
Bu makalede Clustered Index’in ne olduğunu detaylı bir şekilde görmüş olacağız. SQL Server’da çeşitli index türleri bulunur, ancak en yaygın kullanılanları şunlardır:
Aşağıdaki komut yardımıyla tablo altında bulunan clustered ve nonclustered index yapılarımızı görebilir. Bu sp yardımıyla hangi kolunlara index altıldığı hangi filegroup üzerinde olduğu görülebilir.
EXEC sp_helpindex 'Person.Person'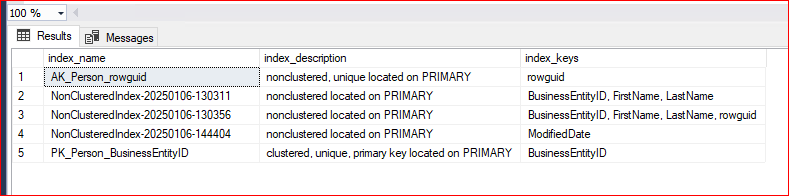
Şimdi makalemizin başlığı olan Clustered index yapısını detaylı bir şekilde inceleyelim:
Her tablo yalnızca bir tane olabilir. Tabloyu fiziksel olarak düzenler ve sıralar. Bütün tablo clustered indexs’e göre diskte mantıksal olarak sıraya tutulur. Bu nedenle bir tablo üzerinde yalnızca bir tane clustered index olabilir. Leaf Level’da verinin tüm sütunlarıyla birlikte kendisi bulunmaktadır. İnclueded kolon olmaz.
Oluşturduğunuz bir tablo üzerinde eğer id kolonunu “SET PRIMARY KEY” yaparsanız, bu kolon otomatik olarak bir CLUSTERED INDEX oluşturur. Unique te olabilir non unique’te olabilir. Non unique olursa clustered index’e sahip tabloda oluşturacağımız non clustered index’lerin leaf level’indeki row locator’da ki clustered index key’leri unique hale getirmek için uniqueifier isminde 4 byte’lık bir belirleyici koyar. Bu şekilde non clustered index kullanılarak yapılan bir aramada ihtiyacı olan veriyi bulmasını sağlar. ekstra maliyet, ekstra büyüklük.
Tabloya primary key koyarsanız sql server otomatik olarak arka tarafta primary key koyduğunuz kolona clustered index koyar. Default olarak bu şekilde clustered index koysa bile siz primary key kolonun non clustered olması için force edebilirsiniz.
Aşağıdaki iki komut kullanılabilir. İkinci komut SSMS arayüzünden alınmıştır.
CREATE CLUSTERED INDEX [ClusteredIndex_Table1_id] ON [dbo].[Table_1] (id);
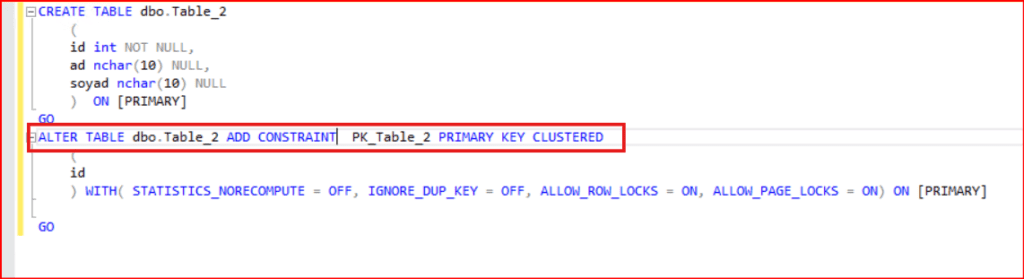
Aşağıdaki komutları mssql server’da index yapısında kullanılan parametreler makalesinde detaylı bir şekilde bulabiliriz.
CREATE UNIQUE CLUSTERED INDEX [ClusteredIndex_Table1_id] ON [dbo].[Table_1]
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GOYukarıdaki komutta clustered index önüne non ifadesi getirilerek oluşturduğumuz index nonclustered olarak oluşmaktadır. Bu ifade ise sorgulama işlemlerinde Table scan ifadesi olarak karşımıza çıkmaktadır. Bu şekilde nonclustered yapılırsa leaf level’de sadece ilgili kolon bulunmaktadır. Tablomuzda sadece insert işlemi genelde yapılıyorsa bu yapıda oluşturmak faydalıdır.
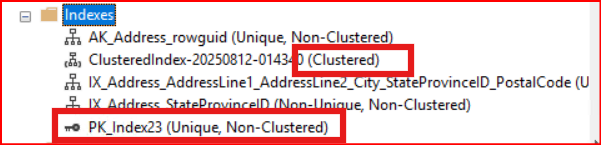
SQL Server’da PRIMARY KEY tanımladığında, eğer tablo üzerinde clustered index yoksa, otomatik olarak clustered index oluşturur.. Ama zaten clustered index varsa, PRIMARY KEY eklerken nonclustered olarak oluşturman gerekir. Tablo üzerinde primary key yoksa aşağıdaki resimde görüldüğü gibi clustered index eklenir.
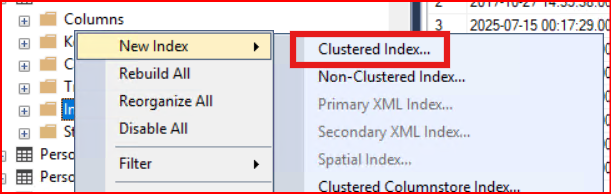
Aşağıdaki komut ile tablo üzerinde ilgili kolona primary key tanımlayacak bir nonclustered index oluşturabiliriz. Non ifadesi olmazsa clustered index olmaktadır.
alter table person.address add constraint PK_Index23 primary key nonclustered
(
AddressID asc
)
Eğer bir tabloda clustered index nonclustered olarak tanımlanırsa o index’in yanında tablodaki tüm değerler bulunmaz. O index’in leaf levelinde sadece primary key olarak seçtiğin kolon ve satırın tablodaki asıl veriye ulaşmak için bir row locator bulunur. Eğer tabloda hiç clustered index yoksa bu gösterici satırın fiziksel adresidir.
Primary key haricinde herhangi bir kolonu clustered index yaptığımda ilgili kolon haricinde tablodaki diğer tüm kolonlar leaf level’de bulunmaktadır.
İki Yapı Arasında Temel Farklar
| Özellik | Primary Key (PK) | Sadece Clustered Index |
|---|---|---|
| NULL değer | Kesinlikle izin vermez (NOT NULL zorunlu) | NULL değerlere izin verebilir (tanıma bağlı) |
| Tekillik (Unique) | Her zaman UNIQUE zorunlu | UNIQUE olması şart değil (ama genelde önerilir) |
| Referans (Foreign Key) | Diğer tablolar tarafından referans alınabilir | FK olarak kullanılamaz |
| Tanım Netliği | Veri modelinde “ana kimlik” olarak açıkça belirtilir | Sadece performans için bir yapıdır |
Veritabanı altında herhangi bir sorguda index force edilebilir.
Select*from tableName with (INDEX=IndexName)Bu makalede clustered index yapısını detaylı bir şekilde görmüş olduk. Başka bir makalede görüşmek dileğiyle..
“Onlar, yaptıkları dünyada ve ahirette boşa gitmiş olanlardır. Ve onların yardımcıları yoktur.” Al-i İmran Suresi, 22. Ayet