
Bu makalede AlwaysOn yapısısında failover veya Switch Over durumlarında Availability Group altındaki databaselerin senkronizyon durumlarını aşağıdaki komut yardımıyla gözlemleyebiliriz.
Bu kod bloğunu kullanmayıp AG üzerine gelip sağ tıklayarak Show Dashboard ekranından senkronizasyon durumlarını gözlemleyebiliriz. Show Dashboard ekranından aşağıdaki komutu çalıştırdığımızda senkron gözükmesine rağmen senkron olmayabilir. Bunun için Show Dashboard ekranından Last Hardened Time, Last Redone Time, Last Commit time, Log Send Queue Size, Redo Queue Size gibi parametrelere bakılması lazım.
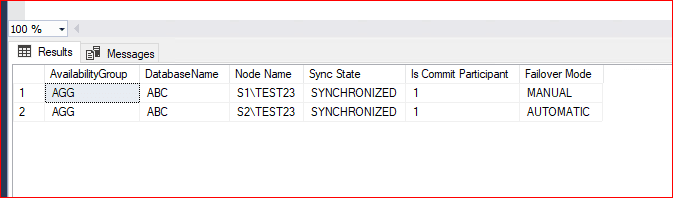
Aşağıdaki komut ile AG altında bulunan veritabanını ve diğer Nodelarda durumunu gösteren komut verilmiştir.
SELECT
ag.name AS [AvailabilityGroup],
d.name AS [DatabaseName],
ar.replica_server_name AS [Node Name],
drs.synchronization_state_desc AS [Sync State],
drs.is_commit_participant AS [Is Commit Participant],
ar.failover_mode_desc AS [Failover Mode]
FROM sys.dm_hadr_database_replica_states drs
JOIN sys.availability_groups ag ON drs.group_id = ag.group_id
JOIN sys.availability_replicas ar ON drs.replica_id = ar.replica_id
JOIN sys.databases d ON drs.database_id = d.database_id
ORDER BY d.name, ag.name, ar.replica_server_name;Bu sorguda synchronization state desc = SYNCHRONIZED olmalıdır. Eğer “SYNCHRONIZING” veya farklı bir durumda ise failover öncesinde bu problemi çözmelisiniz.
Aşağıdaki komut secondary sunucularında log send queue_size ve redo queue size değerini görebiliriz.
SELECT
ag.name AS [AvailabilityGroup],
d.name AS [DatabaseName],
ar.replica_server_name AS [Node Name],
drs.synchronization_state_desc AS [Sync State],
drs.is_commit_participant AS [Is Commit Participant],
ar.failover_mode_desc AS [Failover Mode],
drs.log_send_queue_size AS [Log Send Queue Size],
drs.redo_queue_size AS [Redo Queue Size],
drs.synchronization_health_desc AS [Health State]
FROM sys.dm_hadr_database_replica_states drs
JOIN sys.availability_groups ag ON drs.group_id = ag.group_id
JOIN sys.availability_replicas ar ON drs.replica_id = ar.replica_id
JOIN sys.databases d ON drs.database_id = d.database_id
ORDER BY d.name, ag.name, ar.replica_server_name;
Not: Failover sırasında veri kaybını kesinlikle önlemek için full backup ve transaction log backup almalısın.
Planlı bir failover işlemi öncesinde failover modunu manuel moda almak için aşağıdaki komut kullanılmaktadır.
ALTER AVAILABILITY GROUP [AG_NAME] SET (FAILOVER_MODE = MANUAL);Failover öncesi:
- Veritabanı senkronizasyon durumunu kontrol edilmeli (SYNCHRONIZED olmalı).
- Log Send ve Redo Queue değerlerini kontrol edilmeli (Düşük olmalı).
- Backup alınması ve AlwaysOn Failover modunu manuel yapılması gerekmektedir.
Log Send Queue (KB): Bu metrik, Primary sunucuda üretilen ancak henüz Secondary sunucuya gönderilememiş olan log miktarını ifade eder. Ağ trafiği (Network) ve Primary sunucunun logları gönderme hızını tespit etmektedir.
Yüksek Olması Ne Anlama Gelir.
- Ağ band genişliği yetersizdir (Network Latency).
- Primary sunucu üzerinde çok yoğun veri girişi (Bulk Insert vb.) vardır, ağ bu hıza yetişemiyordur.
Bu değer ne kadar yüksekse, olası bir felaket anında o kadar veri kaybı (RPO) riski oluşur (özellikle Asynchronous modda).
Redo Queue (KB): Bu metrik, logların Secondary sunucuya ulaştığını ancak henüz Secondary üzerindeki veritabanına yazılmadığını (işlenmediğini) ifade eder. ldf dosyasına yazılmış ama data file’a yazılmamış işlemler.
Bu süreci biraz daha teknik detayla netleştirelim:
Failover gerçekleştiğinde, Secondary sunucu “Primary” rolünü üstlenir. Ancak veritabanını kullanıcılara açmadan önce (Online olmadan önce) şu adımı tamamlamak zorundadır:
- Redo Aşaması: Secondary sunucuya ulaşmış ama henüz veri dosyalarına (.mdf) işlenmemiş olan tüm log kayıtlarını sırasıyla uygulamak.
- Undo Aşaması: Tamamlanmamış (uncommitted) işlemleri geri almak.
Eğer Redo Queue değeriniz yüksekse (örneğin GB’larca veri bekliyorsa), veritabanı “In Recovery” veya “Pending” modunda kalır. Bu süre zarfında:
- Uygulamalar veritabanına bağlanamaz.
- Log_Reuse_Wait_Desc değeri REDO olarak görünür.
- Sistem, disk hızına (I/O) bağlı olarak bu kuyruğu eritene kadar bekletir.
Aşağıdaki script yardımıyla Secondary sunucunun primary sunucuya göre ne kadar geriden geldiğini bulabilirsiniz. 1 saat üzerinden fazla olan veritabanlarıyla ilgili kayıt dönmektedir. Aşağıdaki dönen ilgili veritabanları yukarıdaki komut ile kordineli çalıştırdığımızda mantık anlaşılıyor.
SELECT DB_NAME(drs.database_id) AS Database_Name
,drs.last_commit_time AS Primary_Commit
,drs2.last_commit_time AS Secondary_Commit
,CONCAT(DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time)/3600 ,' Saat'
,(DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time)%3600)/60 ,' Dakika'
,DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time)%60 ,' Saniye') AS Senkronizasyon_Farki
FROM sys.dm_hadr_database_replica_states drs
JOIN sys.dm_hadr_database_replica_states drs2 ON drs.database_id=drs2.database_id
WHERE drs.is_local=1 AND drs2.is_local=0 AND DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time)>3600
ORDER BY DATEDIFF(second,drs2.last_commit_time,drs.last_commit_time) DESC
Not: Secondary sunucusu not sychronizing durumuna geçerse resume komutu çalışmazsa primaryden çok küçük bir veritabını ag’den çıkarıp join only’le tekrar ag altına alınırsa secondary sunucusu sychronizing durumuna geçmektedir
Not: Always On yapılarında, Primary sunucusundaki veritabanı üzerinde yapılan her işlem (INSERT, UPDATE, DELETE, REBUILD vb.), Transaction Log (LDF) dosyasına LSN (Log Sequence Number) değeriyle sırayal kaydedilir. Büyük bir Index Rebuild işlemi başlatıldığında, bu işlem de kendine ait LSN değerleriyle log dosyasına yazılır. Log yapısının doğal işleyişi bu sıralamaya dayanır. Ancak bir Rebuild işlemi devam ederken veritabanı üzerinde eş zamanlı olarak diğer kullanıcıların yaptığı işlemler de LDF dosyasına yeni LSN değerleriyle yazılmaya devam eder. Rebuild işlemi çok sayıda LSN kaydı oluşturur ve bu kayıtlar tamamlanmadan ilgili log blokları “aktif” statüsünde kalır. SQL Server’da log yedeği (Log Backup) alınsa dahi, devam eden Rebuild işlemine ait LSN kayıtları henüz “truncate” edilemez. Çünkü SQL Server, bir işlemin (transaction) tamamen bitip logun güvenli bir şekilde yedeklendiğinden veya Secondary sunucuya gönderildiğinden emin olmadan o alanı boşaltmaz. Bu durum, Rebuild işlemi bitene kadar logun büyümesine ve Secondary sunucuya aktarılması gereken verinin birikmesine neden olur. Rebuild gibi yoğun işlemler bitmeden arkasından gelen diğer küçük işlemler (yeni loglar) Secondary sunucuya yansıyamaz veya yansısa bile “redo” süreci Rebuild işleminin bitmesini beklediği için kuyrukta kalır. Bu sebeple Secondary sunucuda 1-2 günlük veya daha uzun süreli veri gecikmeleri (redo queue) görülebilir. Rebuild işlemi tamamen bitip loglar Secondary tarafında işlenene kadar senkronizasyon tam anlamıyla tamamlanmaz.
Başka bir makalede görüşmek dileğiyle..
“Onlar inanmışlar, kalpleri Allah’ı anmakla huzura kavuşmuştur. Dikkat edin, kalpler ancak Allah’ı anmakla huzura kavuşur. “ Ra’d Suresi; 28. Ayet