
Bu makalede filegroup yapısının ne olduğunu ne gibi ayarlar yapıldığını ele almış olacağız. Filegroup temel anlamda veritabanı nesnelerini ve dosyalarını guruplamak için kullanılmaktadır. İşletim sisteminden alan tahsis etmek, yönetimi kolaylaştırmak ve data file’ları gruplamak için kullanılmaktadır. Bir veritabanı oluşturulurken primary filegroup altında oluşur. Tüm veriler tek mdf file üzerinde olduğu için zamanla I/O beklemesi artar. Primary Data File default file group olan PRIMARY File Group içerisinde yer alır. Bütün sistem tabloları da PRIMARY file group altındadır.
Not: Primary Data File yapısında veritabanı başlangıç bilgisi diğer file’lara ait bilgiler tutulur. Secondary Data File tanımlamazsak bütün veri Primary Data File içerisinde büyümektedir.
Not: Primary data file maksimum 16 TB kadar boyutu olmaktadır. Her veritabanında sadece 1 tane .mdf file yani primary data file bulunur. Kullanmış olduğum Dosya sistemine göre bu yapı değişebilir.
Yeni bir filegroup oluşturmazsak oluşturacağımız secondary data file’lar primary filegroup üzerinde büyür. Bu da bir veritabanı yöneticisinin istemediği bir durumdur. Çünkü bakım ve performans anlamında ileryen aşamalarda sıkıntıya sebebiyet verecektir. Veritabanımızın tek mdf file üzerinde büyümesi yerine mevcut veritabanı büyüklüğümüze göre yeni filegrouplar oluşturup bu filegrouplara bağlı data file’lar oluşturarak veritabanımızı daha performanslı hala getirebiliriz. Mevcut disk yapımıza göre data file’lar oluşturulur. Bu şekilde mevcut olan tablolarımızı filegrouplara aktararak tablomuzu disklere eşit bir şekilde yayabiliriz. mdf uzantılı data dosyasının dışında başka bir data file tanımlarsanız uzantısı ndf olacaktır. Bu yapı Secondary Data File olarak geçmektedir. Şuda unutulmamalı aynı file group altında birden fazla ndf dosyasının olması verilerimizin rastgele yazılmasını sağlayacaktır.
Not:MDF ve NDF dosyaları Veri Dosyaları Rastgele erişimlidir. Veritabanı veri dosyalarına (MDF/primary, NDF/secondary) veri yazarken, SQL Server genellikle sayfa (page) bazlı çalışır ve ihtiyaç duyduğu veri sayfalarını bellekten veya diskteki çeşitli adreslerden okur/yazar. Bu işlemler sıklıkla rastgele (random I/O) olduğundan, özellikle klasik disklerde yavaştır. SSD kullanan sistemlerde bu fark azalsa da, veri dosyalarına erişim hâlâ daha karmaşıktır.LDF dosyası yani Transaction Log Dosyasında ise Sıralı (sequential I/O) yapıda çalışır. Tüm işlemler (INSERT, UPDATE, DELETE) önce log dosyasına yazılır ve bu işlem diskte sıralı olarak yapılır.Bu yüzden LDF’ye veri yazmak genellikle çok daha hızlıdır.
Sql serverda veritabanı altında oluşturulan data file’ların herhangi bir önceliği bulunmamaktadır. Random yazılmaktadır. Kısacası verilerin veritabanı üzerinde bulunan data file’lara yazılması rastgele olmaktadır. Herhangi bir önceliği yoktur. Random yazılmaktadır. Filegroup mantığı ise bakım işlemlerini daha rahat oluşturmak için vardır. Eğer filegroup altında aynı disk veya farklı disk farketmeksizin oluşturulan data file’lar bizim sadece aynı disk altında veya farklı disk altında okunup yazıldığı zaman avantajları ve dezavantajları vardır. Filegroup ise tamamen bu yapıdan farklıdır. Filegroup işleminin avantajları dbcc check işlemleri filegroup bazında yapılabilmektedir. Backup işlemleri yine filegroup bazında gerçekleşmektedir. Büyük tabloları filegroup bazında partition yapılmaktadır. Yönetimsel anlamında bize faydaları olduğu için kullanılır. Primary file group altında farklı disklerde data file larda aynı yapıya gelmektedir. Ama bakım işlemleri genel olarak tek bir filegroup üzerinden yapılır.
Not: SQL Server’da her bir data file (MDF/NDF) kendi içerisinde File Header Page, PFS (Page Free Space), GAM (Global Allocation Map), SGAM (Shared Global Allocation Map), IAM (Index Allocation Map), Differential Change Map ve Bulk Changed Map gibi sistem sayfalarını barındırır. Buffer Pool üzerinde bulunan data page’ler üzerinde herhangi bir INSERT, UPDATE veya DELETE işlemi yapıldığında, bu işlemlere bağlı olarak sayfa ve extent tahsis bilgileri değiştiği için ilgili data file içerisinde bulunan PFS, GAM ve SGAM sayfalarının da güncellenmesi gerekir. Bu durum, özellikle yoğun insert işlemlerinin olduğu senaryolarda aynı allocation sayfalarına eş zamanlı erişim nedeniyle çekişmelere (contention) sebep olur. Bu çekişmeler genellikle PAGELATCH_UP veya PAGELATCH_EX beklemeleri olarak görülür ve hata veya bekleme mesajlarında veritabanı ismi yer alıyorsa, problemin ilgili veritabanındaki allocation yapılarından kaynaklandığı anlaşılır. Her ne kadar bu durum insert işlemlerinin başarısız olmasına sebep olmasa da, allocation sayfaları üzerindeki çekişme nedeniyle insert işlemlerinde beklemeler oluşur. Bu sebeple, yüksek eş zamanlı veri ekleme yapılan sistemlerde veritabanının tek bir data file üzerinde büyümesi önerilmez; birden fazla data file kullanılarak allocation yükü dağıtılmalı ve çekişmelerin önüne geçilmelidir. PFS / GAM / SGAM / IAM / DCM / BCM her data file’ın kendi içinde vardır. Bu yüzden çekişme (contention) file bazlıdır, database bazlı değil. DCM ve BCM → insert sırasında değil, backup ve bulk operation senaryolarında daha aktiftir Insert contention’ın asıl suçluları: PFS + GAM + SGAM
Not: “SQL Server’da veri önce log (LDF) dosyasına yazılır. Bu veriler MDF dosyasına daha sonra yazılır.
Eğer Full Recovery Model kullanılıyorsa ve düzenli log backup alınmazsa, log dosyası büyür.
Bu da disk alanını tüketebilir ve sistem yavaşlayabilir.
Ancak backup işlemleri sırasında MDF ve LDF birlikte okunur, bu dosyalar kullanılabilir durumdadır.”
Büyük veritabanlarımızda tüm verinin aynı filegroup üzerinde olması backup anlamında sıkıntı yaşamamıza sebep olacaktır. Veritabanımızı filegrouplara bölerek filegroup bazında backup işlemlerimizi gerçekleştirebiliriz. Filegroup aslında bize yönetim kolaylığı sağlar. Karmaşıklığı önler.
Büyük veritabanlarında datanın ve sistem objelerinin aynı filegroup ve data file üzerinde olması sıkıntı yaratacak bir durumdur.
- “Data” → Uygulama verileri (tablolar, indeksler, transaction’lar)
- “Sistem objeleri” → Stored procedure’ler, view’lar, trigger’lar, fonksiyonlar vb.
(Yani: SQL kodu, sorgular, tanımlar)
Bu iki şey aynı veritabanında olduğunda, bazı sorunlar ortaya çıkabilir. özellikle büyük ve yoğun veritabanlarında.
Büyük veritabanlarında her şeyi tek bir yapıya yığmak izolasyon, yönetim, performans ve güvenlik açısından risklidir.
Not: İndexlerin ayrı bir filegroup ve data file üzerinde olması tavsiye edilir. Sadece indexs yapılarımız için farklı bir filegroup oluşturulabilir. Bu durum indexslerimizin daha performanslı çalışmasını sağlamaktadır. File group bazlı bakım çalışmasını kolaylaştırır.
- Eğer tüm filegroup’lar aynı fiziksel disk üzerindeyse → hiçbir fark yaratmaz.
- Çünkü SQL Server diske yazarken yine aynı fiziksel I/O kanalını kullanır.
- Sadece mantıksal bir ayrım yapmış olursun, performans değişmez.
Index’ler ayrı filegroup’ta olmalı ifadesi tek başına yeterli değildir. Gerçek fayda için o filegroup’un farklı bir diske (veya I/O path’e) yönlendirilmiş olması gerekir. İki farklı file groupun aynı diski kullanması iki farklı gurubun aynı kasiyer üzerinden işlem yapması gibidir. Hız açısından herhangi bir kolaylık sağlamaz.
Veritabanımızın başlangıç boyutu büyükse farklı bir filegroup oluşturup veritabanımızın default olan yeni filegroupda büyümesi tavsiye edilir.
SQL Server’da büyük bir tabloyu tek bir filegroup içinde, birden fazla data file kullanarak saklayabiliriz. Bu sistem zamanla verinin düzensiz dağılmasına yol açabilir. Ne demek bu? Hemen açıklayalım:
Başlangıçta ne olur?
- Tablonuz küçükken, veriler sadece ilk oluşturulan data file üzerine yazılır.
- Ancak zamanla tablo büyüdükçe, SQL Server yeni verileri yeni eklenen diğer data file’lara da yazmaya başlar.
Sorun nerede başlıyor?
- Veri eşit dağılmayabilir. İlk baştaki data file büyük olurken, sonradan eklenenlerde daha az veri olabilir.
- Bu durum tabloda verilerin dengesiz yerleşmesine neden olur.
Peki, indeks rebuild ne yapar?
- Clustered index rebuild işlemi sırasında SQL Server, veriyi yeniden düzenler.
- SQL Server önce hangi data file’ların kullanılacağını belirler.
- Bu kararı verirken her data file’ın boyutuna ve boş alanına bakar.
Sonuç ne olur?
- SQL Server, en boş olan data file’a yeni verileri yazmayı tercih eder.
- Bu da veri dağılımının daha da dengesizleşmesine neden olur.
- Zamanla bazı data file’lar çok dolarken, bazıları boş kalabilir.
- Bu durum, disk üzerinde beklemelere (I/O yavaşlaması) ve performans sorunlarına yol açar.
Özetle:
Verinin eşit dağılmaması, index rebuild işlemlerinde SQL Server’ın veriyi hep en boş alana yazmasına neden olur. Bu da bazı dosyaların dolup bazı dosyaların boş kalmasına sebep olur. Sonuç olarak disk kullanımı dengesizleşir ve performans sorunları yaşanabilir.
Aynı filegroup içinde birden fazla data file varsa, bir büyük tablonun verisi bu dosyalar arasında parça parça dağılabilir. Bu performans açısından sorunlara neden olabilir.
Şimdi bunu anlaşılır şekilde açıklayalım:
- Diyelim ki UserDataFG adlı bir filegroup’ta 3 adet .ndf data file var:
- data1.ndf, data2.ndf, data3.ndf
- Bu filegroup’a bir büyük tablo (örneğin Orders) atanmış.
- SQL Server, bu tabloyu oluştururken hangi data file’a ne kadar veri yazılacağını kendisi belirler. Bu yapı sadece bir tablo olarak değilde veritabanı seviyesinde de aynı yapıda oluşmaktadır.
ÖZETLE aynı filegroup altında bulunan birden fazla data file’a ilgili filegroup altında oluşturulan nesnenin veya nesnelerin içindeki veriler data file’lara rastgele yazılmaktadır. Bu yapı bizlere performans anlamında sıkıntı oluşturacaktır.
Şimdi Potansiyel Sorunlara:
1. Fragmentation
- Tablo verisi farklı fiziksel dosyalarda yer aldığında, veri süreksiz olur.
- Bu da I/O sırasında diskin daha fazla çalışmasına ve yavaşlamaya neden olabilir.
2. Disk Bazlı I/O Beklemeleri
- Data file’lar farklı disklerdeyse ve bu disklerin performansları farklıysa, SQL Server en yavaş olan diskin hızına göre performansı sınırlar.
3. Index Rebuild ve Page Movement
- Index rebuild gibi işlemler sırasında SQL Server veri sayfalarını yeniden düzenlemeye çalışır.
- Bu işlem, verilerin hangi file’a yazıldığını ve boşluk durumunu kontrol ederek yapılır.
- Sonuç: Veriler eşit dağılmaz, bazı dosyalar dolarken bazıları boş kalabilir.
- Zamanla bazı data file’lar tıkanabilir, I/O queue artar ve performans düşer.
Performans Açısından Ne Yapmalı?
| Tavsiye | Açıklama |
|---|---|
| Data file’lar aynı boyutta ve aynı büyüme oranında olmalı | SQL Server veriyi daha dengeli dağıtır. |
| Mümkünse aynı performans seviyesinde diskler kullanılmalı | Farklı disk hızları I/O dengesizliği yaratır. |
| IO ve file-level monitoring yapılmalı | Hangi file daha fazla yük altındaysa izlenmeli. |
| Çok fazla data file eklenmemeli (genelde 1-4 arası yeterli) | Gereksiz karmaşıklık yaratabilir. |
Sonuç olarak aynı filegroup içindeki birden fazla data file, veri dengesiz dağılırsa veya yanlış konumlandırılırsa performans kaybına neden olabilir. Özellikle büyük tablolarda, veri parçalara bölünerek farklı dosyalarda tutulursa bu, I/O yavaşlamaları ve index rebuild sırasında gecikmelere yol açabilir.
Veritabanımız altında yeni bir filegroup ve data file oluşturma işlemine geçelim.
Veritabanımızın üzerine sağ tıklanıp properties denilir. Gelen ekranda filegroups sekmesine gelinir.
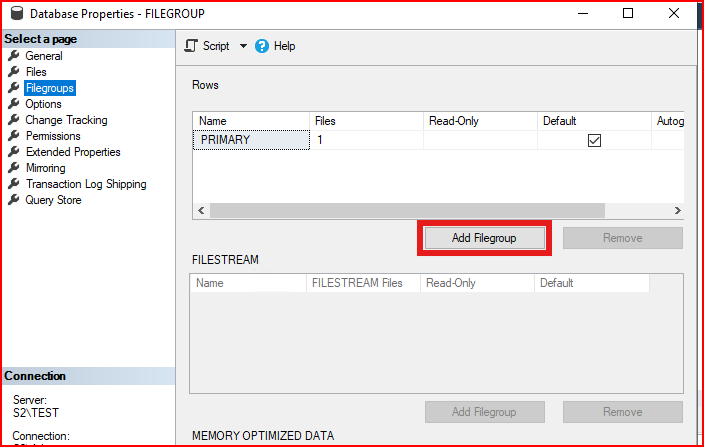
Add Filegroup butonuna tıklanır. FG2024 adında bir filegroup oluşturulur.
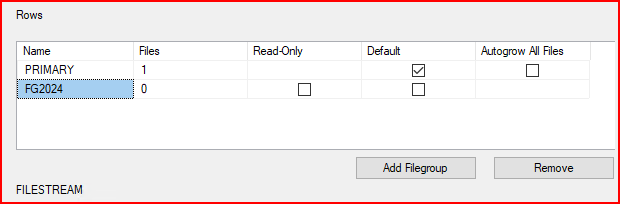
Yukarıdaki ekranda Files sekmesi ilgili filegroup altındaki dosya sayısını gösteriyor. Primary .mdf dosyası var ama yeni oluşturduğum. FG2024’e herhangi bir data file tanımlamadım.
Read-Only bu seçenek işaretlenirse ilgili filegroupdaki sadece okunabilir olur ve herhangi bir işlem yapılamaz. Herhangi bir filegroup Default olarak işaretlenmişse, yeni oluşturulan veritabanı nesneleri tablo vs. default olan file group’a eklenir. Data file sekmesinde yeni bir ndf file oluşturacağımız zaman file group sekmesi yukarıdaki resimde hangisi default ayardaysa o gelmektedir.
SQL Server’da “Autogrow All Files” seçeneği (checkbox), veritabanı filegroup’ları için önemli bir ayardır. Bu seçenek, filegroup içinde birden fazla data file varsa, hangi dosyanın ne zaman ve nasıl büyüyeceğini kontrol eder.
Seçiliyse → Filegroup’taki tüm data file’lar eşzamanlı olarak büyür.
Seçili değilse → Sadece ihtiyaç duyulan tek bir data file büyür (default SQL Server davranışı).
Varsayalım:
- UserDataFG adlı filegroup içinde 3 data file var:
data1.ndf, data2.ndf, data3.ndf - Her biri 100 MB başlangıç boyutunda ve 50 MB autogrow ayarı var.
Eğer Autogrow All Files işaretliyse:
- Bir dosya dolduğunda, üçü birden 50 MB büyür → Hepsi olur 150 MB.
Eğer Autogrow All Files işaretli değilse:
- Sadece dolan dosya büyür → Diğerleri sabit kalır → Veri dengesizliği olur.
Büyük veritabanı ve yüksek I/O varsa açılması önerilir. Tek data file olması hiç bir etkiye sebep olmaz. Farklı disklerdeyse data file’lar ve disk performans eşir değilse problem yaratabilemktedir.
Bu açıklamalardan sonra ilgili ekranın sol kısmında Files sekmesi altında Data file ekleme işlemi yapılır.
Not: Veritabanı default olarak iki dosya yapısına sahiptir. Bunlar mdf uzantılı data dosyası ve ldf uzantılı transaction log dosyasıdır.
Files sekmesine tıkladıktan sonra gelen ekranda yeni bir data file eklemek için alt kısımda bulunan Add kısmına tıklanır.
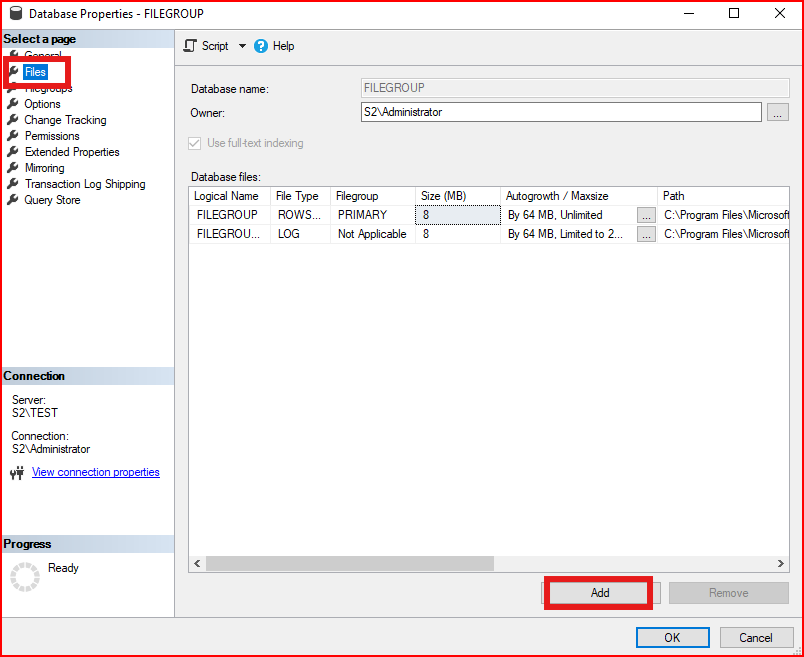
Data file oluşturmadan önce filegroup kısmında default olarak primary geleceğini yukarıda açıklamıştık.
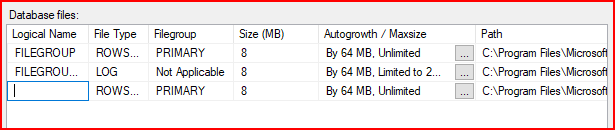
Oluşturacağım data file’a yeni oluşturmuş olduğum FG2024 filegroup’u seçiyorum.
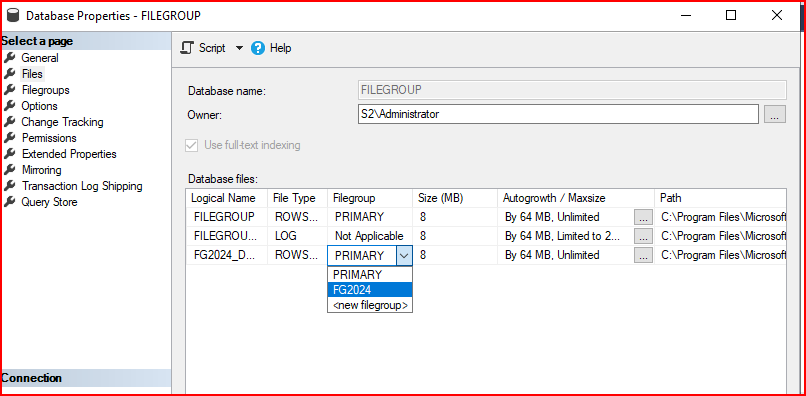
Not: Genellikle veritabanı boyutu 1 TB üzeri olan veritabanlarında IO performans sıkıntısı yaşacağımız için performans anlamında yeni file eklenir. Bu eklenen File’ın primary file group altında büyümektense yeni oluşturulacak file group üzerinde büyümesi tercih edilir. Çünkü yönetilebilirlik açısından bizlere daha iyi katkı sunar.
Path kısmında yeni oluşturduğum file group için yeni bir disk yolu belirtiyorum. Elimde C diskinden başka bir diskim olmadığı için bu şekilde bırakıyorum.

Şimdi yukarıdaki kavramların ne işe yaradığını açıklayalım.
- Logical Name: Bu sütun, dosyanın mantıksal adını gösterir.
- FILEGROUP: Bu, PRIMARY filegroup içinde yer alan veri dosyasını temsil eder.
- FILEGROUP_log: Bu, log dosyasını temsil eder.
- FG2024_DATA: Yeni oluşturulmuş olan FG2024 filegroup’una bağlı veri dosyasıdır.
File Type:
- ROWS : Bu tür, veritabanı içindeki veri satırlarını içeren dosyaları temsil eder.
- LOG: Bu tür ise veritabanı işlem günlüklerini (transaction log) içeren dosyaları ifade eder.
Filegroup: Dosyanın hangi filegroup’a ait olduğunu gösterir.
- PRIMARY: Veritabanının varsayılan filegroup’udur.
- Not Applicable: Log dosyaları, filegroup’a ait değildir.
- FG2024: Bu, yeni oluşturulan FG2024 filegroup’una bağlı bir dosyadır.
Size: Dosyanın şu anki boyutunu gösterir. Görüntüde her dosya için 8 MB başlangıç boyutu atanmış. Başlangıç olarak insert işlemlerinde sıkıntı yaşamamak için bu değer yükseltilebilir. İlerleyen aşamalarda size bölümünde ilgili dosyanın büyüklüğünü görebiliriz. Genelde data file için 512, log file için 1024 MB olarak belirlenebilir.
Not: Initial size, autogrowth değerleri bizim model veritabanımızı baz alarak gelmektedir.
Not: Bir tablonun verilerinin birden fazla data file’a yazılabilmesi için, bu data file’ların tablonun bulunduğu aynı filegroup içinde yer alması gerekir.
Autogrowth/Maxsize: Dosyaların otomatik olarak ne kadar büyüyeceğini ve maksimum ne kadar büyüyebileceğini ayarlar.
Örneğin, burada dosyalar 64 MB’lik artışlarla otomatik olarak büyüyecek şekilde ayarlanmış, ve bazıları için maksimum boyut Unlimited (sınırsız) olarak belirlenmiş.
Path: Dosyanın saklandığı dizini gösterir. Örnekte tüm dosyalar SQL Server’ın varsayılan veritabanı dizininde saklanıyor. Bu ekran, SQL Server veritabanı yönetiminde dosya yapılandırmalarını görselleştirmek ve düzenlemek için kullanılır.
File Name: Manuel olarak isim belirlenmekle birlikte default olarak logical name ile birlikte gelmektedir. Primary haricinde oluşturulan tüm data file’ların uzantısı .ndf olarak gelmektedir.
Not: Veritabanların aynı anda sadece 1 tane log dosyasına yazacağı için log dosyasının bulunduğu disk’in hızlı olması açısından diğer data file disklerinden ayrı bir disk ve Raid yapılandırması yapılabilir. Sorgularımızın bekleme tipi Write Log ise log dosyalarımızın olduğu disk’in yavaş çalıştığı anlamına gelmektedir.
Not: Bir data file, yalnızca ait olduğu filegroup tarafından kullanılır. Bir filegroup’a eklenmeyen data file, SQL Server tarafından veri yazımı için kullanılamaz.
Yukarıdaki açıklamalardan sonra Script’i alınarak işlem komut sırasıyla çalıştırılır. Filegroup ve data file oluşturulmuş olur.
USE [master]
GO
ALTER DATABASE [FILEGROUP] ADD FILEGROUP [FG2024]
GO
ALTER DATABASE [FILEGROUP] ADD FILE ( NAME = N'FG2024_Data', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.TEST\MSSQL\DATA\FG2024_Data.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [FG2024]
GO
Not: Gerçek sistem üzerinden karşılaşılan bir soruna değinmek istiyorum. Aşağıdaki ekran resmi üzerinden açıklamalarımızı yapalım.

Yukarıda görülen her iki veri dosyası aynı filegroup’ta (PRIMARY) yer alıyor ve bunların boyutları oldukça büyük: 1. dosya: 16 TB’e yakın (16.7 TB) • 2. dosya: 2.1 TB Autogrowth ayarı, sınırsız büyüme olarak ayarlanmış. PRIMARY filegroup sınırı 16 TB olduğundan, bu dosya yapısı 16 TB sınırına yaklaştığında veya aşıldığında sorun çıkacaktır. Bu nedenle yeni bir filegroup veya data file eklenmeden aynı PRIMARY filegroup üzerinde büyümeye devam etmek hatalı bir tasarım yaklaşımıdır. Bunun için ya veritabanı altında yeni bir filegroup ve data file eklenmeli yada primary filegroup altında yeni bir data file eklenmesi gerekmektedir. Bu yapı ile makalenin başında da belirttiğimiz gibi verilerimiz dağınık bir şekilde olacaktır. İkinci bir filegroup gereği duymamız yönetim ve bakım işlemlerinde kolaylık sağlamasıdır.
PRIMARY filegroup’un toplam kapasite mdf data file sınırı 16 TB‘dir. Aynı filegroup altında ikinci bir secondary data file oluşturmamız sorunumuzun giderilmesine sağlayacaktır.
NOT: Tek bir data dizini üzerinde bulunan veritabanını birden fazla data file üzerine bölmek için drop existing on parametresi ile indexler yeniden oluşturulur. Burada önceki data file’ı tamamen bitirecek yöntem yeni oluşturacağım data file yeni oluşturulacak file group üzerinde olacak. İndex oluşturacağım zaman drop existing sonuna on filegroup name yazılacak artık index o file groups üzerinde olmuş olacak bu sayede filegroup’un tanımlandığı data file’a yazılacaktır.
Bu makalede FileGroup ve Data File konusunu ele almış olduk. Bir sonraki makalede görüşmek dileğiyle..
“Onlar her türlü boş söz ve faydasız işlerden yüz çevirirler.” Mü’minûn- 3
1 thought on “MSSQL Server FileGroup and Data File”