
SQL Server, diskteki verilere erişim hızını artırmak için verileri bellek üzerindeki Buffer Pool adı verilen alanda saklar. Bir sorgu çalıştırıldığında, veri önce diskten okunur ve belleğe alınır; eğer veri zaten bellekteyse (“Buffer Hit”), disk I/O maliyetinden kurtulunur. Ancak sınırlı bellek kaynaklarının hangi veritabanı veya hangi tablo tarafından işgal edildiğini bilmek, performans darboğazlarını teşhis etmek için kritiktir. Bu makalede, SQL Server’ın bellek kullanımını hem genel veritabanı ölçeğinde hem de spesifik nesne (tablo/index) düzeyinde nasıl analiz edeceğimizi inceleyeceğiz.
İlk olarak, toplam Buffer Pool kapasitesinin veritabanları arasında nasıl paylaştırıldığını görmektir. Bu, hangi veritabanının sunucu kaynaklarını daha yoğun kullandığını anlamamıza yardımcı olur.
DECLARE @total_buffer INT;
SELECT @total_buffer = cntr_value
FROM sys.dm_os_performance_counters
WHERE RTRIM([object_name]) LIKE '%Buffer Manager'
AND counter_name = 'Database Pages';
;WITH DBBuffer AS
(
SELECT database_id,
COUNT_BIG(*) AS db_buffer_pages,
SUM (CAST ([free_space_in_bytes] AS BIGINT)) / (1024 * 1024) AS [MBEmpty]
FROM sys.dm_os_buffer_descriptors
GROUP BY database_id
)
SELECT
CASE [database_id] WHEN 32767 THEN 'Resource DB' ELSE DB_NAME([database_id]) END AS 'db_name',
db_buffer_pages AS 'db_buffer_pages',
db_buffer_pages / 128 AS 'db_buffer_Used_MB',
[mbempty] AS 'db_buffer_Free_MB',
CONVERT(DECIMAL(6,3), db_buffer_pages * 100.0 / @total_buffer) AS 'db_buffer_percent'
FROM DBBuffer
ORDER BY db_buffer_Used_MB DESC;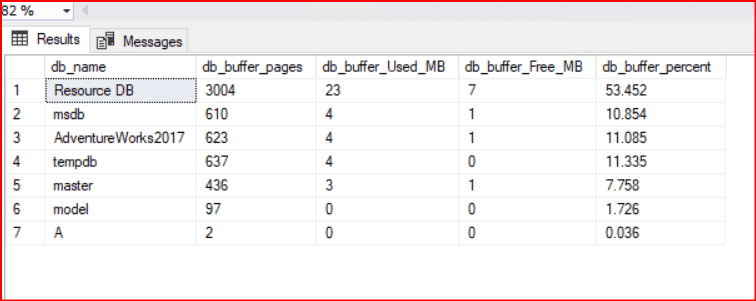
- db_name: Bellekte veri tutan veritabanının adı. 32767 ID’li veritabanı, SQL Server’ın kendi iç sistem kayıtlarını tuttuğu Resource DB’dir.
- db_buffer_pages: Veritabanının bellek üzerinde tuttuğu toplam 8 KB’lık sayfa sayısı.
- db_buffer_Used_MB: Bu sayfaların megabayt (MB) cinsinden toplam boyutu. (Sayfa sayısı / 128 formulü ile hesaplanır).
- db_buffer_Free_MB: Bellekteki sayfaların içinde bulunan ancak veriyle dolu olmayan boş alan miktarıdır. Bu değerin yüksek olması, sayfa doluluk oranlarının düşük olduğunu gösterebilir.
- db_buffer_percent: İlgili veritabanının, toplam Buffer Pool içindeki yüzde kaçlık bir paya sahip olduğunu gösterir.
Veritabanı düzeyinde analizi yaptıktan sonra, o veritabanı içindeki hangi tablonun veya index’in en çok yeri kapladığını belirlemek gerekir. Bu, gereksiz indexlerin veya çok büyük tabloların bellek üzerindeki baskısını tespit etmemizi sağlar.
SELECT fg.name AS [Filegroup Name], SCHEMA_NAME(o.Schema_ID) AS [Schema Name],
OBJECT_NAME(p.[object_id]) AS [Object Name], p.index_id,
CAST(COUNT(*)/128.0 AS DECIMAL(10, 2)) AS [Buffer size(MB)],
COUNT(*) AS [BufferCount], p.[Rows] AS [Row Count],
p.data_compression_desc AS [Compression Type]
FROM sys.allocation_units AS a WITH (NOLOCK)
INNER JOIN sys.dm_os_buffer_descriptors AS b WITH (NOLOCK)
ON a.allocation_unit_id = b.allocation_unit_id
INNER JOIN sys.partitions AS p WITH (NOLOCK)
ON a.container_id = p.hobt_id
INNER JOIN sys.objects AS o WITH (NOLOCK)
ON p.object_id = o.object_id
INNER JOIN sys.database_files AS f WITH (NOLOCK)
ON b.file_id = f.file_id
INNER JOIN sys.filegroups AS fg WITH (NOLOCK)
ON f.data_space_id = fg.data_space_id
WHERE b.database_id = CONVERT(int, DB_ID())
AND p.[object_id] > 100
AND OBJECT_NAME(p.[object_id]) NOT LIKE N'plan_%'
AND OBJECT_NAME(p.[object_id]) NOT LIKE N'sys%'
AND OBJECT_NAME(p.[object_id]) NOT LIKE N'xml_index_nodes%'
GROUP BY fg.name, o.Schema_ID, p.[object_id], p.index_id,
p.data_compression_desc, p.[Rows]
ORDER BY [BufferCount] DESC OPTION (RECOMPILE);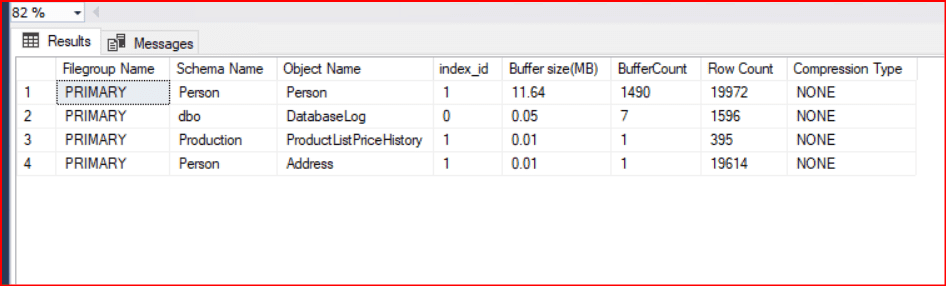
- Filegroup Name: Verinin fiziksel olarak hangi dosya grubunda saklandığı yer.
- Schema Name / Object Name: Verinin ait olduğu şema ve tablo/view adı.
- index_id: Nesnenin ID’si. 0 ise Heap (indexsiz tablo), 1 ise Clustered Index, >1 ise Non-Clustered Index’tir.
- Buffer size(MB): İlgili nesnenin şu anda RAM üzerinde kapladığı alan.
- BufferCount: Bellekteki toplam sayfa sayısı.
- Row Count: Tablodaki veya indexteki toplam satır sayısı.
- Compression Type: Verinin sıkıştırılıp sıkıştırılmadığını (NONE, PAGE, ROW) gösterir. Sıkıştırılmış veriler bellekte daha az yer kaplar.
Bellek kullanımını bu iki seviyede izlemek, veritabanı yöneticilerine (DBA) iki büyük avantaj sağlar:
- Hangi veritabanının sunucuya daha fazla RAM eklenmesi gerektiğini tetiklediğini belirlemek.
- Bellekte çok yer kaplayan ancak nadir kullanılan indexleri tespit ederek silmek veya çok büyük tablolar için veri sıkıştırma (Data Compression) stratejileri geliştirmek.
Unutulmamalıdır ki, bir tablonun bellekte çok yer kaplaması her zaman kötü değildir; ancak bu veriler “kirli” (dirty) ise veya sık kullanılmıyorsa, sistemin genel performansını olumsuz etkileyebilir.
Başka makalede görüşmek dileğiyle..
“Böyle birine âyetlerimiz okunduğunda sanki kulaklarında ağırlık varmış da onu işitemiyormuş gibi büyüklük taslayarak sırt çevirir. Ona acıklı bir azabı müjdele!”Lokman-7