
Bu makalede execution plan incelenirken nelere dikkat edilmesi gerektiğini ele almış olacağız. Önceki execution plan makalemizde Estimated ve Actual Execution kavramlarından bahsetmiştik. Bu plan yapılarını inceleyerek nasıl aksiyon almamız gerektiğinden bahsedelim.
Grafiksel Execution plan yapılarında okuma işlemi sağdan sola ve yukarıdan aşağıya doğru yapılmaktadır. Execution plan yapılarında karşılan bir başka ifade ilgili ikonun altında hangi tablo üzerinde hangi index yapısının kullanıldığı ve Cost bölümünde ilgili ifadenin sorguda maliyeti gösterilmektedir. Aşağıdaki ekran resminde Select ikonu üzerinde %0 yazması o işleme hiç zaman ayrılmadığı anlamına gelmemektedir. Sadece tüm zaman hesaplanıp iki ikona oranlandığında Select işlemi için sıfıra yakın bir değer çıktığı için değer sıfır olarak gösterilmektedir.
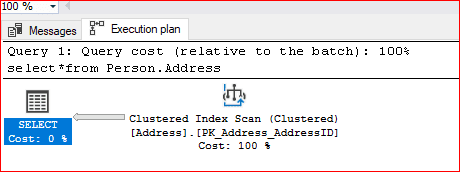
Yukarıdaki ifadede select ikonu en fazla karşılaşacağımız ikonlardan biri olarak karşımıza çıkmaktadır. Genellikle gözardı edilmesi gerekmektedir. Şimdi select ikonun Tooltip penceresini inceleyelim. İlgili ikon üzerine mouse ile gelindiğinde çıkmaktadır.

- Cached Plan Size: Execution planımız Cache’de ne kadar yer kaplayacağını belirtmektedir.
- Estimated Operator Cost: Daha önceden incelediğimiz ikonların üzerinde yazan ve bu işlemin toplam işlem içindeki yüzdelik maliyetini belirten değerdir.
- Estimated Subtree Cost: Select ifadesinden önceki adımlarda toplam harcadığı zamanı göstermektedir.
- Degree of Parallelism: Sorgumuzda paralelliğin dinamik olarak kullanıldığını söylemektedir. Manuel bir değer set edilmemiştir. Sorgunun maliyetine göre maxdop set edilir.
- Estimated Number of Rows for All Executions: Bu ifade istatistiklere bakarak 0 satır döneceği anlamına gelmektedir. Yukarıdaki sorgu çalıştığında satır gelmeyeceğini görmüş olacağız.
- Estimated Number of Rows: Bu operatörün çalışmasıyla kaç satırın etkilendiği veya kaç kayıt üzerinde işlem yapıldığını göstermektedir.
- Statment: Bu kısmında ise hangi sorguyu çalıştırmışsak o sorgu görülmektedir.
Select sorgusundan önceki Clustered Index Scan ikonunun üzerine gelip Tooltip penceresini inceleyelim.

Yukarıdaki resimlerde bulunan Tooltip pencerelerini farklı olması her sql server execution plan operatörünün kendine has verileri özetlemesidir.
Şimdi yukarıdaki Clustered Index Scan Tooltip penceresini inceleyelim.
- Physical Operation: Sorgu çalıştırıldığında yapılacak olan işlemi temsil eder. Diskte karşılığıdır. Actual Execution plan yapısını temsil etmektedir.
- Logical Operation: Sorgu çalıştırılmadan tahmin edilen işlemi göstermektedir. Sql motorunun algoritmasıdır. Estimated Execution plan yapısını temsil etmektedir.
Genellikle yukarıdaki iki ifade birbirine eşit çıkmaktadır.
- Execution Mode: Bu kısımda optimizer tarafından hangi execution modu kullanacağına karar verilir. Bunlar yukarıda belirtilen Actuel Execution Mode ve Estimated Execution Mode olmak üzeridir. Bu kavramların karşısında Row ve BatchMode ifadeleri yer almaktadır. Row mode, satır satır işlem gerçekleştirirken BatchMode belli bir gurup satır üzerinden işlem gerçekleştirir. Batch mode bazı işlemleri desteklemektedir(scan,filter, hash vb.). Query Optimizer eğer çok büyük veriler üzerinde gruplama, birleştirme gibi işlemler gerçekleştirecekse Batch Mode’u tercih eder(tabi columstore’a yönelik indexleriniz varsa) bunun dışındaki senaryolarda Row Mode’u tercih eder.
- Storage: İşlemin gerçekleşeceği storage(In-Memory) belirler RowStore veya ColumStore. Tabi bu yine execution mode’a göre belirlenmektedir. Row mode ise RowStore, batch mode ise ColumsStore üzerinde çalışacaktır.
- Actual Number of Rows Read: Okunan satır sayısını belirtmektedir.
- Actual Number of Rows/Batches: İlgili işlemin gerçekleşmesi için okunan satır/batch sayısı. Peki Estimated number of rows to be read ile Actual Number of rows read arasındaki farkı örnek üzerinden konuşursak daha net anlaşılır. İki farklı işlemimiz var bir tanesi index scan yapıyor koşulumuz ise Id ve Status bazlı olsun scan işleminde 1000 satır olan tabloda koşula uyanları bulması için 1000 satırı da okumak zorunda( estimated number of rows read) sonuç olarak ise bu 1000 satır içerisinden 300 satırı(actual number of rows) dönüyor. Bir diğer işlemimizde ise index seek yapıyor sorgumuzun parametrelerine göre indexlenmiş tabloda direk doğru kayıtları okuduğundan dolayı her iki değerde 300’ü göstermektedir.
- Estimated I/O Cost: Yapılan işlem için I/O maliyetini belirtmektedir.Bir sayfanın (8 KB) diskten okunması için gereken süreyi temsil eden bir puandır.
- Estimated Operator Cost: Yapılan işlem için harcanan toplam süreyi ve yüzdesini belirtmektedir.
- Estimated CPU Cost: Yapılan işlem için CPU maliyetini belirtmektedir. İşlemcinin bir satırı işlemek için harcadığı hesaplama gücünü temsil eden puandır.
- Estimated Subtree Cost: Bu, hiyerarşik bir toplamdır. Planın o noktasındaki operatörün kendi maliyeti + altındaki tüm çocuk (child) operatörlerin maliyetlerinin toplamıdır. Dikkat ederseniz okuma sağdan sola olduğu için Estimated Operator Cost ve Estimated Subtree Cost maliyetleri aynıdır.
- Actual Number of Rows: Sorgu sonucunda bu adımdan gerçekten geçen satır sayısı
- Estimated Number of Rows: SQL Server’ın istatistiklere bakarak tahmin ettiği satır sayısı. Gerçek rakamla (Actual) ne kadar yakınsa, performans o kadar sağlıklıdır.
- Estimated Row Size: Her bir kaydın kapladığı alanı göstermektedir.
- Number of Executions: Bu işlemin kaç kez tekrarlandığı (Döngüye girip girmediği).
- Actuel Rebinds: Dıştaki tablodan gelen her bir satır için, içteki tablodaki verinin “taze” bir şekilde tekrar çekilmesi gerektiğini gösterir.
- Actuel Rewinds: İçteki tablo için gereken verinin değişmediği, bu yüzden verinin bellekteki (cache) kopyasından tekrar okunduğu durumdur. SQL Server, “Ben bu veriyi az önce okumuştum ve parametreler değişmedi, o halde disk yerine hafızadan (spool) hızlıca tekrar okuyayım” der.
- Ordered: Veri kümesinin sıralı olup olmadığını göstermektedir. False değeri sıralı olmadığını göstermektedir. Eğer sorgumuzda order by ifadesini kullanmış olsaydık bu değer true olarak gösterilmiş olurdu.
- NodeID: Exection Plan yapılarında ilgili execution ikonunun seviyesini belirtmektedir. Numaralandırma yapılırken soldan sağa doğru yapılmasına karşılık, Execution planlar yorumlanırken sağdan sola doğru okuma yapılır.
- Object: Bu bölümde ilgili tooltip işlemi için hangi veritabanı tablosunu ve index kullanıldığını görebiliriz.
- Output List: İlgili operatörün sonucunda dönen sonuç kümesini göstermektedir.
Predicate, bir sorgunun WHERE, JOIN veya HAVING gibi filtreleme koşullarını ifade eder. Execution plan’da, veri satırlarının hangi kriterlere göre filtrelendiğini gösterir. Filtreleme İşlemi: Predicate, hangi satırların işleme alınacağını belirler. Predicate’lerin nasıl uygulandığı, sorgu performansını doğrudan etkiler. Predicate’lerin index’lerle uyumluluğu, index kullanım verimliliğini belirler. CONVERT_IMPLICIT ile dönüştürme işlemi yapılıyor. Daha sonra filtreleme işlemi olmaktadır. Bizim için kritik bir öneme sahiptir.

- Outer References

Görselde BusinessEntityID ve Expr1008 değerlerinin birer Outer Reference olduğunu görüyoruz. Bu, şu anlama gelir. SQL Server, her bir satır için dışarıdan gelen bu BusinessEntityID değerini alıyor ve “Git, bu ID’ye sahip olan kayıtları bul” diyor. Yani bu değer, operatörün içeriye bakarken kullandığı anahtar/parametre bilgisidir. Bir operatörün çalışması için dışarıdan (başka bir tablodan veya döngüden) beslendiği girdi değerleridir.
Expr1008 ifadesi, SQL Server’ın arka planda oluşturduğu geçici bir hesaplanmış değerdir (Expression). SQL Server sorguyu çalıştırırken bazen kolon isimlerini doğrudan kullanmak yerine onlara dahili takma isimler verir. “Expr” (Expression) ifadesi, bir hesaplama, veri tipi dönüşümü (Convert) veya bir sabit değerin bu operatöre aktarıldığını gösterir. Sorgumuzda WHERE BusinessEntityID = @Parametre veya bir JOIN işlemi varsa, SQL Server bu karşılaştırmayı yapabilmek için o değeri bir “ifade” (expression) olarak paketler.
- Residual

Görseldeki örneğe bakarsak; bir birleştirme (Join) işlemi yapılıyor. SQL Server muhtemelen CustomerID üzerinden bir eşleşme arıyor. Ancak bu eşleşen kayıtların içinden, sorgudaki diğer şartları sağlayanları ayıklamak için satırları tek tek kontrol etmesi gerekiyor.
- Ana Arama (Seek/Scan): Kapıyı açıp odaya girmek gibidir.
- Residual (Filtreleme): Odadaki eşyalar içinden sadece mavi olanları tek tek seçmek gibidir.
Kısacası İndeksle yapılan ana aramadan sonra, geri kalan şartları kontrol etmek için satır bazlı yapılan son ayıklama işlemidir.
- Hash Keys Probe

Hash Keys Probe, “Büyük tablodaki satırları, belleğe aldığım küçük tablodaki anahtarlarla (AddressID) karşılaştırıyorum” demektir.
- Build Residual

Build Residual, bir Hash Join operasyonu sırasında “Build” (belleğe alma) aşamasında uygulanan ek filtreleme veya doğrulama işlemidir.
Özetle Farklar:
- Residual: İndeks aramasından sonra yapılan son ayıklama.
- Probe Residual: Büyük tablo taranırken bellekteki liste ile karşılaştırma anındaki doğrulama.
- Build Residual: Küçük tablo belleğe “Hash Table” olarak yazılırken yapılan doğrulama veya filtreleme.
- Bitmap

Bu operatör, SQL Server’ın büyük veri kümelerinde daha hızlı filtreleme yapmak için geçici bir bitmap indeks oluşturduğunu gösterir. SQL Server, büyük bir tabloyu taramaya başlamadan önce, elindeki filtrelere veya birleştirme (join) şartlarına uyan kayıtların bir “haritasını” (evet/hayır listesi gibi) çıkarır. Bu harita çok küçük bir bellek alanı kaplar. SQL Server asıl büyük tabloya gitmeden önce bu Bitmap haritasına bakar. Eğer bir satırın haritadaki karşılığı “hayır” ise (yani birleşecek bir kaydı yoksa), o satırı daha en baştan okumaz. Veriyi çekip sonra elemeye çalışmak yerine, daha veriyi okurken “bu zaten işimize yaramayacak” diyerek pas geçer.
Büyük veriler arasında “iğne ararken”, daha işin başında “samanlığın yarısında iğne yok, oraya hiç bakma” diyen akıllı bir ön filtreleme yöntemidir. Diske erişimi ve CPU kullanımını ciddi oranda azaltır.
Tooltip penceresi sizin ihtiyaçlarınıza cevap vermiyorsa daha detaylı bir şekilde operatörün üzerine sağ tıklayıp Properties ekranından görebiliriz.
Şimdi Clustered Index Scan operatörünün üzerine sağ tıklayıp properties penceresinden inceleyelim.

Aşağıdaki ekran karşımıza çıkmaktadır.

Yukarıdaki ekran resminde Tooltip penceresinde olmayan Forced Index–ForceScan–Defined Values– NoExpandHint kavramları karşımıza çıkmaktadır.
Defined values: İşleme eklenecek olan bilgileri göstermektedir. Bir nevi Output List ifadesinin çıktısıdır. Sorgu sonucunda dönecek sonuç kümesini göstermektedir.

Forced Index: Sorgumuzu çalıştırması için herhangi bir indeksi kullanmaya zorlayıp zorlamadığımız bilgisini verir. Sql server doğru index yapısını seçemediği için kullanıcının sorgusunda manuel olarak index kullanımına zorlanması sağlanacaktır. Örnek vermek gerekirse aşağıdaki select sorgumuzda belirtilen index yapısını kullanmaya zorluyoruz.
select*from Person.Address with(index([PK_Address_AddressID]))
Yukarıdaki index yapısını sorgumuza zorladığımızda Forced Index değerinin true olduğunu görmüş oluyoruz.
NoExpandHint: Forced Index ifadesi ile benzer işleve sahip olup Indexed View’lar üzerinde kullanılmaktadır.
Output List kısmında sorgu sonucunda getirilecek kolunlar belirtilmektedir.

Grafiksel Execution plan yapısını yorumlayabilmek için öncelikle 80’yakın operatörün ne işe yaradığını bilmek gerekmektedir. İlerleyen makalelerimizde detaylı bir şekilde bu operatörleri görmüş olacağız.

Yukarıdaki ifademizde select ikonunun üzerindeki ünlem işaretine değinecek olursak. The query memory grant detected ‘ExcessiveGrant’, which may impact the reliability. Hatası ile karşılaşırız. Bu uyarının anlamı: SQL Server, sorgunun çalışması için bellek (Memory Grant) ayırıyor. Ancak burada sorguya normalden fazla bellek ayrıldığı ve bunun sistem performansını olumsuz etkileyebileceği belirtiliyor.
Detaylar:
• Memory Grant (İstenen): Initial 103032 KB
• Gerçek Kullanılan: Used 39004 KB
Bu, SQL Server’ın sorgu için yaklaşık 103 MB bellek ayırdığını, ama sadece ~39 MB’lık kısmını kullandığını gösteriyor. Bu duruma “Excessive Grant” deniyor çünkü:
• Gereksiz yere fazla bellek rezerve ediliyor.
• Bu durum yoğun sistemlerde başka sorguların yavaşlamasına veya sıraya girmesine sebep olabilir.
Bazen sorgularımızın execution planında CONVERT(VARCHAR(15), k.KLNADI, 0) ifadesinin sorgunun execution planını değiştirdiğini görürüz. Bu gibi durumlarda index eksikliği, sıralama işleminin büyük veri kümesi üzerinde yapılması veya select ifadesinde tüm verinin belleğe taşınması olabilir. k.KLNADI sütunu VARCHAR(15) tipine dönüştürülüyor. 0 parametresi varsayılan dönüşüm stilini belirtiyor. Herhangi bir önemi yok belirtilmese de olur. Bu yapılar index kullanımını engellemektedir. Tablonun taranmasına sebep olmaktadır.
Bazen sorgularımız bir temp tabloya açılır bu tablo üzerinde sıralama işlemi yapılmaktadır.
select * into #temp from [AdventureWorks2012].[dbo].[Table_1]
select*from #temp order by kolon1 descBaşka bir makalede görüşmek dileğiyle..
“Yavrucuğum, namazını özenle kıl, iyi olanı emret, kötü olana karşı koy, başına gelene sabret. İşte bunlar, kararlılık gerektiren işlerdendir.”Lokman-17