncelikle bir kolonun primary key olabilmesi için belirli koşulları sağlaması gerekmektedir. Tüm değerler benzersiz (unique) olmalıdır. Aynı kolonda tekrar eden değer varsa Primary Key yapılamaz.NULL değer olmamalıdır.PK kolonu NOT NULL olmak zorundadır.
Clustered Index oluşturmak için o kolonun mutlaka NOT NULL (boş olamaz) veya UNIQUE (benzersiz) olması şart değildir. SQL Server, verileri fiziksel olarak sıralayabilmek için her satırın “gerçekten” tekil bir adresine ihtiyaç duyar. Eğer sizin seçtiğiniz kolon benzersiz değilse, SQL Server her satıra gizli, 4 byte boyutunda bir “uniquifier” (tekilleştirici) ekler.
Bir kolon NULL değerler içerse bile Clustered Index oluşturabilirsiniz. SQL Server için NULL değerler de sıralanabilir birer veridir (genellikle sıralamada en başa veya en sona gelirler).
- Eğer bu kolonu aynı zamanda Primary Key yapmak isterseniz, işte o zaman SQL Server hata verir; çünkü Primary Key kural gereği asla NULL olamaz.
Bu açıklamalardan sonra Table Scan olan olan execution planımızı değiştirelim.
Yukarıdaki tablomuzun ilk kolununa clustered indexs(primary key) tanımladıktan sonra sorgumuzun Execution Plan yapısını gözlemleyelim. Tablomuzun altında Index bölümünde Clustered Index yapımızı oluşturuyoruz.

Tablomuzun tekil olan ilk kolonuna aşağıdaki ekran resminde görüldüğü gibi bir Clustered Index tanımlayalım.

Index yapımızı oluşturduktan sonra tekrardan yukarıdaki sorgumuzu çalıştırıp Execution Plan yapımıza bakalım. Aşağıdaki resimde dikkat edersek ilgili kolon benzersiz, not null olmayan tekil değerler olduğu için index yapısı PK ismi ile başlayan yapıda oluşturulmuş oldu.

Daha sonra Clustered Index Scan operatörünün üzerine gelip ilgili tooltip yapısını inceliyelim.

Yukarıda tooltip yapısını incelediğimizde Object kısmında PK_Address indexs yapısını kullandığını görmüş oluyoruz.
Clustered Index Scan, tabloya herhangi bir koşul belirtmediğimizde ya da index tanımladığımız kolonu değil başka bir kolonu koşulumuzda belirttiğimizde karşılaşacağımız operatördür.
Clustered index Scan işlemi ise Table Scan işlemiyle hemen hemen aynı kavramı temsil etmekte olup tablo üzerinde Clustered indeks olmasına rağmen SQL Server’ın kayıtlara Table Scan işleminde olduğu gibi satır satır erişip işlem yaptığını gösterir. SQL Server’ın bu şekilde işlem yapmasının sebebi sorgu sonucunda çok fazla kayıt döndürüleceği için tablodaki verilere Table Scan işlemindeki gibi satır satır erişmenin daha hızlı olacağına karar vermesinden kaynaklanmasıdır. Bu sebeple Clustered Index Scan işlemi için Table Scan işlemi ile hemen hemen aynıdır demek de yanlış bir tabir olmaz. Çünkü SQL Server clustered indeksi filtreleme amaçlı kullanmadan tüm veriye satır satır erişmiştir.
Clustered Index Scan operatörün görüldüğü durumlarda tablolardaki kayıt sayısını azaltırsak Clustered Index Scan operatörünü başka bir operatöre geçirebiliriz. Where ifadesiyle sorgu sonunda dönen kayıt sayısını azaltmamız gerekmektedir.
Bu makalede Clustered Index Scan operatörünü görmüş olduk. Başka bir makalede görüşmek dileğiyle..
“Allah’tan kulları içinde ancak ilim sahibi olanlar korkar.” Fâtır sûresi – 28