
Bu makalede MSSQL Server Execution Plan Filter Operatörünü detaylı bir şekilde görmüş olacağız. SQL Server’da bir sorgu çalıştırdığınızda, Filter operatörü bir “eleme” mekanizması olarak görev yapar. Genellikle bir veri kümesi içindeki satırların belirli bir koşulu (predicate) sağlayıp sağlamadığını kontrol eder ve sadece sağlayanları bir sonraki aşamaya iletir.
Bu operatör execution plan yapılarında group by ifadelerinde sonra filtreleme işlemi için kullanmış olduğumuz Having operatöre kullanıldığında karşılaşılan bir operatör olarak karşımıza çıkmaktadır. Computed Column (hesaplanmış sütun) üzerinde filtreleme yapıldığında görülmektedir. Sorguda bir Scalar Aggregate (MIN, MAX gibi) sonucuyla karşılaştırma yapıldığında görülmektedir. Bir başka karşılaşacağımız nokta sorgu optimizasyonu sırasında SQL Server’ın veriyi doğrudan indeksten çekemediği karmaşık filtreler olduğunda.
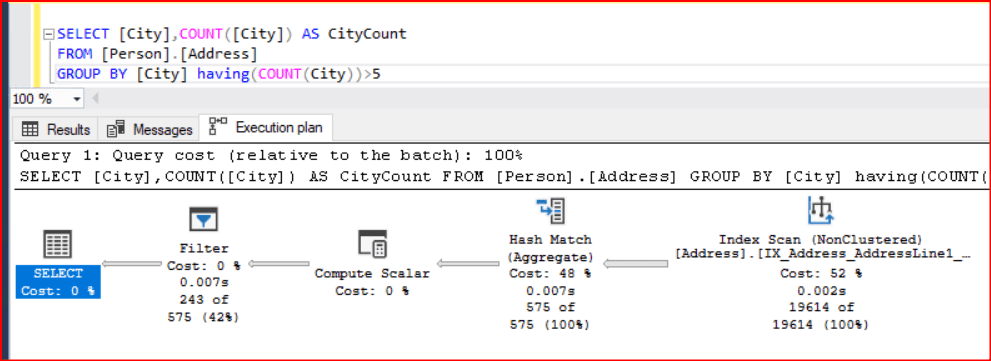
Having operatörünü kullandığımızda Execution planımıza Filter operatörü de eklenmiş oldu. Execution planlarımızı sağdan sola değerlendirdiğimizi düşünürsek dikkat edilmesi gereken bir nokta Filtre operatörünün Hash Match (Aggregate) operatöründen sonra yani veriler gruplandıktan sonra gruplanmış veriler üzerinde bir filtreleme işlemi uygulamasıdır. Bu da Having operatörü koşul belirtmek için kullanılsa bile Where operatöründe olduğu gibi işlemleri hızlandırmak yerine daha çok yavaşlatmaktadır. Çünkü daha önce de belirttiğimiz gibi tüm verinin gruplanması işlemi çok zaman alan bir işlem olup performans için gruplanacak olan veri sayısını düşürmemiz gerekmektedir. Hâlbuki Having operatörü ile gruplanan veri sayısı değişmez tüm veriler gruplandıktan sonra oluşan veri kümesi üzerinde filtreleme işlemi yapılır. Bu da Where operatörünün Having operatöründen daha performanslı çalıştığını gösterir.
Compute Scalar operatörü ise bir matemetiksel işlem yapıldığı için kullanılmıştır.
Şimdi where ve having arasındaki farkları performans anlamında neyin daha iyi olup olmadığını belirleyelim.
WHERE Operatörü Execution sırasında veriler daha çekilmeden önce (veya çekilirken) çalışır. Yani, veri taraması (Scan) veya indeks taraması (Index Seek) yaparken satırları filtreler.
• Avantajı:
WHERE sayesinde veritabanı gereksiz verileri en baştan eler. Bu da daha az veri okumak, daha az I/O, daha az bellek tüketimi ve dolayısıyla çok daha hızlı execution plan anlamına gelir.
• Execution Plan’da etkisi:
Genellikle Index Seek, Predicate Pushdown gibi optimize edilmiş planlar görürüz. Filtreleme erkenden yapıldığı için Query Optimizer daha agresif optimizasyonlar uygulayabilir.
HAVING Operatörü Gruplama (GROUP BY) ve agregasyon (SUM, COUNT, AVG vs.) yapıldıktan sonra çalışır. Yani veriler önce çekilir, gruplandırılır ve bu grupların sonuçları üzerinde HAVING filtresi uygulanır.
• Dezavantajı:
Çok fazla veri okunup belleğe alındıktan sonra filtreleme yapıldığı için, özellikle büyük veri setlerinde gereksiz işlem yükü oluşur.
Daha çok veri taranır, daha çok CPU ve bellek kullanılır.
• Execution Plan’da etkisi:
Planın başlarında büyük Scan veya Hash Aggregate işlemleri olur. HAVING sonrası filtre azalsa bile, başta fazladan iş yükü oluştuğu için performansı kötü etkileyebilir.
Sonuç olarak:
• Eğer satır bazlı bir filtre yapıyorsan, mutlaka WHERE kullanmalısın.
• HAVING sadece gruplandırılmış sonuçlara özel bir filtre gerekiyorsa kullanılmalı.
• WHERE kullanımı, execution plan’da daha az adım, daha küçük veri boyutu ve daha hızlı sorgular anlamına gelir.
Bu plan görüldüğünde ne yapılması gerekmektedir.
- Filtreleme işlemi bir indeks üzerinden değil de, tablonun tamamı okunup sonra “Filter” operatörü ile elenerek yapılıyorsa, o kolon için bir Non-Clustered Index oluşturmayı düşünün. Hedefimiz, “Filter” yerine “Index Seek” görmektir.
- SQL Server, tablodaki veri dağılımını yanlış biliyorsa, veriyi çekip sonra elemeyi (Filter) daha “ucuz” sanabilir. UPDATE STATISTICS [TabloAdi] komutu ile planın optimize edilmesini sağlayın.
- Eğer HAVING içinde filtreleme yapıyorsanız ve bu filtre aslında gruplama öncesi yapılabilecek bir filtreyse, bunu WHERE içine çekin. Bu, Filter operatörüne giden veri miktarını azaltır.
Bu makalede execution yapılarında görülen Filter ifadesine değinmiş olduk. Başka bir makalede görüşmek dileğiyle..
Onlar ki, Allah anıldığı zaman kalpleri ürperir; kendilerine isabet eden musibetlere sabredenler, namazı dosdoğru kılanlar ve rızık olarak verdiklerimizden infak edenlerdir. Hac Suresi, 35. Ayet