
Table Scan, SQL Server’ın bir sorguyu çalıştırırken tüm tabloyu baştan sona taraması işlemidir. Bu genellikle bir indeks olmadığında veya indeks kullanılamadığında ortaya çıkar.Kısacası tablo baştan sona kadar taranmaktadır. Genellikle Heap Tablo olarak adlandırılmaktadır. Yani belirli bir sıraya göre olmadan dağınık tablo yapılarında görülür.
Table Scan’in Avantajları:
Küçük Tablolar İçin Performanslıdır. Küçük boyutlu tablolar (örneğin 100-200 satır) için table scan hızlı olabilir çünkü SQL Server tüm tabloyu belleğe alıp işlemi hızlıca tamamlayabilir. İndeks oluşturma ek yükü olmadan veriye doğrudan erişebilir.
Eğer tabloya çok sık yazma (INSERT/UPDATE/DELETE) işlemi yapılıyorsa, fazla indeks olması güncelleme performansını düşürebilir. Bazen table scan, indeksin sürekli güncellenmesinden daha hızlı olabilir.
Table Scan’in Dezavantajları:
Büyük Tablolarda Performans Problemi Yaratır. Eğer tabloda milyonlarca satır varsa, her sorguda tüm tabloyu taramak çok maliyetlidir. Bu durumda, index seek ile belirli satırlara hızlıca ulaşmak daha iyidir
CPU ve I/O Kullanımını Artırır. Tüm tabloyu okumak, disk I/O ve CPU kullanımını artırır, bu da sunucunun genel performansını düşürebilir. Özellikle büyük veri tabanlarında, diğer sorguların da yavaşlamasına neden olabilir.
Heap Table üzerindeki tüm kayıtların okunması işlemi Table Scan operatörü ile temsil edilir.
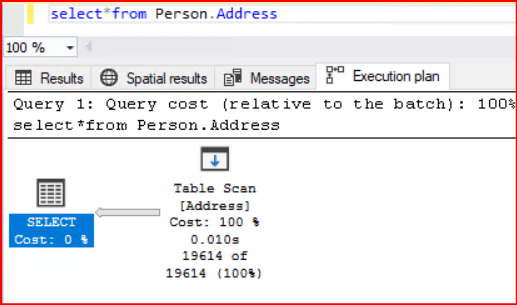
Grafiksel Execution planlar okunurken sağdan sola doğru yorumlama yapılır. Çünkü en sol tarafta ilk yapılan işlem belirtilmektedir. Bizim örneğimizde olduğu gibi önce Table Scan ile tablo taranmış ve Select ikonu ile veriler gösterilmiş oldu.
Yukarıdaki sorgu sonucunda tüm tablo sonucu getirildiği için Table Scan işlemi gerçekleşir. Tablomuzda herhangi bir clustered indexs yapısı yoktur. Bazı durumlarda sql server herhangi bir indexs yapısı olmadığı için table scan yapısını tercih etmektedir.

- Actual Number of Rows Read (19,614): Sorguyu çalıştırmak için tablodan fiziksel olarak okunan toplam satır sayısıdır.
- Estimated Number of Rows (19,614): SQL Server’ın istatistiklere bakarak bu işlem için okuyacağını tahmin ettiği satır sayısıdır. Tahmin ile fiili rakamın aynı olması, veri tabanı istatistiklerinizin güncel olduğunu gösterir.
- Estimated Row Size (4,241 B): Her bir satırın bellekte kapladığı tahmini boyuttur.
Execution plan yapımızda bulunan Table Scan ifadesinin üzerine geldiğimizde ilgili operatörü açıklayan Tooltip penceresi karşımıza geçmektedir. Bu tooltip penceresinde ilgili operatör ile ilgili detaylı bilgilere ulaşabiliriz. MSSQL Server Execution Plan Yorumlanması makalesinde ilgili bölümlerin ne işe yaradığını görebiliriz.
Table scan operatörü olan bir tabloya clustered index koymak istersek ilgili işlemlerin yapılması gerekmektedir. Öncelikle clustered index oluşturacağımız zaman ONLINE=ON parametresinin kullanılması gerekmektedir. Çok kısa süreliğine (başlangıçta ve bitişte) kilit koyar ancak işlem devam ederken kullanıcılar veri okumaya ve yazmaya (INSERT/UPDATE/DELETE) devam edebilir. Sch-M (Schema Modification) kilidi koyar. Bu ifadenin kullanılmaması tabloya tamamen kilit koymasına sebep olmaktadır. Enterprise sürümü gerektirir ve işlem daha fazla tempdb alanı ile CPU tüketir.
Clustered index koyulacak kolunun tekil(UNIQUE) olması şart değildir. Eğer seçtiğiniz kolon tekil değilse (örneğin “Şehir” kolonuna index koydunuz), SQL Server her satıra gizli bir “uniquifier” (4-byte’lık bir belirteç) ekler. Bu, veriyi içeride tekilleştirmek için yapılır. Clustered Index’in mümkünse Unique (Tekil), Narrow (Dar/Küçük veri tipi) ve Static (Değişmeyen) bir kolon (genellikle Primary Key gibi bir ID) olmasıdır.
Dikkat Etmeniz Gerekenler
- Disk Alanı: Index oluştururken tablonun neredeyse bir kopyası kadar boş alana (hem veritabanında hem de tempdb’de) ihtiyacınız olabilir.
- Log Dosyası: Büyük tablolarda index operasyonu Transaction Log dosyanızı hızla şişirebilir. Disk alanınızı kontrol edin.
- Performans: İşlemi sistemin en sakin olduğu saatlerde yapmanız önerilir.
Eğer bir kolondaki değerler benzersiz (unique) ve boş olamaz (not null) ise ve bu kolon tabloya Primary Key (PK) olarak tanımlanmışsa; oluşturulan Clustered Index yapısı anahtar simgesiyle ve PK ile başlayan bir isimle görünür. Eğer bu özellikler olsa bile kolon Primary Key olarak atanmamışsa veya bu özellikler yoksa, sadece belirtilen index ismi görünür ve parantez içerisinde (Clustered) yazar. Hangi kolonda Clustered Index oluşturulursa oluşturulsun, tablo fiziksel olarak (leaf level’da) bu kolona göre sıralanır. Bir tabloda sadece 1 tane Clustered Index bulunabilir.”
Bu makalede MSSQL Server Execution Plan Table Scan Operatörünü görmüş olduk. Başka bir makalede görüşmek dileğiyle.
“De ki: Hiç bilenlerle bilmeyenler bir olur mu?”Zümer sûresi-9