
Bu makalede MSSQL Server Nested Loops join türünü ele almış olacağız. Sql server da kullanıcı bir sorgu yazarken inner-left-full-right-cross join türleri olan mantıksal join yapılarını kullanmaktadır.
SQL Server Query Optimizer, yazdığınız bir sorguyu en verimli şekilde çalıştırmak için verileri nasıl birleştireceğine karar verirken üç temel fiziksel join operatöründen birini seçer. Execution Plan’da gördüğünüz bu join türleri, aslında veritabanı motorunun “arka mutfakta” verileri hangi algoritmayla harmanladığını gösterir.
Şimdi ilk olarak execution planda sıklıkla karşılaştığımız Nested Loops join türüne değinelim:

Yukarıdaki resimde:
- Üstteki Ok (Outer Input): Her zaman “Dış Tablo”dan gelen veriyi temsil eder.
- Alttaki Ok (Inner Input): “İç Tablo”dan gelen veriyi temsil eder.
Bu join türü, programlamadaki foreach döngüsüne benzer. Üstteki tabloya Outer Input (Dış Giriş), alttakine Inner Input (İç Giriş) denir.
- Çalışma Mantığı: Dış tablodaki her bir satır için, iç tabloda eşleşen bir satır olup olmadığına bakılır. Kısacası sıralı bir şekilde outer tablosunda her değeri inner tablosundaki tüm satırlar karşılaştırır. Bu şekilde birleştirme işlemi yapılmaktadır.
- Ne zaman görünür?
- Bir tablo çok küçük, diğeri büyük olduğunda.
- Join yapılan sütunlarda (özellikle iç tabloda) Index olduğunda. Aynı zamanda performanslı çalışır.
- Sorgu sonuç kümesi küçük olduğunda.
Eğer Nested Loops çok uzun sürüyorsa, alttaki tabloda (Inner Input) bir index eksikliği olabilir. Eğer binlerce satır için binlerce kez “Index Seek” yapılıyorsa, bu durum performans kaybına yol açar. Index’lerinizi kontrol edin.
Outer olarak işaretlenen tablonun join yapılan kolonunda index varsa çok performanslı çalışacaktır. Karmaşıklığı O(NlogM) dir.
Not: Birleşime girecek tabloların birinde indexs tanımlı diğerinde yoksa ise bu join işlemi kullanılmaktadır. Genellikle oluşan execution planda bu yapı karşımıza çıkmaktadır.
Not: Bu yapıda satır satır okuma işlemi yapılmaktadır. Bu şekilde çalışan operatörlere Non Blocking operatörler denilmektedir.
Sorgularımızın Execution planımızda ilgili operatörün Tooltip penceresi inceleyebiliriz.
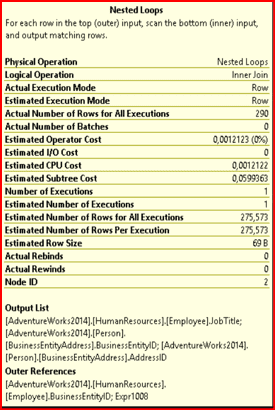
Tooltip penceresini detaylı incelediğimizde:
- Outer References (Dış Referanslar): Tablonun en altında gördüğün bu bölüm, “Dış” tablodan gelen ve “İç” tabloda aranan sütunu gösterir. Görsele göre; [Employee].BusinessEntityID sütunu dış tablodan geliyor. Bu, SQL Server’ın önce Employee tablosuna gittiğini kanıtlar. İç tabloda hangi tablo ile birleştirme yaptığını ise Output List kısmına baktığımızda BusinessEntityAddress tablosuna gittiğini çıkarabiliriz.
- Çalışma Mantığı Notu: En üstteki açıklamada “For each row in the top (outer) input, scan the bottom (inner) input” yazar. Bu, SQL’in üstteki her bir satır için alttakini tek tek aradığını söyler.
Bu tablodaki en büyük “tehlike işareti” veya “başarı kriteri” şu iki satır arasındaki farktır:
- Actual Number of Rows: 290
- Estimated Number of Rows for All Executions: 275.573
SQL Server bu işlem sonucunda yaklaşık 275 bin satır gelmesini bekliyormuş (Estimated), ama aslında sadece 290 satır gelmiş (Actual). Arada devasa bir fark var. Bu, İstatistiklerin (Statistics) güncel olmadığını gösterir. SQL Server yanlış bir tahminle “yanlış bir plan” seçmiş olabilir.
Estimated Operator Cost %0 olduğunu görüyoruz. Bu join işleminin kendisi sistemi yormuyor. Eğer sorgun yavaşsa, asıl maliyet bu join’e veri getiren diğer operatörlerdedir (Index Scan veya Index Seek gibi adımları kontrol etmelisin).
Number of Executions: 1 değerini görüyoruz. Dış tablodan gelen satır sayısı az olduğunda (burada 290 satır oluşmuş), her bir satır için iç tabloda hızlıca “Seek” (arama) yapmak mantıklıdır. SQL Server bu yüzden bu yöntemi seçmiş.
Bu görseldeki en büyük problem Tahmin Hatasıdır (Estimation Skew). SQL 275 bin satır beklerken 290 satır bulmuş. İlgili tabloların istatistiklerini UPDATE STATISTICS [TabloAdi] ile güncellenmesi gerekmektedir. 2. Eğer bu fark düzelirse, SQL Server belki de Nested Loops yerine daha hızlı bir Merge Join veya Hash Join seçerek sorguyu daha da hızlandırabilir.
| Join Türü | Tercih Edilen Durum | Gereksinim | Bellek Kullanımı |
| Nested Loops | Küçük veri / İyi Index | İç tabloda Index | Çok Düşük |
| Merge Join | Büyük veri / Sıralı veri | Sıralı giriş (Index) | Düşük |
| Hash Join | Büyük veri / Indexsiz veri | Yok | Yüksek |
Bu makalede MSSQL Server Execution Plan’ Join Türleri ‘da görülen Nested Loops Join türünü detaylı bir şekilde görmüş olduk. Başka bir makalede görüşmek dileğiyle..
Kadir gecesi, bin aydan daha hayırlıdır. Kadir Suresi, 3. Ayet