
MSSQL Server Checkpoint işlemi, veritabanı yönetim sisteminin veritabanı dosyalarındaki (data files) değişikliklerin diske yazılmasını sağlayan bir işlemdir. Bu işlem, SQL Server’ın transaction log’da yapılan değişikliklerin disk üzerinde kalıcı hale getirilmesini sağlar. Checkpoint, genellikle veritabanı yeniden başlatıldığında ya da belirli aralıklarla (ya da manuel olarak) yapılabilir. Amaç, veritabanı dosyalarındaki verilerin tutarlılığını ve sağlamlığını korumaktır. Bir başka değişle SQL Server, veritabanı üzerinde yapılan değişiklikleri önce bellek (buffer pool) üzerinde gerçekleştirir. Bu değişiklikler henüz diske yazılmamışsa, bu sayfalara dirty pages (kirli sayfalar) denir. Checkpoint, bu dirty pages’leri diske(MDF) yazarak bellek ile disk arasında tutarlılık sağlar. Bu işlem, sistem çöktüğünde veya beklenmedik bir kapanma olduğunda veri kaybını en aza indirmek için önemlidir. Aslında veri kaybı olmaz veriler zaten ldf dosyasına commit edilmiş. Burada temel amaç recovery süresini kısaltmaktadır.
Transaction log’a (LDF) yazma işini Write-Ahead Logging (WAL) ve Transaction Commit süreci yapar. Yani işlem önce log’a yazılır, sonra veri MDF’ye yazılır.
Checkpoint işlemi, veritabanı recovery model ve log truncation ile doğrudan ilişkilidir. Ayrıca, veritabanı kurtarma işlemlerinin hızını ve etkinliğini de etkiler.
Checkpoint, SQL Server’ın transaction log üzerinde yapılan değişikliklerin veri dosyalarına (data files) yazılmasını sağlar. Bu, SQL Server’ın işlem günlüğündeki verileri fiziksel dosyalarla ilişkilendirir.
Bir veri değiştiğinde:
- İlk olarak log (LDF) dosyasına yazılır (Write-Ahead Logging sayesinde).
- Aynı değişiklik RAM’deki data page (buffer pool) içinde tutulur → bu sayfa artık dirty page olur.
Checkpoint çalıştığında:
- RAM’deki dirty page’leri alır,
- Veri dosyasına (MDF/NDF) yazar → artık bu sayfalar kalıcıdır.
- Bu sayede:
- RAM temizlenebilir.
- Sistem çökse bile yeniden log replay yapmaya gerek kalmaz.
Checkpoint – Log İlişkisi:
- Checkpoint log dosyasını okumaz veya doğrudan yazmaz.
- Ama log dosyasındaki işlemlerin karşılık gelen data page’leri veri dosyasına yazar.
- Böylece recovery işlemi sırasında log’tan çok az işlem geri oynatılır → hızlı başlatma sağlanır.
Teknik olarak Checkpoint şu işlemleri yapar:
- Kirli sayfaları (dirty pages) veri dosyasına (MDF) yazar.
- Transaction Log’a bir “checkpoint record” yazar → bu, en son tutarlı noktanın işaretidir.
Dirty page’lerin MDF’ye (veri dosyasına) yazılması, LDF’ye (log dosyasına) yazıldıktan sonra olur.
Bu sıralama, SQL Server’ın Write-Ahead Logging (WAL) kuralının bir parçasıdır. Commit edilmiş veya edilmemiş tüm veriler ldf dosyasına yazılmaktadır.
NOT: Secondary sunucularda sadece redo işlemi gerçekleşir. Checkpoint işlemi sadece primary olan sunucuda gerçekleşmektedir. Transaction loglara WAL mekanizmasıyla yazılır. Mdf ve ndf disklerini veriler rastgele yazılmaktadır.
Adım Adım Süreç Nasıl Gerçekleşmektedir:
1. Veri değişikliği yapılır (örnek: UPDATE Customers SET Name=’Ahmet’)
- SQL Server bu işlemi bellekteki (buffer pool’daki) ilgili veri sayfasına uygular.
- Sayfa artık dirty page olur (değişti ama henüz diske yazılmadı).
2. Aynı anda, bu değişiklik log buffer’a yazılır (RAM içinde).
- Değişiklik önce log kaydı olarak bellekteki log cache’e yazılır.
3. COMMIT geldiğinde:
- Bu log kaydı önce LDF (transaction log dosyasına) diske yazılır. Bu işlem log flush olarak bilinir. Bu olay karşımıza write ahead logging olarak çıkar. Eğer log dosyasına fiziksel olarak yazılmadan data dosyasına yazılma işlemi olsaydı her hangi bir hata sonucu server kapandığı takdirde rollback işlemi gerçekleşemezdi.
- Yani: önce log → sonra veri, kuralı zorunludur.
Bu, Write-Ahead Logging (WAL) prensibidir:
Log diske yazılmadan, dirty page MDF’ye yazılamaz.
4. Daha sonra, Checkpoint veya Lazy Writer devreye girer:
Verilerin buffer cache’den diske yazılması page flushing olarak bilinir. Bu işlemi Lazy Writer yapar. Peki bu Lazy Writer’da nerden çıktı. SQL Server düzenli olarak kaynakları monitor eder. Ve memory üzerinde bir çekişme olduğunda Lazy Writer’ı tetikler. Ve bu şekilde buffer cache’deki dirty page’lerin diske yazılmasıyla buffer cache’de diğer session’ların kullanması için yeterli yer açılır. SQL Server arka planda periyodik olarak checkpoint işlemini çalıştırır. Checkpoint’in çalışmasıyla yukarıda anlattığımız, log cache’deki kaydın ve dirty page’lerin diske yazılması işlemi gerçekleşir.
- Bellekteki dirty page’leri kontrol eder.
- Eğer bu sayfaların karşılık gelen log kayıtları LDF’ye yazılmışsa, artık bu sayfalar MDF’ye yazılabilir.
- Böylece sayfa kalıcı hale gelir, RAM boşaltılır.
Bu sıraya neden dikkat edilir. Çünkü sistem çökerse:
- MDF dosyasında bir değişiklik olabilir ama log’da karşılığı yoksa → tutarsızlık olur.
- Bu yüzden SQL Server, önce log’u garantiye alır, sonra veriyi yazar.
Kısaca Özet:
| Aşama | Hedef | Açıklama |
|---|---|---|
| 1 | RAM (Data Page) | Değişiklik yapılır, dirty page oluşur |
| 2 | RAM (Log Cache-memory’de log kayıtlarının tutulduğu alan) | Log kaydı hazırlanır |
| 3 | LDF (Log File) | Log kaydı önce diske yazılır. (WAL) Commit edilsin veya edilmesin |
| 4 | MDF (Data File) | Dirty page daha sonra MDF’ye yazılır (Checkpoint veya Lazy Writer ile) |
Checkpoint’in Kullanılma Amaçları:
- Veritabanı beklenmedik bir şekilde kapanırsa (örneğin, bir sistem çökmesi), checkpoint işlemleri sayesinde transaction log’daki işlemler disk üzerinde kalıcı hale gelir. Bu sayede veritabanı recovery süresi kısalır.
- Transaction log dosyasındaki veriler, checkpoint ile yazılmadığı sürece birikir ve büyür. Bu, disk alanı problemlerine yol açabilir. Checkpoint sayesinde bu büyüme engellenir.
- Checkpoint işlemi, veri dosyalarındaki değişikliklerin sürekli olarak diske yazılmasını sağlar. Bu da veri tutarlılığını artırır.
Aktif olan checkpoint işlemlerini görmek için aşağıdaki komut kullanılmaktadır.
SELECT
session_id,
command,
status,
start_time
FROM sys.dm_exec_requests
WHERE command = 'CHECKPOINT';
MSSQL Server Checkpoint Örneği
SQL Server’da checkpoint işlemi genellikle otomatik olarak yapılır, ancak manuel olarak da yapılabilir.
1. Otomatik Checkpoint
SQL Server, otomatik checkpoint işlemini periyodik olarak yapar. Bu aralık, recovery interval (kurtarma aralığı) adı verilen bir yapılandırma parametresi ile kontrol edilir. Varsayılan değer genellikle 1 dakikadır. Otomatik checkpoint, transaction log’un belirli bir yüzdesi dolduğunda veya belirli bir süre geçtiğinde tetiklenir.
Değiştirmek için:
EXEC sp_configure 'recovery interval', 3; -- 3 dakika olarak ayarlar
RECONFIGURE;
Not: Buffer cache’deki veriler belli bir zaman aralığında değil, işlem bazında (örneğin COMMIT) LDF dosyasına yazılır. Yani dakika bazlı değil, işlem bazlıdır.
Her veritabanı için bu yapı ayrı ayrı aşağıdaki komutla yapılandırılabilir.
ALTER DATABASE [DatabaseName] SET TARGET_RECOVERY_TIME = 60 SECONDS;Bu işlem, aşağıdaki faktörlere bağlı olarak yapılır:
- Recovery model: Full ya da Bulk-logged recovery model kullanıldığında daha sık checkpoint işlemi yapılır.
- Log file büyüklüğü: Eğer transaction log dosyası çok büyükse, checkpoint işlemi daha sık yapılır.
- Veritabanı aktifliği: Eğer veritabanı çok aktifse, SQL Server daha sık checkpoint işlemi yapar.
Bu işlem SQL Server tarafından otomatik olarak gerçekleştirilir ve genellikle herhangi bir müdahale gerektirmez.
2. Manuel Checkpoint
Manuel olarak checkpoint yapmak için CHECKPOINT komutu kullanılır. Bu işlem, tüm değişikliklerin veri dosyalarına yazılmasını ve işlem günlüğünün (log) temizlenmesini sağlar.
Örnek
CHECKPOINT;Bu komut, tüm transaction loglarının veri dosyalarına(MDF) yazılmasını sağlar.
Diyelim ki, veritabanınızda büyük bir işlem yapıyorsunuz ve işlemi bitirmeden önce sistemin kapanması durumunda son işlem kaydınız kaybolabilir. Bu durumda, işlem sırasında manuel bir checkpoint yaparak bu işlemin veritabanı dosyasına yazılmasını sağlayabilirsiniz.
3. Indirect Checkpoint (Dolaylı Checkpoint):
SQL Server 2012’den itibaren kullanılan bir özelliktir. Her veritabanı için ayrı ayrı yapılandırılabilir. Indirect checkpoint, target_recovery_time parametresi ile belirlenen süre içinde dirty pages’leri diske yazar. Bu yöntem, kurtarma süresini daha tahmin edilebilir hale getirir.
4. Internal Checkpoint (Dahili Checkpoint):
SQL Server’ın belirli işlemler sırasında otomatik olarak gerçekleştirdiği checkpoint’lerdir.
Örnekler:
- Veritabanı yedekleme sırasında (BACKUP komutu).
- Veritabanı kapatılırken.
- Bellek baskısı (memory pressure) olduğunda.
5. Checkpoint Bilgileri Görüntüleme
Checkpoint işlemine dair bilgileri sys.dm_db_checkpoint_stats dinamik yönetim görünümünden (DMV) alabilirsiniz. Bu komutun çalışabilmesi için Sql server 2019 ve üzeri bir sürüm olması gerekmektedir.
SELECT *
FROM sys.dm_db_checkpoint_stats;Bu sorgu, veritabanı için yapılan checkpoint işlemlerinin istatistiklerini gösterir. Çıktıda, en son checkpoint’in zaman bilgisi, yazılan byte miktarı ve daha fazlası yer alır.
Sql server 2017 sürümünde ise aşağıdaki komut kullanılmaktadır.
SELECT
database_id,
total_log_size_in_bytes / 1024 / 1024 AS TotalLogSizeMB,--log dosyasının toplam boyutunu megabayt (MB) cinsinden gösterir
used_log_space_in_bytes / 1024 / 1024 AS UsedLogSpaceMB,-- log dosyasının ne kadarının kullanıldığını megabayt (MB) cinsinden gösterir.
log_space_in_bytes_since_last_backup/1024/1024 AS LogSpaceUsedPercentage--son yedeklemeden sonra log dosyasının ne kadar alan kullandığını byte cinsinden gösterir.
FROM sys.dm_db_log_space_usage;
Checkpoint işlemlerini izlemek için aşağıdaki diğer yöntemlerde kullanılabilir:
1. SQL Server Logları:
- SQL Server hata loglarında checkpoint işlemleri kaydedilir.
2. Extended Events:
- sqlserver.checkpoint_begin ve sqlserver.checkpoint_end event’leri ile checkpoint işlemlerini izleyebilirsiniz.
3. Performance Monitor (PerfMon):
- SQLServer:Buffer Manager -> Checkpoint pages/sec performans sayacı ile checkpoint aktivitesini izleyebilirsiniz.
6. Checkpoint ve Transaction Log Yönetimi
SQL Server, bir transaction log’unun boyutunun kontrol edilmesine yardımcı olmak için checkpoint işlemini kullanır. Checkpoint işlemi, log truncation (log kesme) işlemiyle ilişkilidir. Transaction log yazıldığında, checkpoint yapılmadan önceki log dosyaları temizlenemez. Ancak checkpoint yapıldığında, eski log dosyaları temizlenir. Veritabanı recovery modelinin simple olması gerekmektedir.
Örnek: Log Dosyasının Boyutunu Kontrol Etme
DBCC SQLPERF(LOGSPACE);Bu komut, her bir veritabanındaki log dosyasının ne kadar dolduğunu gösterir.
DBCC SQLPERF(LOGSPACE) komutu, her bir veritabanı için log dosyasının kullanım oranlarını gösterir. Bu, checkpoint’lerin etkisiyle ilgili ipuçları verebilir.
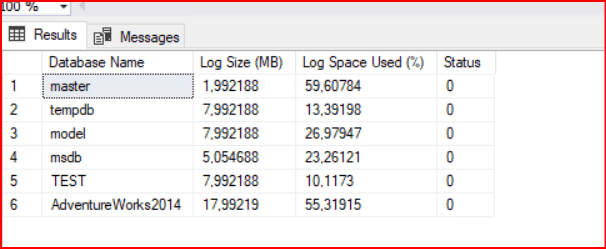
Master veritabanı altında checkpoint işlemini yaptıktan sonra log dosyasındaki değişimi görebiliriz.
use master
DBCC SQLPERF(LOGSPACE);
checkpoint
Checkpoint işlemi tamamlandığında, transaction log’una bir checkpoint kaydı yazılır. Bu kayıt, checkpoint’in tamamlandığını ve hangi noktaya kadar değişikliklerin diske yazıldığını gösterir.
Kısacası: Checkpoint işlemi, transaction log’unun boyutunu doğrudan etkilemez. Ancak checkpoint’ten sonra transaction log’undaki eski kayıtlar (artık diske yazılmış olanlar) log truncation işlemi ile temizlenebilir. Log truncation, transaction log’unun büyümesini kontrol altında tutar.
7. Recovery Model’e Göre Checkpoint Davranışı
SQL Server’da üç farklı recovery model vardır: Simple, Full ve Bulk-logged. Bu modeller, checkpoint işleminin sıklığını ve log yönetimini etkiler.
Simple Recovery Model:
- Simple recovery model kullanıldığında, transaction log’lar otomatik olarak temizlenir ve checkpoint işlemi daha sık yapılır. Yukarıda master veritabanı üzerinde örnekle göstermiştik.
- Herhangi bir yedekleme alınmazsa, transaction log’lar en kısa sürede temizlenir.
Full Recovery Model:
- Full recovery modelde, checkpoint işlemleri daha seyrek yapılır.
- Veritabanı tamamen yedeklenene kadar transaction log’lar korunur ve checkpoint ile yazılabilir.
Bulk-logged Recovery Model:
- Bulk-logged recovery modelde, büyük veri yüklemeleri (bulk operations) daha verimli yapılabilir, ancak log’lar daha fazla yer kaplar.
- Checkpoint işlemi yine seyrek yapılır.
8. Checkpoint ve Veritabanı Yeniden Başlatma
Veritabanı yeniden başlatıldığında, SQL Server en son yapılan checkpoint‘in ardından yapılmayan işlemleri transaction log üzerinden uygular. Bu sayede, veri kaybı en aza indirilir.
Diyelim ki sistem şu sırayla çalıştı:
- BEGIN TRAN
- UPDATE Products SET Stock = Stock – 10
- COMMIT yapılmadan önce sistem çöktü
- Log dosyasında bu UPDATE vardır, çünkü WAL kuralı gereği yazılmıştır.
- Ancak MDF dosyasına henüz yazılmamıştır.
- SQL Server yeniden başladığında:
- Analysis → bu işlem bulundu.
- Redo → işlem COMMIT edilmediği için geri alınacak.
- Undo → değişiklik yapılmadan önceki haline döndürülür.
Commit edilmiş olsaydı sistem açıldıktan sonra mdf dosyasına redo işlemi gerçekleşecekti.
Bu, SQL Server’ın recovery mekanizmasının en kritik parçasıdır.
Senaryo:
- BEGIN TRAN
- UPDATE Orders SET Amount = 500
- Transaction log (LDF) dosyasına bu işlem yazıldı.
- COMMIT yapıldı → log artık kalıcı.
- Ama sistem çöktü → dirty page hâlâ RAM’de, MDF’ye yazılamadı.
SQL Server Yeniden Başladığında Ne Olur?
Recovery aşamaları başlar:
| Aşama | Ne yapar? |
|---|---|
| 🔹 Analysis | COMMIT edilmiş ama MDF’ye yazılmamış işlemleri tespit eder. |
| 🔹 Redo | LDF’deki log kayıtlarını okuyarak bu işlemleri MDF’ye tekrar yazar (uygular). |
| 🔹 Undo | COMMIT edilmemiş (yarım kalmış) işlemleri geri alır. |
Kısacası:
COMMIT edilmişse ve işlem log dosyasına yazılmışsa, veri güvendedir.
MDF’ye yazılamadan sistem çökse bile, SQL Server log’dan bu işlemi bulur ve yeniden yazar (REDO).
Ekstra Bilgi:
- Bu yapı, SQL Server’ın ACID prensiplerinden “Durability” maddesini garanti eder.
- Yani COMMIT edildiyse, sistem çökse bile veri kaybolmaz.
Özetle:
- Checkpoint işlemi, SQL Server’da transaction log’daki değişikliklerin veri dosyasına yazılmasını sağlar.
- Otomatik checkpoint, SQL Server tarafından periyodik olarak yapılır.
- Manuel checkpoint, CHECKPOINT komutu ile yapılır.
- Checkpoint, log truncation işlemiyle ilişkilidir ve log dosyasının boyutunun yönetilmesine yardımcı olur.
- Veritabanı recovery model’ine göre checkpoint sıklığı değişir.
Checkpoint Performans Etkisi: Checkpoint işlemi, disk I/O işlemlerini artırabilir. Bu nedenle, özellikle yoğun yazma işlemlerinin olduğu sistemlerde checkpoint sıklığı ve yöntemi performansı etkileyebilir.Indirect checkpoint, performansı daha tahmin edilebilir hale getirir ve ani I/O artışlarını önler.
Sql server sunucusu crash olursa recovery süreci nasıl gerçekleşir?
SQL Server sunucusu çökmesi (crash) durumunda, recovery süreci belirli adımları takip ederek veritabanını tutarlı bir duruma getirmek amacıyla çalışır. SQL Server, transaction logs ve veri dosyalarını kullanarak, son bir tutarlı durumu geri yüklemek için otomatik bir kurtarma işlemi gerçekleştirir. Bu süreç, veritabanı güvenliğini sağlamak ve veri kaybını minimuma indirmek için oldukça önemlidir.
SQL Server’ın recovery (kurtarma) süreci, genellikle 3 aşamadan oluşur:
- Analysis Phase (Analiz Aşaması)
- Redo Phase (Tekrar Uygulama Aşaması)
- Undo Phase (Geri Alma Aşaması)
Aşağıda bu aşamaları detaylı olarak açıklayalım:
1. Analysis Phase (Analiz Aşaması)
Kurtarma işlemi başladığında, SQL Server önce transaction log dosyasını inceler. Bu aşamada, SQL Server, her işlemi (transaction) ve o işlemle ilişkili değişiklikleri kontrol eder. Analiz aşamasında SQL Server, aşağıdaki bilgileri toplar:
- Tamamlanmış işlemler: Veritabanında yapılan işlemlerden başarıyla tamamlananların kaydını tutar.
- Tamamlanmamış işlemler: Çökmenin hemen öncesinde başlamış, ancak tamamlanmamış işlemleri (işlem tamamlanmamışsa) not eder. Bunlar daha sonra geri alınacaktır.
Bu aşama, işlem günlüklerinin içeriğini inceleyerek sistemin önceki son başarılı durumu hakkında bilgi edinir.
2. Redo Phase (Tekrar Uygulama Aşaması)
Analiz aşamasından sonra, SQL Server Redo Phase aşamasına geçer. Bu aşama, tamamlanmış işlemleri tekrar uygular. Yani, disk üzerinde değişiklik yapılmış ancak işlem günlüğüne henüz yazılmamış olan işlemler tamamlanır.
- Transaction Log, SQL Server tarafından sürekli olarak güncellenir. Bir işlem başarılı bir şekilde tamamlandıysa, log dosyasına yazılır.
- Redo Phase sırasında, SQL Server log dosyasındaki tamamlanmış işlemleri tekrar uygular ve veri dosyalarındaki (data files) değişiklikleri uygular.(MDF) Bu, veritabanının çökmeden önceki son durumunu yeniden oluşturur.
Bu aşama, veritabanını son tutarlı duruma getirmek için yapılır. Eğer bir işlem disk üzerinde kaydedilmemişse ama işlem günlüğünde yer alıyorsa, bu işlem disk üzerinde tekrar gerçekleştirilir.
3. Undo Phase (Geri Alma Aşaması)
Son olarak, Undo Phase aşamasına geçilir. Bu aşama, tamamlanmamış işlemleri geri alır. Çökme sonrasında işlemler tamamlanmamışsa, bunların disk üzerinde herhangi bir etkisi olmamalıdır. Bu aşama, işlemi geri alarak, sistemin tutarlı ve hatasız bir duruma dönmesini sağlar.
- Tamamlanmamış işlemler: Çökmenin hemen öncesinde başlayan ancak tamamlanmamış işlemler, SQL Server tarafından geri alınır.
- Rollback işlemi yapılır. Bu, commit edilmeyen tüm işlemleri geri alarak, veritabanının son commit edilmiş duruma getirilmesini sağlar.
Recovery Sürecinin İşleyişi
- SQL Server’ın Başlangıç Kontrolleri:
- SQL Server başlatıldığında, veritabanı dosyaları (MDF, LDF) kontrol edilir.
- Log dosyasındaki en son checkpoint kontrol edilir.
- Log Dosyasının Analizi:
- SQL Server, veritabanının çökmeden önceki son checkpoint işlemini bulur.
- Bu işlem, son tutarlı durumun kaydını temsil eder.
- Redo ve Undo İşlemleri:
- SQL Server, redo phase ile disk üzerinde yapılması gereken işlemleri tekrar uygular.
- Undo phase ile tamamlanmamış işlemleri geri alır.
- Veritabanı Kurtarılır:
- Kurtarma süreci başarılı bir şekilde tamamlandığında, veritabanı son tutarlı duruma gelir ve normal işlem yapılabilir.
Recovery Model Türlerine Göre Farklılıklar
SQL Server’da kullanılan Recovery Model, kurtarma sürecini etkiler. Farklı recovery modelleri (Simple, Full, Bulk-Logged) kurtarma ve log yönetimi açısından farklı stratejiler izler.
- Simple Recovery Model:
- Eğer SQL Server çökme sonrası recovery yapıyorsa, son checkpoint’ten önceki işlemler kaybolmuş olabilir.
- Full Recovery Model:
- Bu modelde, işlem logları full backup alana kadar saklanır. Her işlem günlük kaydı tutulur ve veritabanı tam olarak geri yüklenebilir.
- Kurtarma süreci daha uzun sürebilir çünkü SQL Server, her işlem için log dosyasını kontrol etmek zorundadır.
- Recovery sürecinde, son checkpoint’ten sonra yapılan işlemler de geri uygulanır.
- Bulk-Logged Recovery Model:
- Bu model, büyük veri yüklemeleri gibi işlem türlerinde, işlemleri bulk-logged olarak kaydeder. Bu modelde, log dosyası daha küçük tutulur ve işlem süreci hızlanır.
- Ancak bu modelde de full backup ve differential backup yapılabilir.
Aşağıdaki yazı veritabani.gen.tr’den alınmıştır. Detaylı bir açıklama olduğu için paylaşıyorum.
Bütün data page’lerin(buffer cache’e aktarılan) page header’ında(page’in metadata bilgisini tutan 96 byte’lık bir alan) bu page’i etkileyen son log dosyasının LSN bilgisi tutulur. SQL Server recover olurken(ayağa kalkarken) transaction log dosyasını kullandığını daha önce anlattım. Data page’lerin header’ında ilgili log kaydının LSN bilgisinin olması log kaydının nasıl recover olacağına(redone/roll forward veya undone/roll back) karar verilmesini sağlar. Basitçe hangi durumda ne gerçekleşeceğini aşağıda görebilirsiniz. Commit edilmiş bir transaction ile alakalı bir log kaydı için; Data page’in header’ında ki LSN, log kaydının LSN’ine eşit yada büyükse, bu ilgili log kaydının diske yazıldığını gösterir ve hiç bir işlem yapılmaz. Data page’in header’ında ki LSN, log kaydının LSN’inden küçükse, bu ilgili log kaydının diske yazılmadığını gösterir ve redone işlemi yapılarak diske yazılması sağlanır. Commit edilmemiş bir transaction ile alakalı bir log kaydı için; Data page’in header’ında ki LSN, log kaydının LSN’ine eşit yada büyükse, ilgili log kaydının undone işlemi yapılması gerekir.(Normal şartlar altında WAL mekanizması böyle bir durumun olmamasını sağlar.) Data page’in header’ında ki LSN, log kaydının LSN’inden küçükse, bu ilgili log kaydının diske yazılmadığını gösterir ve transaction commit olmadığı için hiç bir işlem yapılmaz.
Bu makalede checkpoint işlemini detaylı bir şekilde ele almış oldum. Başka bir makalede görüşmek dileğiyle.
De ki: “Şüphesiz benim namazım, bütün ibâdetlerim, hayatım ve ölümüm, Âlemlerin Rabbi Allah içindir.” Enam-162