
DISTINCT komutu, T-SQL’de bir sorgu sonucunda dönen verilerde yinelenen (tekrar eden) satırları ortadan kaldırmak için kullanılır. Bu komut, benzersiz (unique) değerlerin elde edilmesini sağlar. Kısacası birden fazla tekrar eden kayıt sayısının tek bir değere dönüştürülmesine yardımcı olur.
Aşağıdaki sorgumuzda tablomuzdaki tüm isimleri çağırıyoruz. Tablomuzun ilk çağrıldığında zaman gelen satır sayısı aşağıdaki resimde görülmektedir.
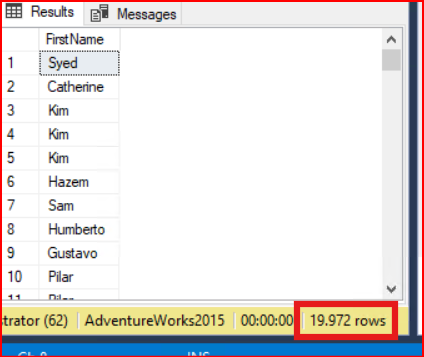
Yukarıdaki sorgumuzda tekrar eden kayıtları önlemek için distinct ifadesini kullanalım. Distinct komutu ardından gelen tüm kolonları kapsamaktadır. Birlikte oluşturulan kolonları benzersiz olmasını sağlar.
select distinct FirstName from person.Person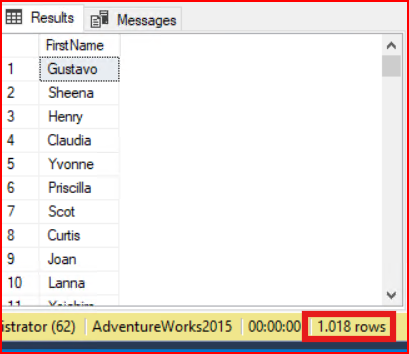
Birden fazla kolon için distinct komutu çalıştırılabilir. Aşağıdaki komut ile tabloda çağırdığımız her sütünların grup şeklinde benzersiz olanlarını getirmektedir. Yani Değer1 ve Değer2 kolonlarını bir görüyormuş gibi karar vermektedir. Örnek olarak ilk kolon yunus ikinci kolon yücel diğer satırın ilk kolonu yunus ikinci kolonu yıldırım olarak geçerse bu iki ifade benzersizdir.
SELECT DISTINCT Deger1, Deger2 FROM TableNameNULL değerler de DISTINCT tarafından işlenir ve tek bir NULL olarak gruplanır. DISTINCT performansı etkileyebilir, büyük tablolarda dikkatli kullanılmalıdır. GROUP BY ile benzer sonuçlar elde edilebilir, ancak DISTINCT daha basit senaryolar için uygundur. DISTINCT yalnızca yinelenen satırları kaldırır. GROUP BY ise verileri gruplar ve agregat fonksiyonlarla (COUNT, SUM, AVG vb.) kullanılabilir.
DISTINCT komutu, veri analizinde özellikle hangi farklı değerlerin var olduğunu görmek istediğiniz durumlarda oldukça kullanışlıdır. Başka bir makalede görüşmek dileğiyle..
“Allah, kuluna yetmez mi?”-Zümer Suresi; 36. Ayet