
Bu makalede MSSQL Server Index konusunu detaylı bir şekilde görmüş olacağız. Index veritabanımızın performansını etkileyen önemli bileşenlerden bir tanesidir. Bu yapı ile verilerimize daha az okuma yaparak ve minumum maliyette verilerime ulaşabiliriz.
Kullanıcı bir tabloyu kullanmak istediğinde öncelikle tablo üzerinde bir index yapısı var mı diye bakar. Sorgulanacak tablo üzerinde bir index yapımız varsa sql server bu index yapısını kullanır.
Anlamamız açısından elimizde bir telefon kayıt defteri düşünün kullanıcı Yunus isminde bir şahsı aramak istediğinde telefon defteri belirli bir sıralamaya göre olmadığı için kullanıcı ilgili kaydı bulmak için telefon kayıt defterini baştan sona taramaktadır. Eğer bizim telefon kayıt defterimizde bulunan veriler bölümlenmiş bir şekilde sıralı olduğu zaman kullanıcı hemen istediği kaydı bulmuş olacaktır. Bu yapı sql server üzerinde index yapısı olarak karşımıza çıkmaktadır. Index yapıları Binary Tree diğer ifadeyle Balance Tree algoritmasıyla çalışmaktadır. Şimdi bu yapının ne işe yaradığına değinelim.
B tree yapısı 3 level’den oluşur. Bu ağaç yapısı verinin boyutuna göre değişmekle birlikte Non-Leaf ve Leaf Node’lar bulunmaktadır.
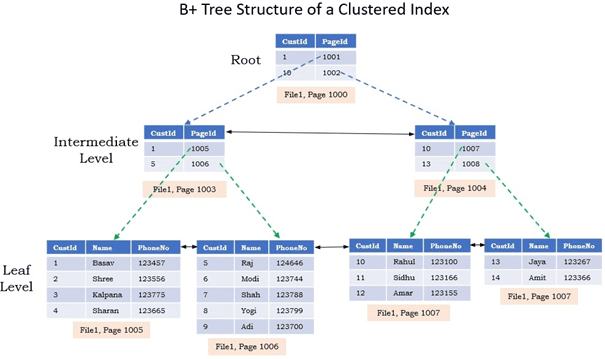
Non-Leaf(Root ve Intermediate) Node’larda veri tutulmaz sadece alt node’ların id’leri tutulur ve referanslama yapılır. Leaf Node’larda ise veriler tutulur. Bu yapı sayesinde ilgili kayıtlara ilgili referanslar üzerinden hızlı bir şekilde erişebiliyoruz.
Root Level ağaç yapısının en üst page’idir. Index üzerinde arama işlemi yapıldığında aramanın başlangıç kısmıdır. İstenilen veri id değerine göre yönlendirme yapılmaktadır.
Intermediate Level, Root Level Page’den sonra intermediate level page’ler gelir. Index’in büyüklüğüne göre bir ya da birden fazla intermediate level vardır.
Leaf Level, B tree yapısının son kısmıdır. Yukarıdaki resimde de görüldüğü gibi verinin kendisinin tutulduğu kısım olarak karşımıza çıkmaktadır.
Not: Nonclustered index’ler, tablodan ayrı bir yapıda saklanır ve her kayıt, veriye ulaşmak için bir bookmark (RID veya clustered key) içerir. Bu bookmark leaf seviyesinde bulunur; intermediate seviyeler yalnızca arama yolunu yönlendirir. Bu notu analiz edecek olursak:
- “Non clustered index’ler diskten ayrı bir yerde tutulurlar. Ancak fiziksel olarak başka bir diskte demek değil, veritabanı içinde farklı bir yapıda saklanır.
- Non clustered index sayfaları page_id’lere sahiptir ama kullanıcı açısından önemli olan anahtar değer ve sonrasında gelen bookmark (yani: RID veya clustered key)’dir.
- Clustered key veya RID, non clustered index’in leaf level’ında bulunur, intermediate seviyede değil. Intermediate seviyeler yalnızca arama yollarını tutar (B-tree yapısında yönlendiricidir).
Sayfamızda Bakım ve Performas bölümünden clustered index ve nonclustered index arasındaki farkları detaylı bir şekilde görebilirsiniz.
Index bu kadar yararlıysa her sorgumuz için index oluşturmamız yarar sağlar mı? Hayır sağlamaz. Çünkü oluşturulan her index aslında veritabanı altında bir sanal tablo olarak karşımıza çıkar diskte yer kaplamaktadır. İnsert update delete işlemlerinin yoğun olduğu tablolarda index oluşturmak daha eklenecek ve silinecek ve güncellenecek kayıt için index yapısının değişmesine sebebiyet verecektir. Yapılan her işlem indexs’ede uygulanacaktır. Buda çok maliyetli bir işlem olarak görülmektedir. Bu sebeple index doğru karar vererek oluşturulması gerekmektedir. Bu yüzden Select ifadesinin olduğu sorgularda kullanılması performans anlamında katkı sağlayacaktır.
Birbirine benzer indexs’ler attığınızda bu indexs’ler birbirinin kullanımını da etkiliyor olabilir. Genellikle bu yapıdan kaçınılması gerekmektedir. Gereksiz bir maliyete sebebiyet vermektedir.
Not: İndex atarken her sorguya özel atılmamalı mümkün olduğu kadar az ve ortak indeksler kullanılması daha iyi diyebiliriz.
Not: Tek indexs’li bir tabloda INSERT ya da UPDATE işleminde, aslında iki tane işlem yapmış olursunuz. Biri tablo verisini yazmak ya da güncellemek için diğer yapılacak işlem ise indeks’i yazmak ve düzenlemek için yapılır. İndeks verileri sıralama tipine göre yeniden dağıtılır.
Not: Clustered Index sadece 1 tane olabilir. Nonclustered Index 999 tane olmaktadır.
Not: ASC, DESC gibi sıralama tipi yapıları bulunmaktadır.
Index yapıları tablolardan ayrı bir yerde tutulurlar zamanla kullanıcıların insert update ve delete işlemleri sonucunda index yapılarımız fragmentation olur. Bu yapının önüne geçmek için belirli aralıklarla index bozulmalarının düzeltilmesi gerekmektedir. Sayfamızda bulunan Rebuild ve Reorganize makalesinde detaylı bir şekilde görebiliriz.
Not: Bir index oluşturduğumuzda o index’e ait istatistik de oluşur. Ama index birden fazla kolon içeriyorsa sadece ilk kolon için istatistik oluşturulur. Index’i rebuild ettiğimizde istatistik te güncellenir. Index reorganize işlemlerinde istatistikler güncellenmez.
Not: Bir tabloya indexs atmadan önce tablomun boyutunu sağ tıklayıp propertiesdan bakmak gerekiyor çünkü tablo çok büyükse ilgili tabloya ve koluna erişilemez olacaktır.
Not: Tablolarda indexs oluşturacağımız zaman indexsi iptal edersek ilgili tablo bozulabilir o yüzden tavsiye edilmeyen bir yöntem ama istatistikleri güncellerken herhangi iptal durumunda bir sıkıntı olmamaktadır. Clustered indexs’de tabloya lock koyar, nonclustered indexs’de ise ilgili koluna koyar. İndex oluştururken online ifadesi ile tabloya erişim sağlayabiliriz. Bir tabloya index oluştururken dikkatli olmalıyız. Çünkü biz index koyarak veriyi hızlı okuyacağımızı zannederiz ama yoğun bir şekilde insert update delete işlemleri varsa başımıza sıkıntı açabiliriz.
Indexslerin pasif yapılması index tanımlama bilgisini sistem kataloglarından silmez ama index’in içerdiği asıl veriyi siler. Non-clustered index’in pasif yapılması sadece index’e ulaşımı engeller ama clustered indexlerde ise drop veya rebuild etmedikçe tablonun verisine ulaşımı engeller. Index’i kısa süre için silip tekrar oluşturmamız gerekiyorsa bu seçeneği kullanabiliriz. Sayfamızda indexslerin aktif pasif edilmesi makalesinden detaylı bir şekilde okuyabilirsiniz.
Indexslerin silinmesi clustered index’ler silindiğinde leaf node’larda tutulan veri, sıralanmamış heap table’larda tutulmaya başlanır. Hem tanımla bilgisi hem de index’in verileri diskten silinir. Primary key olarak tanımlanan clustered index silinemez. İlk önce tablodaki bu constraint kaldırılmalıdır.
Not: Sürekli kullanmış olduğumuz sorguları incelediğimizde eğer aynı kolunlar üzerinde join işlemleri yapılmışsa join yapılan kolonlar üzerinde index tanımlamamız performans anlamında bizlere iyi bir katkı sağlayacaktır.
Not: Sql server’da heap tablolara insert yazma işlemi çok hızlıdır. Çünkü insert veriyi nereye yazacağım derdiyle uğraşmaz. Hemen yazar geçer rastgele, sorgulama işlemlerinde çok yavaş olmaktadır. Bir yığın yapısıyla, veritabanı motorunun yeni verileri nereye ekleyeceğini bulmasına gerek kalmaz. Sadece son sayfaya veri ekler veya doluysa yeni bir sayfa ayırır ve verileri o sayfaya yazar.
Not: Mevcut sorgunuzda sürekli aynı kolon üzerinde join yapan kolonlarınız varsa mutlaka join yapılan kolonlar üzerinde index tanımlaması yapmamız gerekmektedir.
Non-clustered indexs’e örnek olmak açısından aşağıdaki sorgu çalıştırılır. Makalenin başında clustered index yapısı görülmektedir.
SELECT lastname, firstname FROM member WHERE lastname = 'Rudd'Önceden tanımlamış olduğumuz non clustered indexsin ilgili kolonu için Index Pages üzerinden arama yapılmaktadır.

Index Pages üzerinden arama işlemi yapılır.

Sorgumuzda kullandığımız lastname’i bulup resimde görüldüğü gibi clustered id değeri ile Data Pages sayfasına geçiş yapılır. Data Pages bölümünde clustered id değeri ile verinin kendisinin olduğu leaf level’de gerekli olan firstname kolonu alınmaktadır.

Sql serverda bir index ilgili veriye ulaşmak için tüm pagelerin içerisinde verileri okumaz ilgili page’in page header’ında genel özete ve sayfa sonunda slot dizinine(slot array) baktıktan sonra ilgili verinin ilgili page de olup olmadığına karar verir. Page header da genel olarak m_pageId(Sayfa kimliği), m_type (Sayfa türü: 1=Data, 2=Index), mnextPage-mprevPage(Sayfa zinciri), Metadata: ObjectId, PartitionId gibi bilgilere bakmaktadır. Slot dizini ise sayfa sonunda bulunan 2 bytlık girişlerdir. Burada page içerisindeki bir satırın başlangıç ve bitiş ofsetini tutmaktadır. Fiziksel sırayı yansıtmaktadır. Slot dizinini kullanarak doğrudan satıra gider. Binary search ile hızlı bulma yapar.
Aşağıdaki sorgu ile page içerisindeki slot değerini görmüş oluruz.
DBCC TRACEON(3604);
DBCC PAGE('AdventureWorks2017', 1, 1265, 3);
Yukarıdaki resim, DBCC PAGE komutuyla bir SQL Server veri sayfasının içeriğini incelediğinizde aldığınız detaylı bilgileri gösteriyor.
Slot 0: Sayfadaki ilk satırı (row) temsil eder. SQL Server’da her sayfa (8KB) içinde birden fazla satır bulunabilir. Her satır bir slot numarasıyla tanımlanır. Column 1: İlk sütun (BusinessEntityID),Offset 0x4: Verinin sayfa içindeki başlangıç konumu (hexadecimal), Length 4: Verinin byte cinsinden uzunluğu
BusinessEntityID = 13404: Gerçek veri değeri

Bu makalede index nedir konusuna değinmiş olduk. Başka bir makalede görüşmek dileğiyle..
Gerçekten Allah’ın Kitab’ını okuyanlar, namazı dosdoğru kılanlar ve kendilerine rızık olarak verdiklerimizden gizli ve açık infak edenler; kesin olarak zarara uğramayacak bir ticareti umabilirler. Fatır Suresi, 29. Ayet