
Bu makalede Data Shrink işlemiyle mevcut verilerimiz default filegroup altında oluşturma işlemi ele almış olacağız. Konuya geçmeden önce shrink işleminin ne olduğuna değinmiş olalım. Veritabanımızı bazen data ve log dosyamızı shrink etme gibi bir sorunla karşılaşa biliriz. Çalışan bir veritabanında Data dosyaları shrink edilmesi önerilmez. Çünkü shrink edilince veritabanı performans anlamında büyük sıkıntılar yaşar. Shrink edilen data dosyalarındaki indexs fragmantation çok yüksek oranda artacaktır. Yapacağımız örnekte ise aynı filegroup altında bulunan iki data file arasında shrink işlemi yapmış olacağız. Log dosyası nasıl shrink edilir ve ne gibi senaryoların olduğunu öğrenmek için ilgili makaleyi okumalısınız.
Not: Ndf uzantılı filegroup shrink edildikten sonra silinebilir. Fakat mdf uzantılı filegroup sadece shrink edilebilir.
Not: Bir tablonun verilerinin birden fazla data file’a yazılabilmesi için, bu data file’ların tablonun bulunduğu aynı filegroup içinde yer alması gerekir.
Şimdi yapacağımız örnekte eski datalarımızın olduğu ilgili data file bulunan veriyi aynı filegroup üzerinde başka bir data file üzerinde shrink işlemini görmüş olacağız. Zaten empty file aynı filegrouplar arasında olmaktadır.
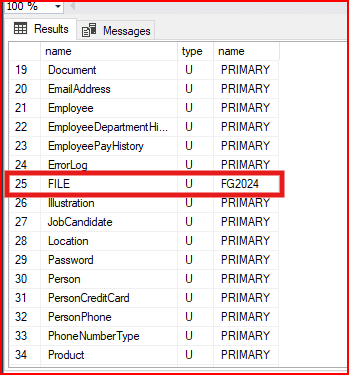
Aşağıdaki komut ile hangi tablonun hangi filegroup üzerinde olduğunu bulabiliriz. Partition tablolarında filegroup öğrenilmesi isteniyorsa makale sonundaki script çalıştırılır.
SELECT distinct o.[name], o.[type], f.[name] FROM sys.indexes i
INNER JOIN sys.filegroups f
ON i.data_space_id = f.data_space_id
INNER JOIN sys.all_objects o
ON i.[object_id] = o.[object_id]
AND o.type = 'U' -- User Created Tables
GOMakale içerisi resimler tam uyuşmazsada aynı filegroupta olmayan data file’lar arası geçiş yapılmıştır..
Veritabanı üzerine sağ tıklayarak Task>Shrink>Files kısmına girilir.

Gelen ekranda File Type kısmında Data ifadesini seçmemiz gerekiyor. Filegroup sekmesinde hangi filegroup’u shrink yapmak istiyorsak ilgili filegroup’u seçiyoruz. Primary olan filegroup’u seçtikten sonra devam ediyoruz.

- Location kısmında mevcutta olan dosyamızın nerde olduğuna dair bilgiler yazmaktadır.
- Currently Allocated Space kısmında data dosyamızın maksimum büyüklüğünü görebiliriz.
- Available free space kısımında data dosyasının ne oranında boş olduğu görünüyor.

Büyüme işlemi olmaması için ilgili file groupta bulunan data file aynı file grouptaki boş veritabanına yazmaktadır.
Shrink action kısmında 3 seçenek karşımıza çıkmaktadır.
- Release unused space kullanılmayan alanların tamamını işletim sistemine iade etmek ister. Büyük databaseler de bu yapı kullanılmaz çünkü kullanılmayan alan büyükse hemen işletim sistemine iade edemez.
- Release unused space seçeneğindeki sıkıntıdan dolayı ikinci seçenekte bulunan Reorganize pages before releasing unused space kısmı kullanarak kademeli kademeli disk alanını işletim sistemine iade etmek gerekir. Başlangıç olarak default olarak mevcut boyut gelmektedir. Burada değer hangi değere düşürmek istiyorsak o değer mb cinsinden girilmelidir.
Son seçenekte bulunan Empty file by migrating the data to other files in the same filegorup ise veritabanı altında bulunan aynı filegroup’da ikinci bir data dosyası oluşturduktan sonra ikinci data dosyasını shrink edip eski data dosyasının üzerine yazıp daha sonra data dosyamızı silebiliriz.
Not: .mdf uzantılı data dosyalarını silemeyiz. Sadece .ndf uzantılı data dosyalarını silebiliriz.
Ben örneğimde Primary filegroup altında bulunan datayı Primary filegroup altına atacağım için 3. seçenek olan Empty file by migrating the data to other files in the same filegorup’u işaretliyorum.
Files sekmesinden önce data dosyamı normal bir şekilde shrink edip boş alanları işletim sistemine iade ettikten sonra Empty file by işlemi gerçekleştirip aynı filegroup’a verilerimi atıyorum. filegroup derken ilgili data file aslında..
Yukarıdaki işlemler yapılmadan önce aşağıdaki işlemler sırasıyla yapılabilir. En sonda shrink işlemi yapılabilir.
1. Tabloyu Belirtilen Data File Taşı
Eğer Data file üzerinde bulunan tablonun clustered index’i varsa, aynı filegroup üzerinde bulunan data file’a yeniden oluşturarak tabloyu taşıyabiliriz. Clustered index ise çünkü tablonun kendisidir. Non clustered indexlerde sadece ilgili index gitmektedir.
A. Clustered Index varsa:
Clustered index varsa yeniden oluştur. (taşıma işlemi yapar)
CREATE CLUSTERED INDEX IX_FILE_CL
ON dbo.FILE(ID) -- uygun bir kolon belirt
WITH (DROP_EXISTING = ON)
ON [PRIMARY];Bu işlem, tabloyu ve tüm verisini data file’lara taşıyacaktır.
B. Clustered Index yoksa (HEAP ise):
- Yeni bir tablo oluşturularak mevcut data file’a yazma işlemi yapılmaktadır. Mevcutta bulunan veritabanındaki tablo yeni data file üzerinde oluşturulur.
SELECT * INTO FILE_TEMP FROM dbo.FILE;- Eski tabloyu sil, yeniden adlandır:
DROP TABLE dbo.FILE;
EXEC sp_rename 'FILE_TEMP', 'FILE';Not: Bu işlemde constraints, triggers, indexes vs. tekrar oluşturulmalıdır. Otomatik taşıma sağlamaz.
3. Shrink Empty File
Tablonun taşınmasıyla birlikte, ilgili filegroup altında artık veri kalmadıysa veya boşaltılan data file’da boş alandan dolayı veri yazılabilir. Böyle durumlar karşılaşılırsa boşalan data file shrink işlemi yapılıp kalınan yerden devam edilmesi gerekmektedir.
Shrink işlemi
DBCC SHRINKFILE (N'YourDataFileName.ndf', EMPTYFILE);4. Dosya tamamen boşaltıldıysa artık sistemden kaldırılabilir:
ALTER DATABASE MyDatabase
REMOVE FILE YourDataFileName;Önemli Notlar:
- Filegroup’lar doğrudan silinemez, ama içlerindeki tüm veriler taşındıysa dosyalar silinebilir.
- Clustered index taşıma işlemi hem tabloyu hem veriyi taşır. Bu sebepten büyük tablolar yeni tablolara taşınmak isteniyorsa bu yöntem ile yapılabilir.
- Nonclustered index’ler, LOB veriler (nvarchar(max), text, image vs.) başka filegroup’ta olabilir; ayrıca kontrol edilmeli.
Not: Aşağıdaki komut ile veritabanı altında bulunan partition tablo ve partition sız tabloları getirmektedir. Aynı zamanda tüm tabloların filegroupları görülmektedir.
SELECT
SCHEMA_NAME(t.schema_id) AS [Schema],
t.name AS [Table Name],
CASE
WHEN ps.data_space_id IS NOT NULL THEN 'YES'
ELSE 'NO'
END AS [Is Partitioned],
ISNULL(ps.name, 'N/A') AS [Partition Scheme],
ISNULL(pf.name, 'N/A') AS [Partition Function],
-- Filegroup bilgisi (partition olmayanlar için)
CASE
WHEN ps.data_space_id IS NULL THEN fg.name
ELSE 'See Partition Details Below'
END AS [Filegroup (Non-Partitioned)],
-- Partition detayları (partition olanlar için)
p.partition_number AS [Partition Number],
pfg.name AS [Partition Filegroup],
p.rows AS [Rows in Partition],
prv.value AS [Partition Boundary Value]
FROM sys.tables t
INNER JOIN sys.indexes i ON t.object_id = i.object_id AND i.index_id IN (0, 1) -- Heap or Clustered Index
INNER JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id
LEFT JOIN sys.partition_schemes ps ON ds.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON ps.function_id = pf.function_id
LEFT JOIN sys.filegroups fg ON ds.data_space_id = fg.data_space_id AND ps.data_space_id IS NULL
LEFT JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id
LEFT JOIN sys.destination_data_spaces dds ON ps.data_space_id = dds.partition_scheme_id AND p.partition_number = dds.destination_id
LEFT JOIN sys.filegroups pfg ON dds.data_space_id = pfg.data_space_id
LEFT JOIN sys.partition_range_values prv ON pf.function_id = prv.function_id
AND p.partition_number = CASE pf.boundary_value_on_right
WHEN 1 THEN prv.boundary_id + 1
ELSE prv.boundary_id
END
WHERE t.is_ms_shipped = 0 -- Only user-created tables
ORDER BY [Schema], [Table Name], [Partition Number];

Bu makalede verinin yeni file group’a nasıl taşındığını ve data shrink olayını görmüş olduk.
NOT: Data dosyası shrink edildikten sonra fragmentation değerini artacağını yukarıda belirtmiştik. Shrink işlemi yapıldıktan sonra rebuild ve reorganize yapılması gerekmektedir. 2. bir yöntem ise tablo filegroup belirlendikten sonra shrink yapılacak Filegroup altında yeni bir data dile oluşturulup empty file shrink yapılması gerekmektedir. Daha sonra diğer data file boyutu sıfırlandıktan sonra silinebilir.
Not: EMPTYFILE ile shrink edilen data file’daki veriler, aynı filegroup içindeki diğer data file’lara yazılır ve hangi data file’a yazılacağı garanti edilmez.
Not: Empty file shrink yaplıması log dosyasında şişmeye sebep vermemektedir.
Not: Aynı Filegroup altında bulunan data file’lar Empty işlemine tabi tutulmaktadır.
Başka bir makalede görüşmek dileğiyle..
“Sonra geceyi ve gündüzü, güneşi ve ayı sizin hizmetinize O verdi. Bütün yıldızlar da O’nun emrine boyun eğmişlerdir. Gerçekten bunda aklını kullanan bir toplum için nice ibretler, dersler vardır.” Nahl-12
1 thought on “MSSQL Server Data File Shrink Yöntemi– Empty File Shrink”