
Bu makalede veritabanı altında bulunan tabloların üzerinde bulunan benzer index yapılarını göstermektedir. Bu komut yardımıyla aynı index yapılarımızı kullanıp kullanılmadığına göre silinmesi gerekmektedir. SQL Server’da bir tabloda aynı veya benzer index yapılarının birden fazla kez oluşturulması, sistem performansını ve kaynak kullanımını olumsuz etkileyebilir.
Bunun neden olduğu etkiler ve potansiyel sonuçları;
– Her indeks, fiziksel olarak disk alanında yer kaplar. Aynı veya benzer indeksler oluşturulduğunda, gereksiz yere depolama alanı tüketilir. Özellikle büyük tablolarda bu durum ciddi disk alanı problemlerine yol açabilir.
– Bir tabloya veri ekleme, güncelleme veya silme işlemleri sırasında SQL Server, tüm ilgili indeksleri güncellemek zorundadır. Benzer indekslerin birden fazla kez olması, her yazma işlemini daha maliyetli hale getirir ve işlem süresini artırır.
-Sorgu planlayıcı (Query Optimizer), hangi indeksi kullanacağına karar verirken birden fazla benzer indeksle karşılaşabilir. Bu durum sorgu planının gereksiz karmaşık hale gelmesine ve doğru indeksi seçememe ihtimaline yol açabilir. Aynı zamanda, yanlış indeksin seçilmesi sorgu performansını düşürebilir.
– İndekslerin yönetimi (örneğin, yeniden oluşturma, yeniden düzenleme) ve bakım işlemleri sırasında gereksiz indeksler, işlem süresini ve bakım maliyetlerini artırır. İndeks bakımının sık yapılmadığı sistemlerde, bu durum zamanla performans sorunlarına yol açabilir.
– Her indeks, sorgu yürütme sırasında bellekte ek yer gerektirir. Aynı veya benzer indekslerin olması, gereksiz bellek tüketimi ve daha fazla disk I/O işlemi anlamına gelir.
– Benzer indekslerin olması, SQL Server’ın verileri birden fazla yerde saklamasına neden olur. Bu, indekslerdeki fragmentasyon (parçalanma) problemlerini artırabilir ve performans kaybına yol açabilir.
Bu tarz indexlerin oluşturulmasının sebeplerinden önceliği sql server yapımızın her önerdiği indexin oluşturulması veya veritabanının birden fazla kişi tarafından kullanılması bu sorunun en önemli sebeplerindendir.
Aşağıdaki komut sayesinde veritabanı altında bulunan duplica indexsleri bulabiliriz. Aynı zamanda indexsin hangi tür olduğu, boyutu, ismi, indexsin etkilediği satır sayısını görebiliriz.
WITH IndexColumns AS (
SELECT
DB_NAME() AS database_name, -- Veritabanı Adı
s.name AS schema_name, -- Şema Adı
t.name AS table_name, -- Tablo Adı
i.name AS index_name, -- Index Adı
i.index_id,
i.type_desc AS index_type, -- Index Türü (Clustered / NonClustered)
SUM(ps.used_page_count) * 8 / 1024.0 AS index_size_mb, -- Index Boyutu (MB)
p.rows AS index_row_count, -- Indexteki Satır Sayısı
STRING_AGG(c.name, ', ') WITHIN GROUP (ORDER BY ic.key_ordinal) AS indexed_columns -- Indexlenen Kolonlar
FROM sys.schemas s
JOIN sys.tables t ON s.schema_id = t.schema_id
JOIN sys.indexes i ON t.object_id = i.object_id
JOIN sys.index_columns ic ON i.object_id = ic.object_id AND i.index_id = ic.index_id
JOIN sys.columns c ON ic.object_id = c.object_id AND ic.column_id = c.column_id
JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id
JOIN sys.dm_db_partition_stats ps ON p.object_id = ps.object_id AND p.index_id = ps.index_id
WHERE i.type IN (1, 2) -- Sadece Clustered ve Non-Clustered Indexler
GROUP BY s.name, t.name, i.index_id, i.name, i.type_desc, p.rows
)
SELECT
i1.database_name,
i1.schema_name,
i1.table_name,
i1.index_name AS duplicate_index, -- Sonradan oluşturulan Duplicate Index
i2.index_name AS original_index, -- İlk oluşturulan Index
i1.index_type,
i1.indexed_columns,
i1.index_row_count,
i1.index_size_mb AS duplicate_index_size_mb, -- Duplicate Index'in Boyutu
i2.index_size_mb AS original_index_size_mb -- Orijinal Index'in Boyutu
FROM IndexColumns i1
JOIN IndexColumns i2
ON i1.database_name = i2.database_name
AND i1.schema_name = i2.schema_name
AND i1.table_name = i2.table_name
AND i1.index_id > i2.index_id
AND i1.indexed_columns = i2.indexed_columns
AND i1.index_type = i2.index_type -- Aynı türdeki indexleri karşılaştırır
ORDER BY i1.database_name, i1.schema_name, i1.table_name, i1.indexed_columns;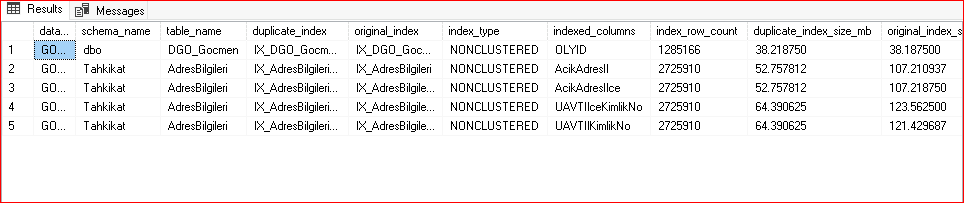
Not: SQL Server burada şuna bakıyor. Bu iki index, aynı veri setini kapsıyor mu.Evet, kapsıyor. Bu yüzden duplicate diyor. Ama normalde bunlar aynı değil. Neden Composite indexlerde istatistikler ilk kolona göre oluşur. Örnek üzerinden gidecek olursak. index kolonları IX_A (TCKMLNMR, TLPSIRNMR), IX_B (TLPSIRNMR, TCKMLNMR) belirtilen bu indexlerin istatistikleri farklı çünkü iki index te ilk koluna göre histogram oluşturmaktadır. Yani Selectivity, Cardinality estimation, Seek / Scan kararları kararları tamamen farklı olabilir. Bu açıdan bakarsak query optimizer için bunlar aynı index değildir. Neden bunlar dublica index olarak gösterilir. Sebebi sql server fiziksel açıdan bakar. Bakış açısı aynı tablo aynı kolonlar aynı boyutlara yakın ve aynı satır sayısı dublica index’e sebep verir.
İndexlerle ilgili genel duruma bakıldıktan sonra aşağıdaki komut ile ilgili index silinebilir.
DROP INDEX IndexName ON TableName;Yada indexsin disable edilmesi gerekmektedir.
ALTER INDEX [IndexName ] ON [dbo].[TableName] DISABLE;
Tüm instance altında bulunan veritabanları için bu değerin dönülmesi isteniyorsa aşağıdaki komut kullanılır.
DECLARE @command nvarchar(max)
SELECT @command = 'USE [?]
;WITH IndexColumns AS (
SELECT
DB_NAME() AS database_name, -- Veritabanı Adı
s.name AS schema_name, -- Şema Adı
t.name AS table_name, -- Tablo Adı
i.name AS index_name, -- Index Adı
i.index_id,
i.type_desc AS index_type, -- Index Türü (Clustered / NonClustered)
SUM(ps.used_page_count) * 8 / 1024.0 AS index_size_mb, -- Index Boyutu (MB)
p.rows AS index_row_count, -- Indexteki Satır Sayısı
STRING_AGG(c.name, '', '') WITHIN GROUP (ORDER BY ic.key_ordinal) AS indexed_columns -- Indexlenen Kolonlar
FROM sys.schemas s
JOIN sys.tables t ON s.schema_id = t.schema_id
JOIN sys.indexes i ON t.object_id = i.object_id
JOIN sys.index_columns ic ON i.object_id = ic.object_id AND i.index_id = ic.index_id
JOIN sys.columns c ON ic.object_id = c.object_id AND ic.column_id = c.column_id
JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id
JOIN sys.dm_db_partition_stats ps ON p.object_id = ps.object_id AND p.index_id = ps.index_id
WHERE i.type IN (1, 2) -- Sadece Clustered ve Non-Clustered Indexler
GROUP BY s.name, t.name, i.index_id, i.name, i.type_desc, p.rows
)
SELECT
i1.database_name,
i1.schema_name,
i1.table_name,
i1.index_name AS duplicate_index, -- Sonradan oluşturulan Duplicate Index
i2.index_name AS original_index, -- İlk oluşturulan Index
i1.index_type,
i1.indexed_columns,
i1.index_row_count,
i1.index_size_mb AS duplicate_index_size_mb,
i2.index_size_mb AS original_index_size_mb
FROM IndexColumns i1
JOIN IndexColumns i2
ON i1.database_name = i2.database_name
AND i1.schema_name = i2.schema_name
AND i1.table_name = i2.table_name
AND i1.index_id > i2.index_id
AND i1.indexed_columns = i2.indexed_columns
AND i1.index_type = i2.index_type -- Aynı türdeki indexleri karşılaştırır
ORDER BY i1.database_name, i1.schema_name, i1.table_name, i1.indexed_columns;'
EXEC sp_MSforeachdb @command
Sonuç olarak;
Aynı indeks yapılarının birden fazla kez oluşturulması, sorgu performansı, yazma işlemleri ve disk alanı üzerinde olumsuz etkiler yaratır. Düzenli analiz ve bakım yaparak gereksiz indekslerden kaçınmak, sistemin hem verimli çalışmasını sağlar hem de kaynak kullanımını optimize eder.
Bu makalede mssql server yapımızda duplica index bulma komutlarını görmüş olduk. Başka bir makalede görüşmek dileğiyle..
“Allah’ın, göklerde ve yerde bulunan şeyleri hizmetinize verdiğini, nimetlerini gizli ve açık olarak önünüze bolca serdiğini görmez misiniz? İnsanlardan öyleleri vardır ki bir bilgi, bir rehber ve aydınlatıcı bir kitap olmadan Allah hakkında tartışmaya kalkışırlar.”Lokman-20