
Veritabanı yöneticileri ve geliştiricileri için bir sorgunun ne kadar sürede bittiği kadar, bu sürenin ne kadarının işlemci (CPU) üzerinde harcandığı da kritiktir. SQL Server’da SET STATISTICS TIME ON komutuyla görebildiğimiz bu iki metrik arasındaki fark, sistemdeki kaynağın nasıl kullanıldığını fısıldar.
- CPU Time: Sorgunun aktif olarak işlemciyi kullandığı süredir. Sadece hesaplama, veri işleme ve sıralama gibi CPU gerektiren işlerin toplamını ifade eder. Paralel planlarda (birden fazla core kullanımı), her çekirdeğin harcadığı sürenin toplamıdır.
- Elapsed Time (Geçen Süre): Sorgunun çalıştırıldığı an ile sonuçlandığı an arasındaki toplam süredir (saat üzerindeki süre). Bu süreye diskten veri okunması (I/O), ağ gecikmeleri ve diğer kaynakların (lock vb.) beklenmesi dahildir.
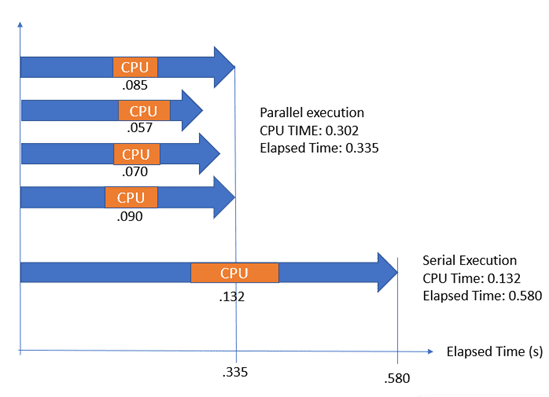
Eğer CPU süresi, toplam geçen süreden çok daha fazlaysa (örneğin CPU: 1000ms, Elapsed: 300ms), sorgunuz paralel çalışıyor demektir. Bu genellikle iyidir, ancak aşırı paralellik “CXPACKET” beklemelerine ve işlemci darboğazına yol açabilir.
- Bu gibi durumda MAXDOP (Maximum Degree of Parallelism) ayarlarını ve Cost Threshold for Parallelism değerini gözden geçirin.
Eğer geçen süre, CPU süresinden çok fazlaysa (örneğin CPU: 50ms, Elapsed: 2000ms), sorgu işlemci dışında bir şey bekliyordur.
- I/O Beklemesi: Veri diskten okunuyordur (Eksik index veya bellek yetersizliği).
- Blocking: Başka bir sorgu ilgili tabloyu kilitlemiştir.
- Network: Büyük miktarda veri istemciye transfer ediliyordur.
- Ne Yapılmalı: Wait Types (bekleme türleri) incelenmeli, eksik index’ler oluşturulmalı ve disk performansı kontrol edilmelidir.
Hem CPU hem de Elapsed süresi yüksekse, sorgu hem ağır hesaplama yapıyordur hem de büyük veri setlerini tarıyordur.
- Bu gibi durumda sorgu mantığı optimize edilmeli, Implicit Conversion (gizli veri tipi dönüşümü) olup olmadığı kontrol edilmeli ve Search SARGability kurallarına uyulmalıdır.
Örnek 1: Index Eksikliği (I/O Bound)
Bir tabloda 10 milyon satır var ve index olmayan bir kolon üzerinden filtreleme yapıyorsunuz.
- Çıktı: CPU: 200ms, Elapsed: 5000ms.
- Neden: SQL Server diskten milyonlarca sayfayı belleğe okumak zorunda kaldı. İşlemci çok yorulmadı ama disk hızı ve veri okuma süreci zaman aldı.
- Çözüm: Filtrelenen kolona bir Non-Clustered Index eklemek.
Örnek 2: Karmaşık Hesaplamalar (CPU Bound)
Sorgu içinde milyonlarca satır üzerinde SUBSTRING, REPLACE veya ağır matematiksel fonksiyonlar kullanılıyor.
- Çıktı: CPU: 4000ms, Elapsed: 4200ms.
- Neden: Veri muhtemelen bellektedir (I/O beklemesi az) ancak işlemci her satır için bu fonksiyonları çalıştırmakla meşguldür.
- Çözüm: Hesaplamaları önceden yapılmış olarak Computed Column (Hesaplanmış Kolon) şeklinde tutmak veya uygulama tarafına taşımak.
Özet
| Durum | Olası Sorun | İlk Adım |
| Elapsed > CPU | Disk I/O, Lock (Kilitleme), Network | Index ekle, Execution Plan bak |
| CPU > Elapsed | Yoğun Paralellik | MAXDOP ayarını kontrol et |
| Düşük CPU / Düşük Elapsed | İdeal Durum | Optimizasyona gerek yok |
Bu metrikleri düzenli olarak takip etmek, donanım satın almak yerine mevcut kaynakları en verimli şekilde kullanmanıza olanak tanır.
Bilesiniz ki Kalpler Ancak Allah’ı Anmakla Huzur Bulur. Rad-28